
This post is inspired by this comment on Reddit, thanking us for improving the stability of GitLab.com. Thanks, hardwaresofton! Making GitLab.com ready for your mission-critical workloads has been top of mind for us for some time, and it's great to hear that users are noticing a difference.
Please note that the numbers in this post differ slightly from the Reddit post as the data has changed since that post.
We will continue to work hard on improving the availability and stability of the platform. Our current goal is to achieve 99.95 percent availability on GitLab.com – look out for an upcoming post about how we're planning to get there.
GitLab.com stability before and after the migration
According to Pingdom, GitLab.com's availability for the year to date, up until the migration was 99.68 percent, which equates to about 32 minutes of downtime per week on average.
Since the migration, our availability has improved greatly, although we have much less data to compare with than in Azure.
Using data publicly available from Pingdom, here are some stats about our availability for the year to date:
| Period | Mean-time between outage events |
|---|---|
| Pre-migration (Azure) | 1.3 days |
| Post-migration (GCP) | 7.3 days |
| Post-migration (GCP) excluding 1st day | 12 days |
This is great news: we're experiencing outages less frequently. What does this mean for our availability, and are we on track to achieve our goal of 99.95 percent?
| Period | Availability | Downtime per week |
|---|---|---|
| Pre-migration (Azure) | 99.68% | 32 minutes |
| Post-migration (GCP) | 99.88 % | 13 minutes |
| Target – not yet achieved | 99.95% | 5 minutes |
Dropping from 32 minutes per week average downtime to 13 minutes per week means we've experienced a 61 percent improvement in our availability following our migration to Google Cloud Platform.
Performance
What about the performance of GitLab.com since the migration?
Performance can be tricky to measure. In particular, averages are a terrible way of measuring performance, since they neglect outlying values. One of the better ways to measure performance is with a latency histogram chart. To do this, we imported the GitLab.com access logs for July (for Azure) and September (for Google Cloud Platform) into Google BigQuery, then selected the 100 most popular endpoints for each month and categorised these as either API, web, git, long-polling, or static endpoints. Comparing these histograms side-by-side allows us to study how the performance of GitLab.com has changed since the migration.
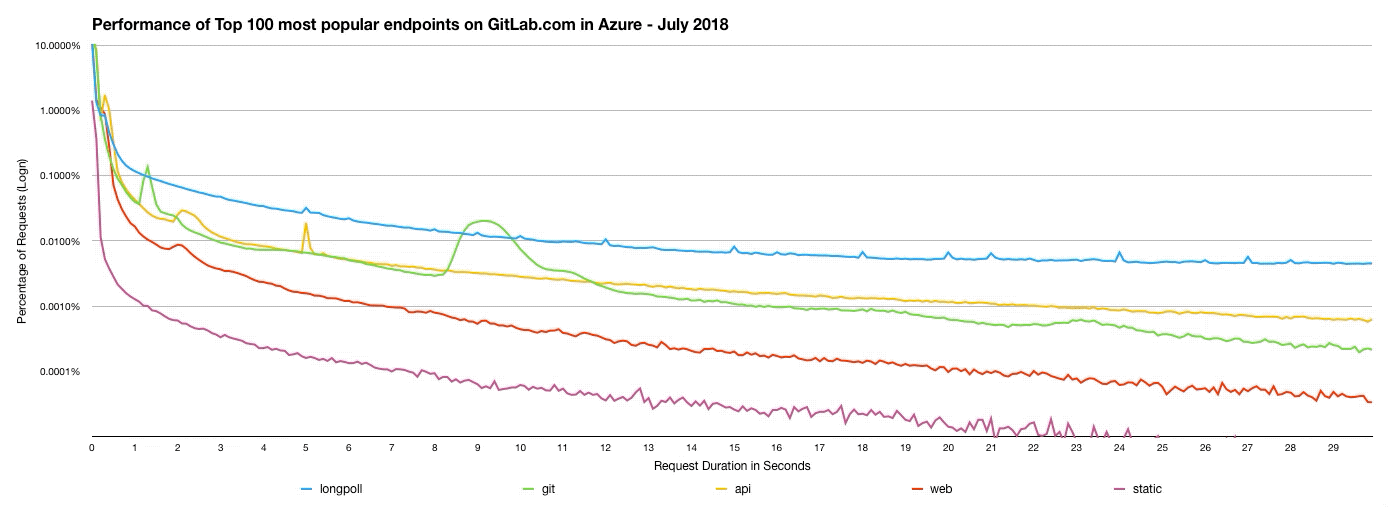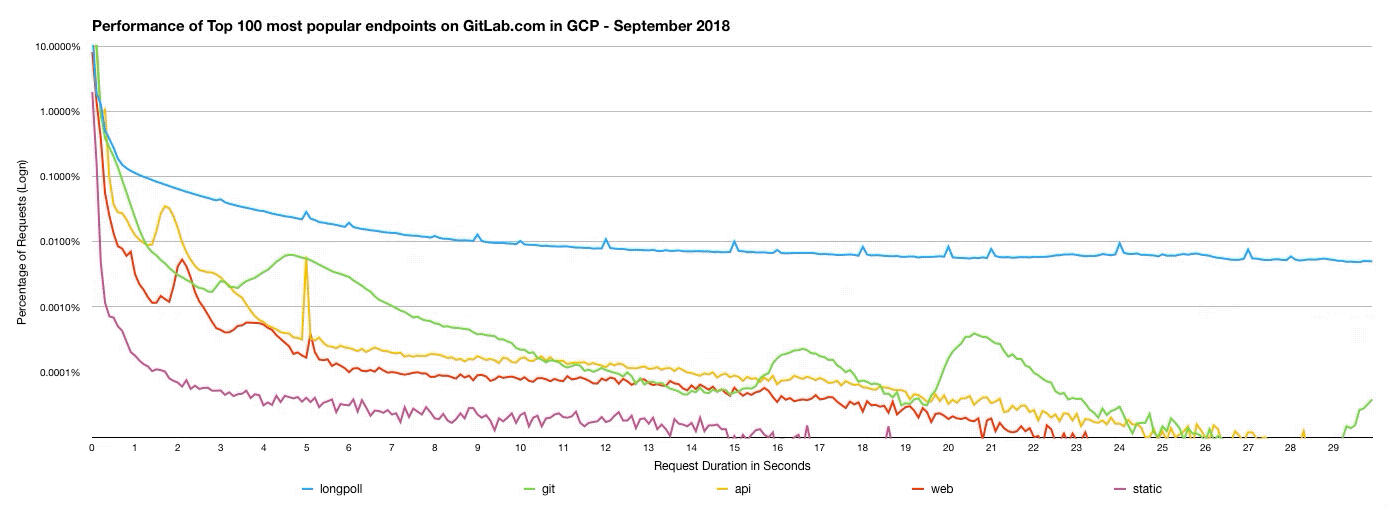
In this histogram, higher values on the left indicate better performance. The right of the graph is the "tail", and the "fatter the tail", the worse the user experience.
This graph shows us that with the move to GCP, more requests are completing within a satisfactory amount of time.
Here's two more graphs showing the difference for API and Git requests respectively.
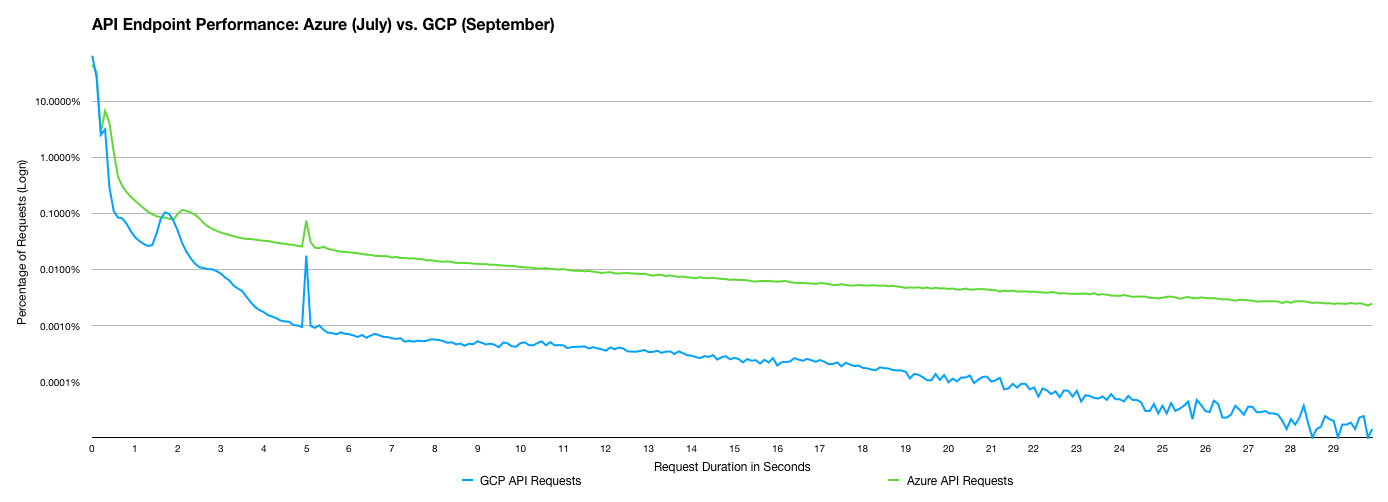
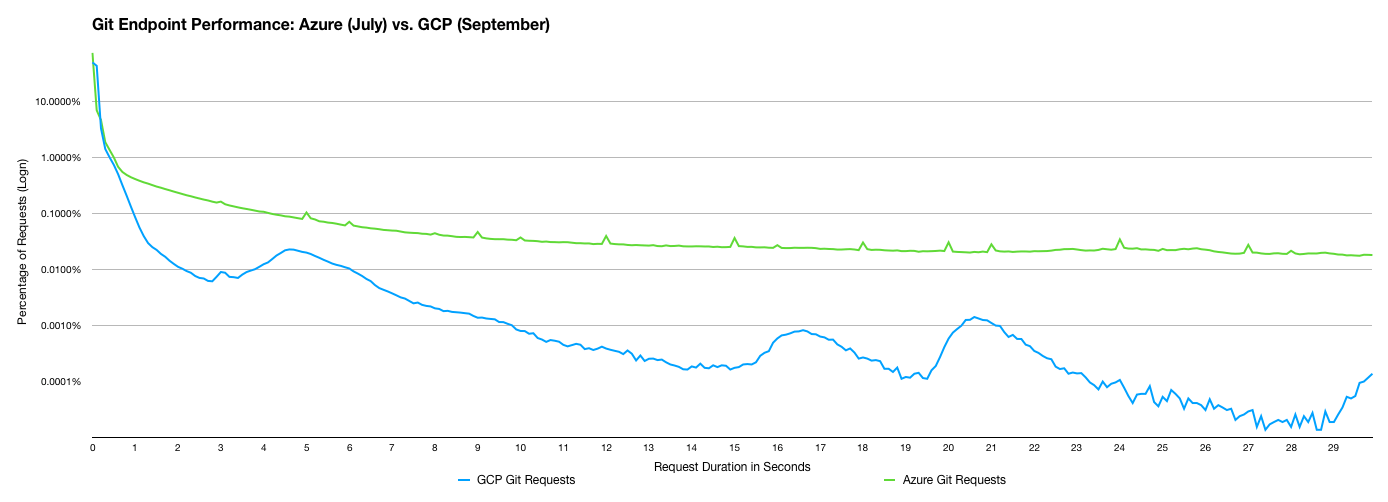
Why these improvements?
We chose Google Cloud Platform because we believe that Google offer the most reliable cloud platform for our workload, particularly as we move towards running GitLab.com in Kubernetes.
However, there are many other reasons unrelated to our change in cloud provider for these improvements to stability and performance.
“We chose Google Cloud Platform because we believe that Google offer the most reliable cloud platform for our workload”
Like any large SaaS site, GitLab.com is a large, complicated system, and attributing availability changes to individual changes is extremely difficult, but here are a few factors which may be effecting our availability and performance:
Reason #1: Our Gitaly Fleet on GCP is much more powerful than before
Gitaly is responsible for all Git access in the GitLab application. Before Gitaly, Git access occurred directly from within Rails workers. Because of the scale we run at, we require many servers serving the web application, and therefore, in order to share git data between all workers, we relied on NFS volumes. Unfortunately this approach doesn't scale well, which led to us building Gitaly, a dedicated Git service.
“We've opted to give our fleet of 24 Gitaly servers a serious upgrade”
Our upgraded Gitaly fleet
As part of the migration, we've opted to give our fleet of 24 Gitaly servers a serious upgrade. If the old fleet was the equivalent of a nice family sedan, the new fleet are like a pack of snarling musclecars, ready to serve your Git objects.
| Environment | Processor | Number of cores per instance | RAM per instance |
|---|---|---|---|
| Azure | Intel Xeon Ivy Bridge @ 2.40GHz | 8 | 55GB |
| GCP | Intel Xeon Haswell @ 2.30GHz | 32 | 118GB |
Our new Gitaly fleet is much more powerful. This means that Gitaly can respond to requests more quickly, and deal better with unexpected traffic surges.
IO performance
As you can probably imagine, serving 225TB of Git data to roughly half-a-million active users a week is a fairly IO-heavy operation. Any performance improvements we can make to this will have a big impact on the overall performance of GitLab.com.
For this reason, we've focused on improving performance here too.
| Environment | RAID | Volumes | Media | filesystem | Performance |
|---|---|---|---|---|---|
| Azure | RAID 5 (lvm) | 16 | magnetic | xfs | 5k IOPS, 200MB/s (per disk) / 32k IOPS 1280MB/s (volume group) |
| GCP | No raid | 1 | SSD | ext4 | 60k read IOPs, 30k write IOPs, 800MB/s read 200MB/s write |
How does this translate into real-world performance? Here are average read and write times across our Gitaly fleet:
IO performance is much higher
Here are some comparative figures for our Gitaly fleet from Azure and GCP. In each case, the performance in GCP is much better than in Azure, although this is what we would expect given the more powerful fleet.
Note: For reference: for Azure, this uses the average times for the week leading up to the failover. For GCP, it's an average for the week up to October 2, 2018.
These stats clearly illustrate that our new fleet has far better IO performance than our old cluster. Gitaly performance is highly dependent on IO performance, so this is great news and goes a long way to explaining the performance improvements we're seeing.
Reason #2: Fewer "unicorn worker saturation" errors
Unicorn worker saturation sounds like it'd be a good thing, but it's really not!
We (currently) rely on unicorn, a Ruby/Rack http server, for serving much of the application. Unicorn uses a single-threaded model, which uses a fixed pool of workers processes. Each worker can handle only one request at a time. If the worker gives no response within 60 seconds, it is terminated and another process is spawned to replace it.
“Unicorn worker saturation sounds like it'd be a good thing, but it's really not!”
Add to this the lack of autoscaling technologies to ramp the fleet up when we experience high load volumes, and this means that GitLab.com has a relatively static-sized pool of workers to handle incoming requests.
If a Gitaly server experiences load problems, even fast RPCs that would normally only take milliseconds, could take up to several seconds to respond – thousands of times slower than usual. Requests to the unicorn fleet that communicate with the slow server will take hundreds of times longer than expected. Eventually, most of the fleet is handling requests to that affected backend server. This leads to a queue which affects all incoming traffic, a bit like a tailback on a busy highway caused by a traffic jam on a single offramp.
If the request gets queued for too long – after about 60 seconds – the request will be cancelled, leading to a 503 error. This is indiscriminate – all requests, whether they interact with the affected server or not, will get cancelled. This is what I call unicorn worker saturation, and it's a very bad thing.
Between February and August this year we frequently experienced this phenomenon.
There are several approaches we've taken to dealing with this:
-
Fail fast with aggressive timeouts and circuitbreakers: Timeouts mean that when a Gitaly request is expected to take a few milliseconds, they time out after a second, rather than waiting for the request to time out after 60 seconds. While some requests will still be affected, the cluster will remain generally healthy. Gitaly currently doesn't use circuitbreakers, but we plan to add this, possibly using Istio once we've moved to Kubernetes.
-
Better abuse detection and limits: More often than not, server load spikes are driven by users going against our fair usage policies. We built tools to better detect this and over the past few months, an abuse team has been established to deal with this. Sometimes, load is driven through huge repositories, and we're working on reinstating fair-usage limits which prevent 100GB Git repositories from affecting our entire fleet.
-
Concurrency controls and rate limits: For limiting the blast radius, rate limiters (mostly in HAProxy) and concurrency limiters (in Gitaly) slow overzealous users down to protect the fleet as a whole.
Reason #3: GitLab.com no longer uses NFS for any Git access
In early September we disabled Git NFS mounts across our worker fleet. This was possible because Gitaly had reached v1.0: the point at which it's sufficiently complete. You can read more about how we got to this stage in our Road to Gitaly blog post.
Reason #4: Migration as a chance to reduce debt
The migration was a fantastic opportunity for us to improve our infrastructure, simplify some components, and otherwise make GitLab.com more stable and more observable, for example, we've rolled out new structured logging infrastructure.
As part of the migration, we took the opportunity to move much of our logging across to structured logs. We use fluentd, Google Pub/Sub, Pubsubbeat, storing our logs in Elastic Cloud and Google Stackdriver Logging. Having reliable, indexed logs has allowed us to reduce our mean-time to detection of incidents, and in particular detect abuse. This new logging infrastructure has also been invaluable in detecting and resolving several security incidents.
“This new logging infrastructure has also been invaluable in detecting and resolving several security incidents”
We've also focused on making our staging environment much more similar to our production environment. This allows us to test more changes, more accurately, in staging before rolling them out to production. Previously the team was maintaining a limited scaled-down staging environment and many changes were not adequately tested before being rolled out. Our environments now share a common configuration and we're working to automate all terraform and chef rollouts.
Reason #5: Process changes
Unfortunately many of the worst outages we've experienced over the past few years have been self-inflicted. We've always been transparent about these — and will continue to be so — but as we rapidly grow, it's important that our processes scale alongside our systems and team.
“It's important that our processes scale alongside our systems and team”
In order to address this, over the past few months, we've formalized our change and incident management processes. These processes respectively help us to avoid outages and resolve them quicker when they do occur.
If you're interested in finding out more about the approach we've taken to these two vital disciplines, they're published in our handbook:
Reason #6: Application improvement
Every GitLab release includes performance and stability improvements; some of these have had a big impact on GitLab's stability and performance, particularly n+1 issues.
Take Gitaly for example: like other distributed systems, Gitaly can suffer from a class of performance degradations known as "n+1" problems. This happens when an endpoint needs to make many queries ("n") to fulfill a single request.
Consider an imaginary endpoint which queried Gitaly for all tags on a repository, and then issued an additional query for each tag to obtain more information. This would result in n + 1 Gitaly queries: one for the initial tag, and then n for the tags. This approach would work fine for a project with 10 tags – issuing 11 requests, but a project with 1000 tags, this would result in 1001 Gitaly calls, each with a round-trip time, and issued in sequence.

Using data from Pingdom, this chart shows long-term performance trends since the start of the year. It's clear that latency improved a great deal on May 7, 2018. This date happens to coincide with the RC1 release of GitLab 10.8, and its deployment on GitLab.com.
It turns out that this was due to a single fix on n+1 on the merge request page being resolved.
When running in development or test mode, GitLab now detects n+1 situations and we have compiled a list of known n+1s. As these are resolved we expect even more performance improvements.

Reason #7: Infrastructure team growth and reorganization
At the start of May 2018, the Infrastructure team responsible for GitLab.com consisted of five engineers.
Since then, we've had a new director join the Infrastructure team, two new managers, a specialist Postgres DBRE, and four new SREs. The database team has been reorganized to be an embedded part of infrastructure group. We've also brought in Ongres, a specialist Postgres consultancy, to work alongside the team.
Having enough people in the team has allowed us to be able to split time between on-call, tactical improvements, and longer-term strategic work.
Oh, and we're still hiring! If you're interested, check out our open positions and choose the Infrastructure Team 😀
TL;DR: Conclusion
- GitLab.com is more stable: availability has improved 61 percent since we migrated to GCP
- GitLab.com is faster: latency has improved since the migration
- We are totally focused on continuing these improvements, and we're building a great team to do it
One last thing: our Grafana dashboards are open, so if you're interested in digging into our metrics in more detail, visit dashboards.gitlab.com and explore!

