
This article was updated in April 2024.
Let's assume that you don't know anything about continuous integration (CI) and why it's needed in the software development lifecycle.
Imagine that you work on a project, where all the code consists of two text files. Moreover, it is super critical that the concatenation of these two files contains the phrase "Hello, world."
If it's not there, the whole development team won't get paid that month. Yeah, it is that serious!
The most responsible software developer wrote a small script to run every time we are about to send our code to customers.
The code is pretty sophisticated:
cat file1.txt file2.txt | grep -q "Hello world"
The problem is that there are 10 developers on the team, and, you know, human factors can hit hard.
A week ago, a new guy forgot to run the script and three clients got broken builds. So you decided to solve the problem once and for all. Luckily, your code is already on GitLab, and you remember that there is built-in CI. Moreover, you heard at a conference that people use CI to run tests...
Let's run our first test inside CI
After taking a couple of minutes to find and read the docs, it seems like all we need is these two lines of code in a file called .gitlab-ci.yml:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
We commit it, and hooray! Our build is successful:

Let's change "world" to "Africa" in the second file and check what happens:

The build fails as expected!
OK, we now have automated tests here! GitLab CI will run our test script every time we push new code to the source code repository in the DevOps environment.
Note: In the above example, we assume that file1.txt and file2.txt exist in the runner host.
To run this example in GitLab, use the below code that first will create the files and then run the script.
test:
before_script:
- echo "Hello " > | tr -d "\n" | > file1.txt
- echo "world" > file2.txt
script: cat file1.txt file2.txt | grep -q 'Hello world'
For the sake of compactness, we will assume that these files exist in the host, and will not create them in the following examples.
Make results of builds downloadable
The next business requirement is to package the code before sending it to our customers. Let's automate that part of the software development process as well!
All we need to do is define another job for CI. Let's name the job "package":
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > package.gz
We have two tabs now:
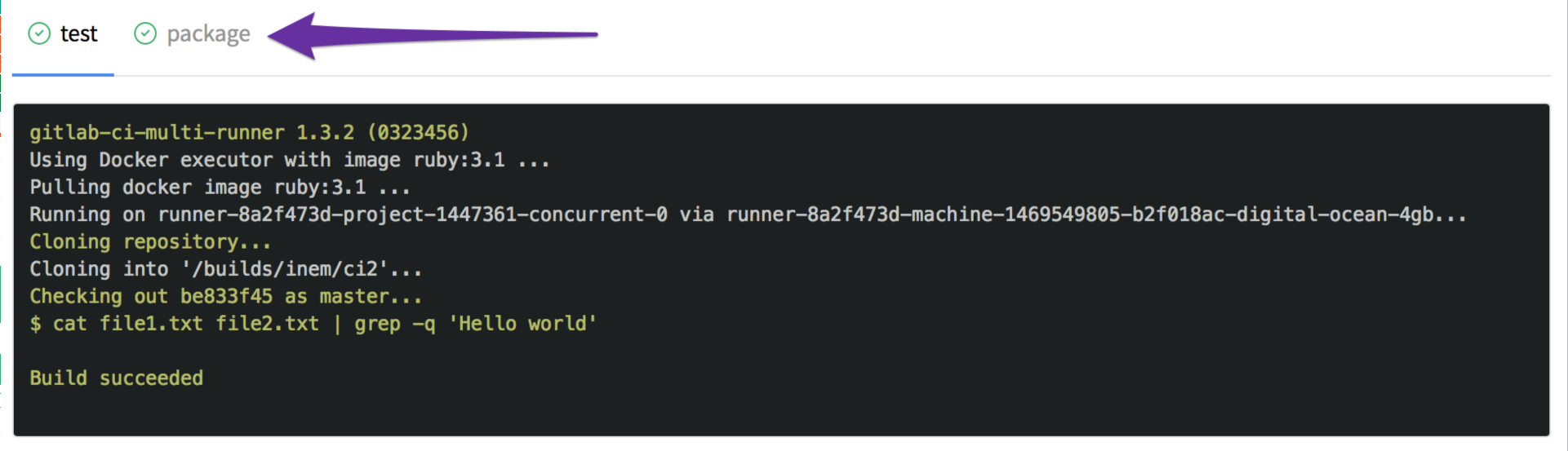
However, we forgot to specify that the new file is a build artifact, so that it could be downloaded. We can fix it by adding an artifacts section:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
Checking... it is there:
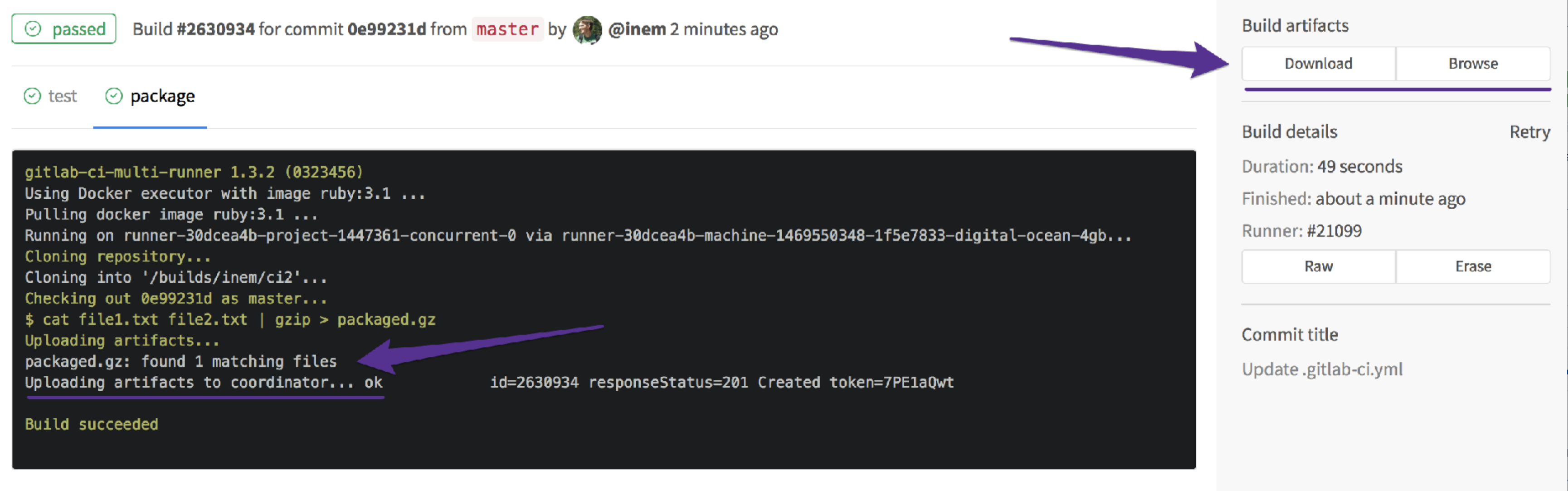
Perfect, it is! However, we have a problem to fix: The jobs are running in parallel, but we do not want to package our application if our tests fail.
Run jobs sequentially
We only want to run the 'package' job if the tests are successful. Let's define the order by specifying stages:
stages:
- test
- package
test:
stage: test
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
stage: package
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
That should be good!
Also, we forgot to mention, that compilation (which is represented by concatenation in our case) takes a while, so we don't want to run it twice. Let's define a separate step for it:
stages:
- compile
- test
- package
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
package:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
Let's take a look at our artifacts:

Hmm, we do not need that "compile" file to be downloadable. Let's make our temporary artifacts expire by setting expire_in to '20 minutes':
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutes
Now our config looks pretty impressive:
- We have three sequential stages to compile, test, and package our application.
- We pass the compiled app to the next stages so that there's no need to run compilation twice (so it will run faster).
- We store a packaged version of our app in build artifacts for further usage.
Learning which Docker image to use
So far, so good. However, it appears our builds are still slow. Let's take a look at the logs.
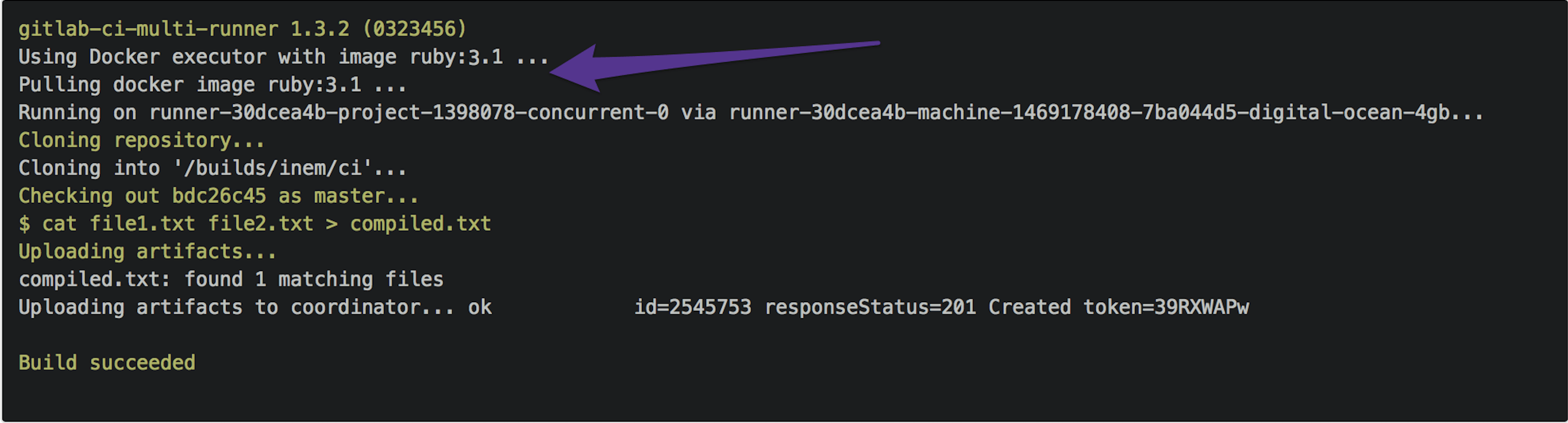
Wait, what is this? Ruby 3.1?
Why do we need Ruby at all? Oh, GitLab.com uses Docker images to run our builds, and by default it uses the ruby:3.1 image. For sure, this image contains many packages we don't need. After a minute of Googling, we figure out that there's an image called alpine, which is an almost blank Linux image.
OK, let's explicitly specify that we want to use this image by adding image: alpine to .gitlab-ci.yml.
Now we're talking! We shaved nearly three minutes off:

It looks like there are a lot of public images around:
So we can just grab one for our technology stack. It makes sense to specify an image that contains no extra software because it minimizes download time.
Dealing with complex scenarios
So far, so good. However, let's suppose we have a new client who wants us to package our app into .iso image instead of .gz. Since CI does all the work, we can just add one more job to it. ISO images can be created using the mkisofs command. Here's how our config should look:
image: alpine
stages:
- compile
- test
- package
# ... "compile" and "test" jobs are skipped here for the sake of compactness
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
script:
- mkisofs -o ./packaged.iso ./compiled.txt
artifacts:
paths:
- packaged.iso
Note that job names shouldn't necessarily be the same. In fact, if they were the same, it wouldn't be possible to make the jobs run in parallel inside the same stage of the software development process. Hence, think of same names of jobs and stages as coincidence.
Anyhow, the build is failing:

The problem is that mkisofs is not included in the alpine image, so we need to install it first.
Dealing with missing software/packages
According to the Alpine Linux website mkisofs is a part of the xorriso and cdrkit packages. These are the magic commands that we need to run to install a package:
echo "ipv6" >> /etc/modules # enable networking
apk update # update packages list
apk add xorriso # install package
For CI, these are just like any other commands. The full list of commands we need to pass to script section should look like this:
script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
- mkisofs -o ./packaged.iso ./compiled.txt
However, to make it semantically correct, let's put commands related to package installation in before_script. Note that if you use before_script at the top level of a configuration, then the commands will run before all jobs. In our case, we just want it to run before one specific job.
Directed Acyclic Graphs: Get faster and more flexible pipelines
We defined stages so that the package jobs will run only if the tests passed. What if we want to break the stage sequencing a bit, and run a few jobs earlier, even if they are defined in a later stage? In some cases, the traditional stage sequencing might slow down the overall pipeline execution time.
Imagine that our test stage includes a few more heavy tests that take a lot of time to execute, and that those tests are not necessarily related to the package jobs. In this case, it would be more efficient if the package jobs don't have to wait for those tests to complete before they can start. This is where Directed Acyclic Graphs (DAG) come in: To break the stage order for specific jobs, you can define job dependencies which will skip the regular stage order.
GitLab has a special keyword needs, which creates dependencies between jobs, and allows jobs to run earlier, as soon as their dependent jobs complete.
In the below example, the pack jobs will start running as soon as the test job completes, so if, in future, someone adds more tests in the test stage, the package jobs will start to run before the new test jobs complete:
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
needs: ["test"]
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
before_script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
script:
- mkisofs -o ./packaged.iso ./compiled.txt
needs: ["test"]
artifacts:
paths:
- packaged.iso
Our final version of .gitlab-ci.yml:
image: alpine
stages:
- compile
- test
- package
compile:
stage: compile
before_script:
- echo "Hello " | tr -d "\n" > file1.txt
- echo "world" > file2.txt
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutes
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
needs: ["test"]
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
before_script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
script:
- mkisofs -o ./packaged.iso ./compiled.txt
needs: ["test"]
artifacts:
paths:
- packaged.iso
Wow, it looks like we have just created a pipeline! We have three sequential stages, the jobs pack-gz and pack-iso, inside the package stage, are running in parallel:

Elevating your pipeline
Here is how to elevate your pipeline.
Incorporating automated testing into CI pipelines
In DevOps, a key software development strategy rule is making really great apps with amazing user experience. So, let's add some tests in our CI pipeline to catch bugs early in the entire process. This way, we fix issues before they get big and before we move on to work on a new project.
GitLab makes our lives easier by offering out-of-the-box templates for various tests. All we need to do is include these templates in our CI configuration.
In this example, we will include accessibility testing:
stages:
- accessibility
variables:
a11y_urls: "https://about.gitlab.com https://www.example.com"
include:
- template: "Verify/Accessibility.gitlab-ci.yml"
Customize the a11y_urls variable to list the URLs of the web pages to test with Pa11y and code quality.
include:
- template: Jobs/Code-Quality.gitlab-ci.yml
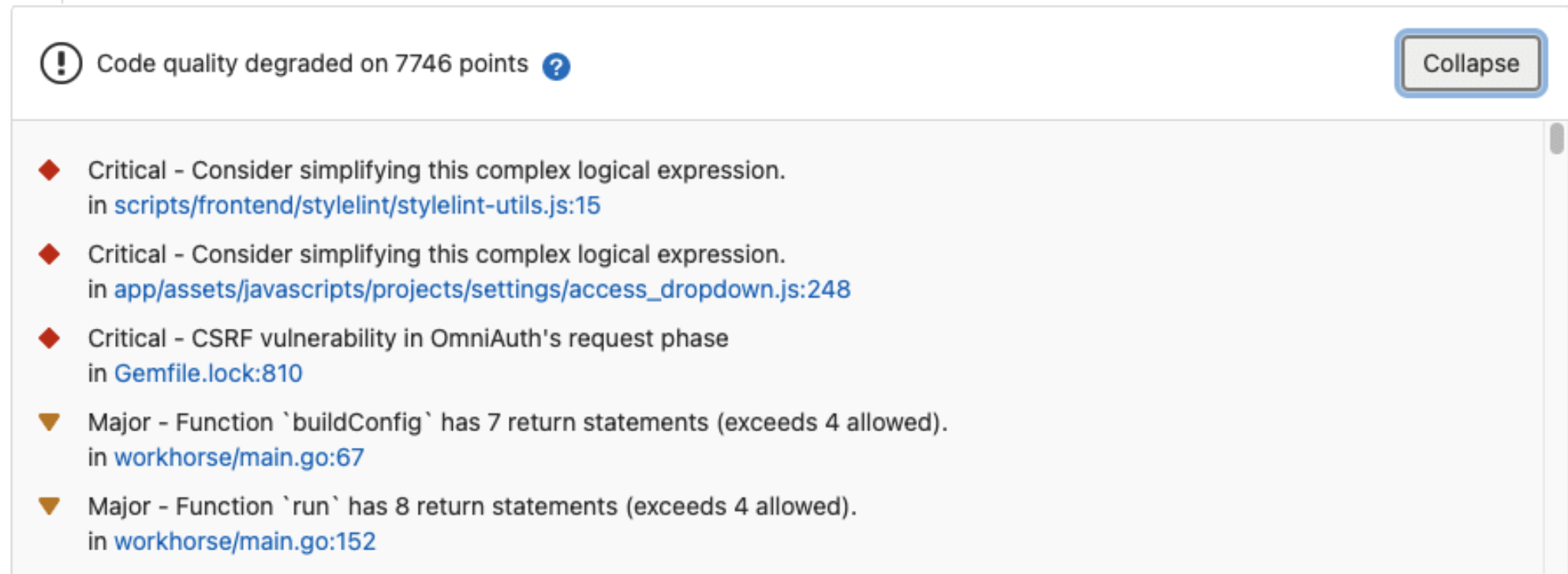
GitLab makes it easy to see the test report right in the merge request widget area. Having the code review, pipeline status, and test results in one spot makes everything smoother and more efficient.

Matrix builds
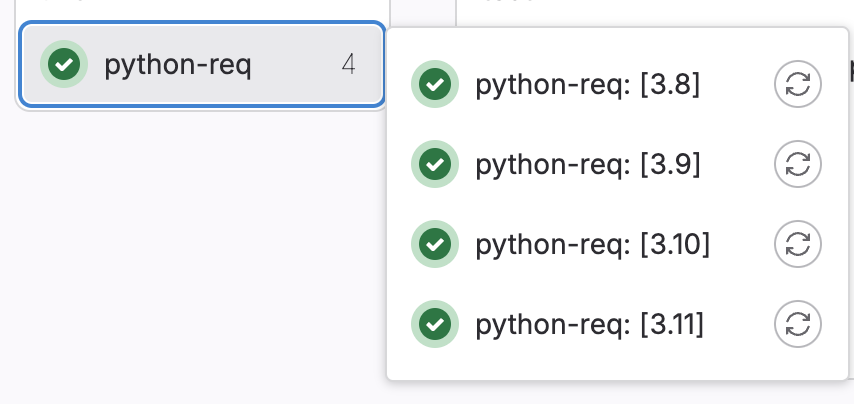
In some cases, we will need to test our app in different configurations, OS versions, programming language versions, etc. For those cases, we'll use the parallel:matrix build to test our application across various combinations in parallel using one job configuration. In this blog, we'll test our code with different Python versions using the matrix keyword.
python-req:
image: python:$VERSION
stage: lint
script:
- pip install -r requirements_dev.txt
- chmod +x ./build_cpp.sh
- ./build_cpp.sh
parallel:
matrix:
- VERSION: ['3.8', '3.9', '3.10', '3.11'] # https://hub.docker.com/_/python
During pipeline execution, this job will run in parallel four times, each time using different Python image as shown below:
Unit testing
What are unit tests?
Unit tests are small, targeted tests that check individual components or functions of software to ensure they work as expected. They are essential for catching bugs early in the software development process and verifying that each part of the code performs correctly in isolation.
Example: Imagine you're developing a calculator app. A unit test for the addition function would check if 2 + 2 equals 4. If this test passes, it confirms that the addition function is working correctly.
Unit testing best practices
If the tests fail, the pipeline fails and users get notified. The developer needs to check the job logs, which usually contain thousands of lines, and see where the tests failed so that they can fix them. This check is time-consuming and inefficient.
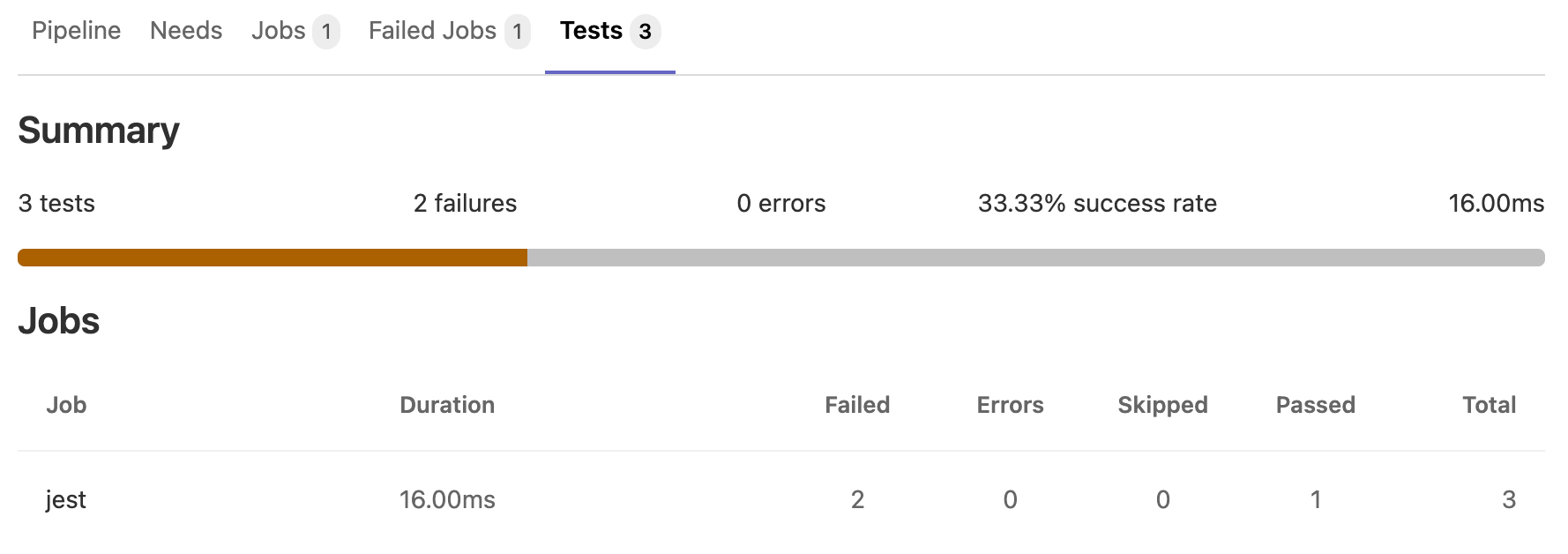
You can configure your job to use unit test reports. GitLab displays reports on the merge request and on the pipelines details page, making it easier and faster to identify the failure without having to check the entire log.
junit test report
This is a sample junit test report:
Integration and end-to-end testing strategies
In addition to our regular development routine, it's super important to set up a special pipeline just for integration and end-to-end testing. This checks that all the different parts of our code work together smoothly, including those microservices, UI testing, and any other components.
We run these tests nightly. We can set it up so that the results automatically get sent to a special Slack channel. This way, when developers come in the next day, they can quickly spot any issues. It's all about catching and fixing problems early on!
Test environment
For some of the tests, we may need a test environment to properly test our apps. With GitLab CI/CD, we can automate the deployment of testing environments and save a ton of time. Since this blog mostly focuses on CI, I won't elaborate on this, but you can refer to this section in the GitLab documentation.
Implementing security scans in CI pipelines
Here are the ways to implement security scans in CI pipelines.
SAST and DAST integration
We're all about keeping our code safe. If there are any vulnerabilities in our latest changes, we want to know ASAP. That's why it's a good idea to add security scans to your pipeline. They'll check the code with every commit and give you a heads up about any risks. We've put together a product tour to walk you through adding scans, including static application security testing (SAST) and dynamic application security testing (DAST), to your CI pipeline.
Click the image below to start the tour.
Plus, with AI, we can dig even deeper into vulnerabilities and get suggestions on how to fix them. Check out this demo for more info.
Click the image below to start the tour.
Recap
There's much more to cover but let's stop here for now. All examples were made intentionally trivial so that you could learn the concepts of GitLab CI without being distracted by an unfamiliar technology stack. Let's wrap up what we have learned:
- To delegate some work to GitLab CI you should define one or more jobs in
.gitlab-ci.yml. - Jobs should have names and it's your responsibility to come up with good ones.
- Every job contains a set of rules and instructions for GitLab CI, defined by special keywords.
- Jobs can run sequentially, in parallel, or out of order using DAG.
- You can pass files between jobs and store them in build artifacts so that they can be downloaded from the interface.
- Add tests and security scans to the CI pipeline to ensure the quality and security of your app.
Below are more formal descriptions of the terms and keywords we used, as well as links to the relevant documentation.
Keyword descriptions and documentation
| Keyword/term | Description |
|---|---|
| .gitlab-ci.yml | File containing all definitions of how your project should be built |
| script | Defines a shell script to be executed |
| before_script | Used to define the command that should be run before (all) jobs |
| image | Defines what Docker image to use |
| stages | Defines a pipeline stage (default: test) |
| artifacts | Defines a list of build artifacts |
| artifacts:expire_in | Used to delete uploaded artifacts after the specified time |
| needs | Used to define dependencies between jobs and allows to run jobs out of order |
| pipelines | A pipeline is a group of builds that get executed in stages (batches) |
More on CI/CD
- GitLab’s guide to CI/CD for beginners
- Get faster and more flexible pipelines with a Directed Acyclic Graph
- Decrease build time with custom Docker image
- Introducing the GitLab CI/CD Catalog Beta
FAQ
How do you choose between running CI jobs sequentially vs. in parallel?
Considerations for choosing between running CI jobs sequentially or in parallel include job dependencies, resource availability, execution times, potential interference, test suite structure, and cost considerations. For example, if you have a build job that must finish before a deployment job can start, you would run these jobs sequentially to ensure the correct order of execution. On the other hand, tasks such as unit testing and integration testing can typically run in parallel since they are independent and don't rely on each other's completion.
What are directed Acyclic Graphs in GitLab CI, and how do they improve pipeline flexibility?
A Directed Acyclic Graph (DAG) in GitLab CI breaks the linear order of pipeline stages. It lets you set dependencies between jobs, so jobs in later stages start as soon as earlier stage jobs finish. This reduces overall pipeline execution time, improves efficiency, and lets some jobs complete earlier than in a regular order.
What is the importance of choosing the right Docker image for CI jobs in GitLab?
GitLab utilizes Docker images to execute jobs. The default image is ruby:3.1. Depending on your job's requirements, it's crucial to choose the appropriate image. Note that jobs first download the specified Docker image, and if the image contains additional packages beyond what's necessary, it will increase download and execution times. Therefore, it's important to ensure that the chosen image contains only the packages essential for your job to avoid unnecessary delays in execution.
Next steps
As a next step and to further modernize your software development practice, check out the GitLab CI/CD Catalog to learn how to standardize and reuse CI/CD components.

