The following page may contain information related to upcoming products, features and functionality. It is important to note that the information presented is for informational purposes only, so please do not rely on the information for purchasing or planning purposes. Just like with all projects, the items mentioned on the page are subject to change or delay, and the development, release, and timing of any products, features or functionality remain at the sole discretion of GitLab Inc.
Our Vision for the Ops section is to set up developers for efficient and safe software delivery using the best practices in CI/CD, operations and integrated security.

The Ops Section is comprised of five stages: Verify, Package, Deploy and Monitor. For a deeper view of the direction of each specific stage please visit the respective Direction Pages linked below:
Market analysts (internal) often describe these stages as automated software quality (ASQ, partially correlated with Verify, Package and Deploy), IT automation and configuration management (ITACM, correlated with Deploy), and IT operations management (ITOM, partially correlated with Monitor). The Ops section also covers CI/CD (Verify/Deploy), IT Infrastructure Monitoring/APM (Monitor), CDRA (Deploy), Infrastructure Configuration (Deploy) and Package and Binary Management (Package) analyst categories.
In some contexts, "ops" refers to operators. Operators were the counterparts to Developers represented in the original coining of the term DevOps. That definition highlighted the rift between the two groups and a need for collaboration. At GitLab, we use "ops" to mean operations - any component of the value stream delivery platform after a developer commits code. Our developer first perspective means our use of the word "ops" is focused on enabling developers to configure tools and perform operations tasks first. We have support for platform operations and SRE teams who provide Pipelines, Infrastructure and alert response tools to development teams, and ambitious plans to support traditional operators in the future.
GitLab's Ops strategy follows that of GitLab's company strategy. Just like our company mission, we will enable everyone to contribute beyond application code to other digital artifacts that increasingly define the performance, reliability, and resilience of the world's software. We will pursue that mission and capitalize on the opportunities (such as, developer buyer power, IT skills gaps, a move towards Kubernetes, and our roots in source-control and CI) by utilizing a dual-flywheel approach. This approach starts with attracting developers performing DevOps tooling and operations tasks to our Free/Core tier. As we build best of breed tools for them we will co-create to drive product improvements. This will generate revenue for higher product tiers and additional investment for supporting the modern development teams.
More specifically, we will achieve this by enabling easy-to-discover, working-by-default, workflows that support doing powerful, complex actions with a minimum configuration. We want to take advantage of our single application so that, while each team may have their own views or dashboards in the product that support their day to day, the information is available everywhere and to everyone, embedded naturally into their day-to-day workflow where it's relevant. For example:
The end result is that even complex delivery flows become part of everyone's primary way of working. There isn't a context shift (or even worse, a switch into a different tool) needed to start thinking about delivery or operations - that information is there, in context, from your first commit. The centerpiece of this strategy is our Get Things Done Easily theme.
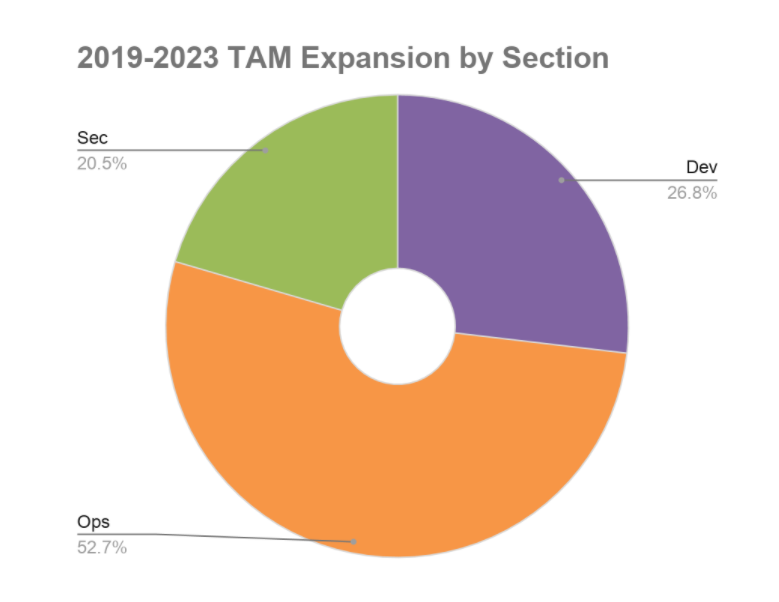
The Ops Section stages represent over 50% of GitLab's future CSM expansion. In three years the Ops market will:
Our Ops Section themes are additive to our overall Yearly Themes. In FY24, we plan to execute on:
Our plan is to continue to lean into adoption through usability and discoverability in our core stages of Verify, Package, and Deploy. This will mean sustained focus on onboarding users and organizations from SCM, to CI to Deployment.
For the Monitor stage, we will pursue our common progression product approach to breadth, namely:
As a result our performance indicators and tier strategies are aligned to the maturity of each stage.
In doing so, over the next 12 months we will choose NOT to:
The Ops Section stages are at the forefront of GitLab's single DevOps platform vision of enabling everyone to contribute. These stages represent half of GitLab's Total Addressable Market expansion during the next five years and the markets where we have some of the lowest current penetration. As a result the opportunity and impact from R&D investment in these stages are the highest in the company.
User growth in Ops Section stages improves Stages per Organization beyond typical SCM customers - providing the value of a single DevOps platform to our customers. Adding new types of users in turn increases unique active users, while adding paid tier features increases Average Revenue Per User (ARPU) and broad adoption across users in our customers' organizations increases net retention. All of these are critical drivers of our GitLab's business performance.
We would appreciate your feedback on this direction page. Please take our survey, email Jackie Porter or propose an MR to this page!
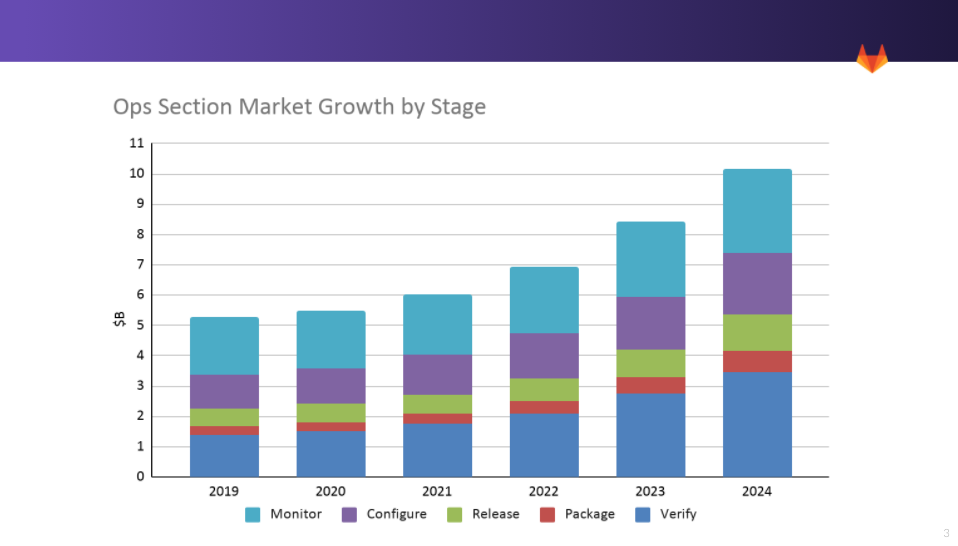
The total addressable market (TAMkt) for DevOps tools targeting these stages was $5.2B in 2019 and is expected to grow to $10.7B by 2024 (18.8% CAGR) (internal). This analysis is considered conservative as it focuses only on developers and doesn't include additional potential users. This is a deep profit pool and represents a significant portion of GitLab's expanding addressable market. As organizations further adopt DevOps, developer focused ops tools account for a larger share of market. This market has traditionally targeted IT Architects, System Admins and Operators where large hardware budgets enabled expensive IT tools to flourish.
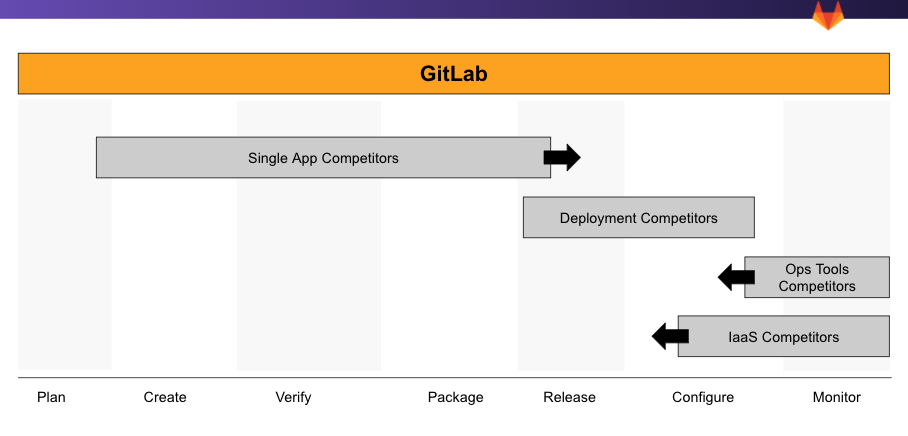
The market is well established (internal), but the participants are evolving rapidly. Existing leaders in single stages of the DevOps lifecycle are expanding to build value stream delivery platforms (internal), what GitLab calls complete DevOps platforms delivered as a single application. These existing players are doing so via acquisition and product development. The leaders run the gamut from GitHub with their strong position in the SCM market and their growing capabilities to compete in CI/CD, to Delivery focused tools such as Harness and JFrog, to Grafana, DataDog and New Relic with their strong positions in Observability and expansion into deployment and incident response. All are pivoting to pursue the value stream delivery platform market.
Despite many strong players, GitLab's market share in the Ops section is growing, especially in the Verify, Package, and Deploy stages. For Monitor, our unique perspective as a single and complete DevOps application positions us for growth.
You can see how users currently use our various stages in our Ops Section product performance indicators (internal) and Ops Section Usage Dashboard (internal).
We are continually investing in R&D in all Ops Section stages. The maturity of each stage and category can be found in our maturity page. Our investment in the Ops section stages (internal) is critical to both enabling enterprise users to continue on their DevOps maturity journey and completing our complete DevOps platform vision. Driving adoption across multiple Ops stages enables early adopters to recognize the benefit of a single application.
We face a wide range of market challenges (in priority order):
Outside of market challenges we have some internal ones as well:
Given the above challenges, there are key opportunities we must take advantage of (in priority order):
Below are some additional resources to learn more about Ops:
The performance of the Ops section is defined as the total adoption of its stages as measured by the Ops Section Total Stages Monthly Active Users (internal)) (Ops Section CMAU). Ops Section TMAU is a sum of all SMAUs across the five stages in the Ops Section (Verify, Package, Deploy & Monitor).
To increase the Ops Section TMAU, the product groups are focused on driving their stage adoption. We are especially focused on increasing adoption of the Verify and Deploy stages by driving CI usage from existing SCM users and driving CD usage from existing CI users. This will activate users into Ops Section TMAU and enable them to continue to adopt other Ops section stages as described on Ops section adoption journey (see also the product-wide adoption journey):
The majority of our Ops section product groups are focused on driving adoption first, and then monetization within their category scope. Some groups are well placed to focus on monetization right away by adding tier value for buyer personas (e.g. development manager, director) on top of existing stages which already have heavy usage.
See more details about our Product Performance Indicators in our Ops Section Product Performance Indicators page.
We track our quarterly Product Performance Indicator goals in our internal handbook page. We track our long-term Product Performance Indicator goals here.
We identify the personas the Ops section features are built for. In order to be transparent about personas we support today and personas we aim to support in the future we use the following categorization of personas listed in priority order.
To capitalize on the opportunities listed above, the Ops section has features that make it useful to the following personas today.
As we execute our 3-year strategy, our medium term (1-2 year) goal is to provide a single application that enables collaboration between cloud native development and platform teams.