Incident Management
If you’re a GitLab team member and are looking to alert Reliability Engineering about an availability issue with GitLab.com, please find quick instructions to report an incident here:
Reporting an Incident.
If you’re a GitLab team member looking for who is currently the Engineer On Call (EOC), please see the
Who is the Current EOC? section.
If you’re a GitLab team member looking for the status of a recent incident, please see the incident
board. For detailed information about incident status changes, please see the
Incident Workflow section.
Incident Management
Incidents are anomalous conditions that result in—or may lead
to—service degradation or outages. These events require human
intervention to avert disruptions or restore service to operational status.
Incidents are always given immediate attention.
The goal of incident management is to organize chaos into swift incident
resolution. To that end, incident management provides:
- well-defined roles and responsibilities and workflow for members of the incident team,
- control points to manage the flow information and the resolution path,
- an incident review where lessons and techniques are extracted and shared
When an incident starts, the incident automation sends a message
in the #incident-management channel
containing a link to a per-incident Slack channel for text based communication, the
incident issue for permanent records, and the Situation Room Zoom link for incident team members to join for synchronous verbal
and screen-sharing communication.
Scheduled Maintenance
Scheduled maintenance that is a C1 should be treated as an undeclared incident.
30-minutes before the maintenance window starts, the Engineering Manager who is responsible for the change should notify the SRE on-call, the Release Managers and the CMOC to inform them that the maintenance is about to begin.
Coordination and communication should take place in the Situation Room Zoom so that it is quick and easy to include other engineers
if there is a problem with the maintenance.
If a related incident occurs during the maintenance procedure, the EM should act as the Incident Manager for the duration of
the incident.
If a separate unrelated incident occurs during the maintenance procedure, the engineers involved in the scheduled maintenance should
vacate the Situation Room Zoom in favour of the active incident.
Ownership
By default, the EOC is the owner of the incident. The incident owner can delegate ownership to another engineer or escalate ownership to the IM at any time. There is only ever one owner of an incident and only the owner of the incident can declare an incident resolved. At anytime the incident owner can engage the next role in the hierarchy for support. The incident issue should be assigned to the current owner.
Roles and Responsibilities
Clear delineation of responsibilities is important during an incident.
Quick resolution requires focus and a clear hierarchy for delegation of
tasks. Preventing overlaps and ensuring a proper order of operations is vital
to mitigation.
To make your role clear edit your zoom name to start with your role when you join the Zoom meeting. For Example “IM - John Doe”
To edit your name during a zoom call, click on the three dots by your name in your video tile and choose the “rename” option.
Edits made during a zoom call only last for the length of the call, so it should automatically revert to your profile name/title with the next call.
| Role |
Description |
Who? |
EOC - Engineer On Call |
The EOC is usually the first person alerted - expectations for the role are in the Handbook for oncall. The checklist for the EOC is in our runbooks. If another party has declared an incident, once the EOC is engaged the EOC owns the incident. The EOC can escalate a page in PagerDuty to engage the Incident Manager and CMOC. |
The Reliability Team Engineer On Call is generally an SRE and can declare an incident. They are part of the “SRE 8 Hour” on call shift in PagerDuty. |
DRI - Directly Responsible Individual |
The DRI is the owner of the incident and is responsible for the coordination of the incident response and will drive the incident to resolution. The DRI should always be the person assigned to the issue. |
By default, the IM is the DRI for Sev1 and Sev2 externally facing incidents, the EOC is the DRI for all other incidents. The DRI can and should transfer ownership in cases where it makes sense to do so. |
IM - Incident Manager Information about IM onboarding |
The Incident Manager is engaged when incident resolution requires coordination from multiple parties. The Incident Manager is the tactical leader of the incident response team—not a person performing technical work. The IM checklist is in our runbooks. The Incident Manager assembles the incident team by engaging individuals with the skills and information required to resolve the incident. |
The Incident Manager On Call rotation is in PagerDuty |
CMOC - Incident Communications Manager On Call |
The CMOC disseminates information internally to stakeholders and externally to customers across multiple media (e.g. GitLab issues, status.gitlab.com, etc.). |
The Communications Manager is generally member of the support team at GitLab. Notifications to the Incident Management - CMOC service in PagerDuty will go to the rotations setup for CMOC. |
These definitions imply several on-call rotations for the different roles. Note that not all incidents include engagement from Incident Managers or Communication Managers.
Responsibilities
Incident Manager (IM)
For general information about how shifts are scheduled and common scenarios about what to do when you have PTO or need coverage, see the Incident Manager onboarding documentation
When paged, the Incident Managers have the following responsibilities during a Sev1 or Sev2 incident and should be engaged on these tasks immediately when an incident is declared:
- In the event of an incident which has been triaged and confirmed as a clear Severity 1 impact:
- Notify Infrastructure Leadership via PagerDuty, by typing
/pd trigger in Slack. In the “Create New Incident” dialog, select “Infrastructure Leadership” as the Impacted Service with a link to the incident in the Description as well as a reminder that Infrastructure Leadership should follow the process for Infrastructure Leadership Escalation. This notification should happen 24/7.
- In the case of a large scale outage where there is a serious disruption of service, the Incident Manager should check in with Infrastructure Leadership whether a senior member of the Reliability team should be brought into the incident to coordinate and manage recovery efforts. This is to ensure that the person in charge of coordinating multiple parallel recovery efforts has a deeper understanding of what is required to bring services back online. You can page the Infra/SRE managers by using
/pd trigger and picking the “Infrastructure Leadership” Service. You can also add responders to an existing PagerDuty alert via adding the Infra-SRE Managers Escalation contact.
- Consider engaging the release-management team if a code change related issue is identified as a potential cause and we need to explore rollbacks or expedited deployment. This can be done by using their slack handle
release-managers
- Responsible for posting regular status updates in the
Current Status section of the incident issue description. These updates should summarize the current customer impact of the incident and actions we are taking to mitigate the incident. This is the most important section of the incident issue, it will be referenced to status page updates, and should provide a summary of the incident and impact that can be understood by the wider community.
- Ensure that the incident issue has all of the required labels applied.
- Ensure that the incident issue is appropriatly restricted based on data classification.
- If present, ensure that the
Summary for CMOC notice / Exec summary in the incident description is filled out as soon as possible.
- Ensure that necessary public communications are made accurately and in a timely fashion by the Communications Manager. Be mindful that, due to the directive to err on the side of declaring incidents early and often, we should first confirm customer impact with the Engineer On Call prior to approving customer status updates.
- Ensure that all corrective actions, investigations or followups have corresponding issues created and associated to the incident issue.
- Ensuring that the Timeline section of the incident is accurate.
- Ensuring that the root cause is stated clearly and plainly in the incident description, linking to a confidential note or issue if the root cause cannot be made public.
- Determining when the incident has been resolved and ensuring that it is closed and labeled when there is no more user impact.
- If necessary, help the EOC to engage development using the InfraDev escalation process.
- If applicable, coordinate the incident response with business contingency activities.
- If there is a
~review-requested label on the incident, after the incident is resolved, the Incident Manager is the DRI of the post-incident review. The DRI role can be delegated.
- Following the first significant Severity 1 or 2 incident for a new Incident Manager, schedule a feedback coffee chat with the Engineer On Call, Communications Manager On Call, and (optionally) any other key participants to receive actionable feedback on your engagement as Incident Manager.
- For all Severity 1 and Severity 2 incidents that are communicated on the GitLab.com status page, initiate an async incident review and inform the Engineering Manager of the team owning the root cause that they will need to initiate the Feature Change Lock process.
The Incident Manager is the DRI for all of the items listed above, but it is expected that the IM will do it with the support of the EOC or others who are involved with the incident. If an incident runs beyond a scheduled shift, the Incident Manager is responsible for handing over to the incoming IM.
The IM won’t be engaged on these tasks unless they are paged, which is why the default is to page them for all Sev1 and Sev2 incidents.
In other situations, to engage the Incident Manager run /pd trigger and choose the GitLab Production - Incident Manager as the impacted service.
Engineer on Call (EOC) Responsibilities
The Engineer On Call is responsible for the mitigation of impact and resolution to the incident that was declared.
The EOC should reach out to the Incident Manager for support if help is needed or others are needed to aid in the incident investigation.
For Sev3 and Sev4 incidents, the EOC is also responsible for Incident Manager Responsibilities, second to mitigating and resolving the incident.
- As EOC, your highest priority for the duration of your shift is the stability of GitLab.com.
- The SSOT for who is the current EOC is the GitLab Production service definition in PagerDuty.
- SREs are responsible for arranging coverage if they will be unavailable for a scheduled shift. To make a request, send a message indicating the days and times for which coverage is requested to the
#reliability-lounge Slack channel. If you are unable to find coverage reach out to a Reliability Engineering Manager for assistance.
- Alerts that are routed to PagerDuty require acknowledgment within 15 minutes, otherwise they will be escalated to the oncall Incident Manager.
- Alert-manager alerts in
#alerts and #feed_alerts-general are an important source of information about the health of the environment and should be monitored during working hours.
- If the PagerDuty alert noise is too high, your task as an EOC is clearing out that noise by either fixing the system or changing the alert.
- If you are changing the alert, it is your responsibility to explain the reasons behind it and inform the next EOC that the change occurred.
- Each event (may be multiple related pages) should result in an issue in the
production tracker. See production queue usage for more details.
- If sources outside of our alerting are reporting a problem, and you have not received any alerts, it is still your responsibility to investigate. Declare a low severity incident and investigate from there.
- Low severity (S3/S4) incidents (and issues) are cheap, and will allow others a means to communicate their experience if they are also experiencing the issue.
- “No alerts” is not the same as “no problem”
- GitLab.com is a complex system. It is ok to not fully understand the underlying issue or its causes. However, if this is the case, as EOC you should page the Incident Manager to find a team member with the appropriate expertise.
- Requesting assistance does not mean relinquishing EOC responsibility. The EOC is still responsible for the incident.
- The GitLab Organizational Chart and the GitLab Team Page, which lists areas of expertise for team members, are important tools for finding the right people.
- As soon as an S1/S2 incident is declared, join the
The Situation Room Permanent Zoom. The Zoom link is in the #incident-management topic.
- GitLab works in an asynchronous manner, but incidents require a synchronous response. Our collective goal is high availability of 99.95% and beyond, which means that the timescales over which communication needs to occur during an incident is measured in seconds and minutes, not hours.
- It is important that the “Summary” section of incident issues is updated early and often during an incident. This supports our async ability to independently discover the context of an incident and helps all stakeholders (including users) understand the general idea of what is going on.
- Keep in mind that a GitLab.com incident is not an “infrastructure problem”. It is a company-wide issue, and as EOC, you are leading the response on behalf of the company.
- If you need information or assistance, engage with Engineering teams. If you do not get the response you require within a reasonable period, escalate through the Incident Manager.
- As EOC, require that those who may be able to assist to join the Zoom call and ask them to post their findings in the incident issue or active incident Google doc. Debugging information in Slack will be lost and this should be strongly discouraged.
- By acknowledging an incident in PagerDuty, the EOC is implying that they are working on it. To further reinforce this acknowledgement, post a note in Slack that you are joining the
The Situation Room Permanent Zoom as soon as possible.
- If the EOC believes the alert is incorrect, comment on the thread in
#production. If the alert is flappy, create an issue and post a link in the thread. This issue might end up being a part of RCA or end up requiring a change in the alert rule.
- Be inquisitive. Be vigilant. If you notice that something doesn’t seem right, investigate further.
- The EOC should not consider immediate work on an incident completed until the top description section in the Incident Issue (above the “Incident Review” section) is filled out with useful information to describe all the key aspects of the Incident.
- After the incident is resolved, the EOC should review the comments and ensure that the corrective actions are added to the issue description, regardless of the incident severity. If it has a
~review-requested label, the EOC should start on performing an incident review, in some cases this may be be a synchronous review meeting or an async review depending on what is requested by those involved with the incident.
Incident Mitigation Methods - EOC/Incident Manager
- If wider user impact has been established during an S1 or S2 incident, as EOC you have the authority - without requiring further permission - to Block Users as needed in order to mitigate the incident. Make sure to follow Support guidelines regarding
Admin Notes, leaving a note that contains a link to the incident, and any further notes explaining why the user is being blocked.
- If users are blocked, then further follow-up will be required. This can either take place during the incident, or after it has been mitigated, depending on time-constraints.
- If the activity on the account is considered abusive, report the user to Trust and Safety so that the account can be permanently blocked and cleaned-up. Depending on the nature of the event, the EOC may also consider reaching out to the SIRT team.
- If not, open a related confidential incident issue and assign it to CMOC to reach out to the user, explaining why we had to block their account temporarily.
- If the EOC is unable to determine whether the user’s traffic was malicious or not, please engage the SIRT team to carry out an investigation.
When to Engage an Incident Manager
If any of the following are true, it would be best to engage an Incident Manager:
- There is a S1/P1 report or security incident.
- An entire path or part of functionality of the GitLab.com application must be blocked.
- Any unauthorized access to a GitLab.com production system
- Two or more S3 or higher incidents to help delegate to other SREs.
To engage with the Incident Manager run /pd trigger and choose the GitLab Production - Incident Manager as the impacted service. Please note that when an incident is upgraded in severity (for example from S3 to S1), PagerDuty does not automatically page the Incident Manager or Communications Manager and this action must be taken manually.
What happens when there are simultaneous incidents?
Occasionally we encounter multiple incidents at the same time. Sometimes a single Incident Manager can cover multiple incidents. This isn’t always possible, especially if there are two simultaneous high-severity incidents with significant activity.
When there are multiple incidents and you decide that additional incident manager help is required, take these actions:
- Post a slack message in #imoc_general as well as #incident-management asking for additional Incident Manager help.
- If your ask is not addressed via slack, escalate to Infastructure Leadership in PagerDuty.
If a second incident zoom is desired, choose which incident will move to the new zoom and create a new meeting in zoom. Be sure to edit the channel topic of the incident slack channel to indicate the correct zoom link.
Weekend Escalations
EOCs are responsible for responding to alerts even on the weekends. Time should not be spent mitigating the incident unless it is a ~severity::1 or ~severity::2. Mitigation for ~severity::3 and ~severity::4 incidents can occur during normal business hours, Monday-Friday. If you have any questions on this please reach out to an Infrastructure Engineering Manager.
If a ~severity::3 and ~severity::4 occurs multiple times and requires weekend work, the multiple incidents should be combined into a single severity::2 incident.
If assistance is needed to determine severity, EOCs and Incident Managers are encouraged to contact Reliability Leadership via PagerDuty
Infrastructure Leadership Escalation
During a verified Severity 1 Incident the IM will page for Infrastructure Leadership. This is not a substitute or replacement for the active Incident Manager. The Infrastructure Leadership responsibilities include:
- Overall evaluation of the incident and further validation of Severity.
- Assistance with further support from other teams, including those outside of Engineering (as appropriate)
- Posting a notice to e-group slack channel. This notice does not have to be expedited, but should occur once there is a solid understanding of user impact as well as the overall situation and current response activities. The e-group notice should be in this format
:s1: **Incident on GitLab.com**
**— Summary —**
(include high level summary)
**— Customer Impact —**
(describe the impact to users including which service/access methods and what percentage of users)
**— Current Response —**
(bullet list of actions)
**— Production Issue —**
Main incident: (link to the incident)
Slack Channel: (link to incident slack channel)
- After posting the notice, continue to engage with the incident as needed and also post updates to a thread of the e-group notification when there are material/significant updates.
Further support is available from the Scalability and Delivery Groups if required. Scalability leadership can be reached
via PagerDuty Scalability Escalation (further details available on their team page). Delivery leadership can be reached via PagerDuty. See the Release Management Escalation steps on the Delivery group page.
Communications Manager on Call (CMOC) Responsibilities
For serious incidents that require coordinated communications across multiple channels, the Incident Manager will rely on the CMOC for the duration of the incident.
The GitLab support team staffs an oncall rotation and via the Incident Management - CMOC service in PagerDuty. They have a section in the support handbook for getting new CMOC people up to speed.
During an incident, the CMOC will:
- Be the voice of GitLab during an incident by updating our end-users and internal parties through updates to our status page hosted by Status.io.
- Tip: use
/incident post-statuspage on Slack to create an incident on Status.io. Any updates to the incident will have to be done manually by following these instructions.
- Update the status page at regular intervals in accordance with the severity of the incident.
- Notify GitLab stakeholders (customer success and community team) of current incident and reference where to find further information. Provide additional update when the incident is mitigated.
- Given GitLab’s directive to err on the side of declaring incidents early and often, it is important for the Communications Manager not to make public communications without first confirming with the Engineer on Call and Incident Manager that the incident has significant external customer impact. Rushing to communicate incidents before understanding impact can lead to a public perception of reliability impacts that may not be accurate, because we regularly declare an incident at Severity 1 or 2 initially and then downgrade it one or even two levels once the scope of customer impact is more clearly understood.
How to engage the CMOC?
If, during an incident, EOC or Incident Manager decide to engage CMOC, they should do that
by paging the on-call person:
- Using the
/pd trigger command in Slack, then select the “Incident Management - CMOC” service from the modal.
or
- Directly from PagerDuty in the Incident Management - CMOC Rotation
schedule in PagerDuty. That can be done by navigating to Incidents page in PagerDuty,
and then creating the new incident while picking Incident Management - CMOC as
Impacted Service.
Incidents requiring direct customer interaction
If, during an S1 or S2 incident, it is determined that it would be beneficial to have a synchronous conversation with one or more customers a new Zoom meeting should be utilized for that conversation. Typically there are two situations which would lead to this action:
- An incident which is uniquely impacting a single, or small number, of customers where their insight into how they are using GitLab.com would be valuable to finding a solution.
- A large-scale incident, such as a multi-hour full downtime or regional DR event, when it is desired to have synchronous conversation with key customers, typically to provide another form of update or to answer further questions.
Due to the overhead involved and the risk of detracting from impact mitigation efforts, this communication option should be used sparingly and only when a very clear and distinct need is present.
Implementing a direct customer interaction call for an incident is to be initiated by the current Incident Manager by taking these steps:
- Identify a second Incident Manager who will be dedicated to the customer call. If not already available in the incident, announce the need in #imoc_general with a message like
/here A second incident manager is required for a customer interaction call for XXX.
- Page the Infrastructure Leadership pagerduty rotation for additional assistance and awareness.
- Identify a Customer Success Manager who will act as the primary CSM and also be dedicated to the customer call. If this role is not clear, also refer to Infrastructure Leadership for assistance.
- Request that both of these additional roles join the main incident to come up to speed on the incident history and current status. If necessary to preserve focus on mitigation, this information sharing may be done in another Zoom meeting (which could then also be used for the customer conversation)
After learning of the history and current state of the incident the Engineering Communications Lead will initiate and manage the customer interaction through these actions:
- Start a new Zoom meeting - unless one is already in progress - invite the primary CSM.
- The Engineering Communications Lead and CSM should appropriately set their Zoom name to indicate
GitLab, as well as their Role, CSM Engineering Communications Lead
- Through the CSM, invite any customers who are required for the discussion.
- The Engineering Communications Lead and the Incident Manager need to prioritize async updates that will allow for the correct information to flow between conversations. Consider using the incident slack channel for this but agree before the customer call starts.
- Both the Engineering Communications Lead and CSM should remain in the Zoom with the customers for the full time required for the incident. To avoid loss of context, neither should “jump” back and forth from the internal incident Zoom and the customer interaction Zoom.
In some scenarios it may be necessary for most all participants of an incident (including the EOC, other developers, etc.) to work directly with a customer. In this case, the customer interaction Zoom shall be used, NOT the main GitLab Incident Zoom. This will allow for the conversation (as well as text chat) while still supporting the ability for primary responders to quickly resume internal communications in the main Incident Zoom. Since the main incident Zoom may be used for multiple incidents it will also prevent the risk of confidential data leakage and prevent the inefficiency of having to frequently announce that there are customers in the main incident zoom each time the call membership changes.
Corrective Actions
Corrective Actions (CAs) are work items that we create as a result of an incident. Only issues arising out of an incident should receive the label “corrective action”. They are designed to prevent the same kind of incident or improve the time to mitigation and as such are part of the Incidence Management cycle.
Work items identified in incidents that don’t meet the Corrective Action criteria should be raised in the Reliability project and labeled with ~work::incident rather than ~corrective action
Corrective Actions should be related to the incident issue to help with downstream analysis, and it can be helpful to refer to the incident in the description of the issue.
Corrective Actions issues in the Reliability project should be created using the Corrective Action issue template to ensure consistency in format, labels and application/monitoring of service level objectives for completion
Best practices and examples, when creating a Corrective Action issue:
- Use SMART criteria: Specific, Measurable, Achievable, Relevant and Time-bounded.
- Link to the incident they arose from.
- Assign a Severity label designating the highest severity of related incidents.
- Assign a priority label indicating the urgency of the work. By default, this should match the incident Severity
- Assign the label for the associated affected service if applicable.
- Provide enough context so that any engineer in the Corrective Action issue’s project could pick up the issue and know how to move forward with it.
- Avoid creating Corrective Actions that:
- Are too generic (most typical mistake, as opposed to Specific)
- Only fix incident symptoms.
- Introduce more human error.
- Will not help to keep the incident from happening again.
- Can not be promptly implemented (time-bounded).
- Examples: (taken from several best-practices Postmortem pages)
| Badly worded |
Better |
| Fix the issue that caused the outage |
(Specific) Handle invalid postal code in user address form input safely |
| Investigate monitoring for this scenario |
(Actionable) Add alerting for all cases where this service returns >1% errors |
| Make sure engineer checks that database schema can be parsed before updating |
(Bounded) Add automated presubmit check for schema changes |
| Improve architecture to be more reliable |
(Time-bounded and specific) Add a redundant node to ensure we no longer have a single point of failure for the service |
Runbooks
Runbooks are available for
engineers on call. The project README contains links to checklists for each
of the above roles.
In the event of a GitLab.com outage, a mirror of the runbooks repository is available on at https://ops.gitlab.net/gitlab-com/runbooks.
Who is the Current EOC?
The chatops bot will give you this information if you DM it with /chatops run oncall prod.
The current EOC can be contacted via the @sre-oncall handle in Slack, but please only use this handle in the following scenarios.
- You need assistance in halting the deployment pipeline. note: this can also be accomplished by Reporting an Incident and labeling it with
~blocks deployments.
- You are conducting a production change via our Change Management process and as a required step need to seek the approval of the EOC.
- For all other concerns please see the Getting Assistance section.
The EOC will respond as soon as they can to the usage of the @sre-oncall handle in Slack, but depending on circumstances, may not be immediately available. If it is an emergency and you need an immediate response, please see the Reporting an Incident section.
Reporting an Incident
If you are a GitLab team member and would like to report a possible incident related to GitLab.com and have the EOC paged in to respond, choose one of the reporting methods below. Regardless of the method chose, please stay online until the EOC has had a chance to come online and engage with you regarding the incident. Thanks for your help!
Report an Incident via Slack
Type /incident declare in the #production channel in GitLab’s Slack and follow the prompts to open an incident issue.
It is always better to err on side of choosing a higher severity, and declaring an incident for a production issue, even if you aren’t sure.
Reporting high severity bugs via this process is the preferred path so that we can make sure we engage the appropriate engineering teams as needed.
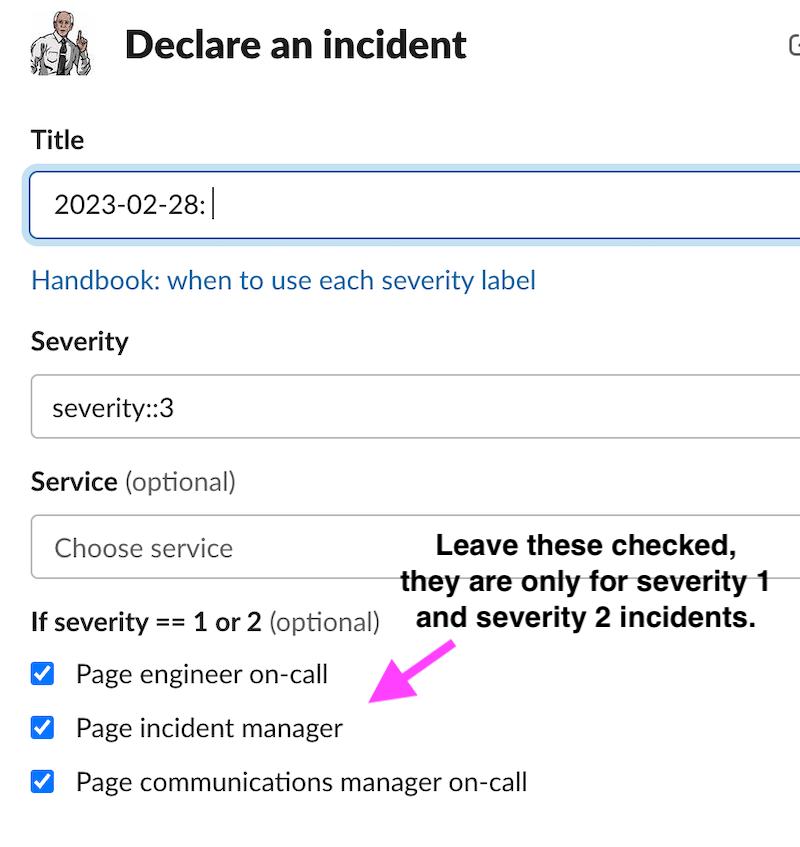 Incident Declaration Slack window
Incident Declaration Slack window
| Field |
Description |
| Title |
Give the incident as descriptive as title as you can. Please include the date in the format YYYY-MM-DD which should be present by default. |
| Severity |
If unsure about the severity, but you are seeing a large amount of customer impact, please select S1 or S2. More details here: Incident Severity. |
| Service |
If possible, select a service that is likely the cause of the incident. Sometimes this will also be the service impacted. If you are unsure, it is fine to leave this empty. |
| Page engineer on-call / incident manager / communications manager on-call |
Leave these checked unless the incident is severity 1 or severity 2, and does not require immediate engagement (this is unusual), or if the person submitting the incident is the EOC. We will not page anyone for severity 3 and severity 4 incidents, even if the boxes are checked. |
| Confidential |
This will mark the issue confidential, do this for all security related issues or incidents that primarily contain information that is not SAFE. We generally prefer to leave this unchecked, and use confidential notes for information that cannot be public. |
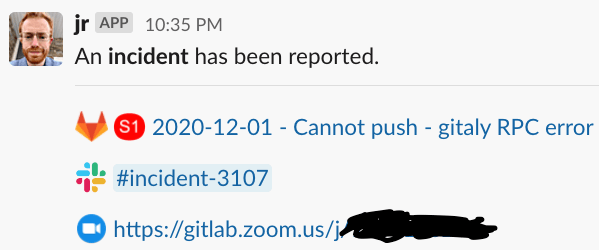
Incident Declaration Results
As well as opening a GitLab incident issue, a dedicated incident Slack channel will be opened. The “woodhouse” bot will post links to all of these resources in the main #incident-management channel. Please note that unless you’re an SRE, you won’t be able to post in #incident-management directly. Please join the dedicated Slack channel, created and linked as a result of the incident declaration, to discuss the incident with the on-call engineer.
Report an Incident via Email
Email gitlab-production-eoc@gitlab.pagerduty.com. This will immediately page the Engineer On Call.
Definition of Outage vs Degraded vs Disruption and when to Communicate
This is a first revision of the definition of Service Disruption (Outage), Partial Service Disruption, and Degraded Performance per the terms on Status.io.
Data is based on the graphs from the Key Service Metrics Dashboard
Outage and Degraded Performance incidents occur when:
Degraded as any sustained 5 minute time period where a service is below its documented Apdex SLO or above its documented error ratio SLO.Outage (Status = Disruption) as a 5 minute sustained error rate above the Outage line on the error ratio graph

In both cases of Degraded or Outage, once an event has elapsed the 5 minutes, the Engineer on Call and the Incident Manager should engage the CMOC to help with external communications. All incidents with a total duration of more than 5 minutes should be publicly communicated as quickly as possible (including “blip” incidents), and within 1 hour of the incident occurring.
SLOs are documented in the runbooks/rules
To check if we are Degraded or Disrupted for GitLab.com, we look at these graphs:
- Web Service
- API Service
- Git service(public facing git interactions)
- GitLab Pages service
- Registry service
- Sidekiq
A Partial Service Disruption is when only part of the GitLab.com services or infrastructure is experiencing an incident. Examples of partial service disruptions are instances where GitLab.com is operating normally except there are:
- delayed CI/CD pending jobs
- delayed repository mirroring
- high severity bugs affecting a particular feature like Merge Requests
- Abuse or degradation on 1 gitaly node affecting a subset of git repos. This would be visible on the Gitaly service metrics
High Severity Bugs
In the case of high severity bugs, we prefer that an incident issue is still created via Reporting an Incident. This will give us an incident issue on which to track the events and response.
In the case of a high severity bug that is in an ongoing, or upcoming deployment please follow the steps to Block a Deployment.
Security Incidents
If an incident may be security related, engage the Security Engineer on-call by using /security in Slack. More detail can be found in Engaging the Security Engineer On-Call.
Communication
Information is an asset to everyone impacted by an incident. Properly managing the flow of information is critical to minimizing surprise and setting expectations. We aim to keep interested stakeholders apprised of developments in a timely fashion so they can plan appropriately.
This flow is determined by:
- the type of information,
- its intended audience,
- and timing sensitivity.
Furthermore, avoiding information overload is necessary to keep every stakeholder’s focus.
To that end, we will have:
�
- a dedicated Zoom call for all incidents. A link to the Zoom call can be found in the topic for the
#incident-management room in Slack.
- a Google Doc as needed for multiple user input based on the shared template
- a dedicated
#incident-management channel for internal updates
- regular updates to status.gitlab.com via status.io that disseminates to various media (e.g. Twitter)
- a dedicated repo for issues related to Production separate from the queue that holds Infrastructure’s workload: namely, issues for incidents and changes.
Status
We manage incident communication using status.io, which updates status.gitlab.com. Incidents in status.io have state and status and are updated by the incident owner.
To create an incident on status.io, you can use /incident post-statuspage on Slack.
Status during Security Incidents
In some cases, we may choose not to post to status.io, the following are examples where we may skip a post/tweet. In some cases, this helps protect the security of self managed instances until we have released the security update.
- If a partial block of a URL is possible, for example to exclude problematic strings in a path.
- If there is no usage of the URL in the last week based on searches in our logs for GitLab.com.
States and Statuses
Definitions and rules for transitioning state and status are as follows.
| State |
Definition |
| Investigating |
The incident has just been discovered and there is not yet a clear understanding of the impact or cause. If an incident remains in this state for longer than 30 minutes after the EOC has engaged, the incident should be escalated to the Incident Manager On Call. |
| Active |
The incident is in progress and has not yet been mitigated. Note: Incidents should not be left in an Active state once the impact has been mitigated |
| Identified |
The cause of the incident is believed to have been identified and a step to mitigate has been planned and agreed upon. |
| Monitoring |
The step has been executed and metrics are being watched to ensure that we’re operating at a baseline. If there is a clear understanding of the specific mitigation leading to resolution and high confidence in the fact that the impact will not recur it is preferable to skip this state. |
| Resolved |
The impact of the incident has been mitigated and status is again Operational. Once resolved the incident can be marked for review and Corrective Actions can be defined. |
Status can be set independent of state. The only time these must align is when an issues is
| Status |
Definition |
| Operational |
The default status before an incident is opened and after an incident has been resolved. All systems are operating normally. |
| Degraded Performance |
Users are impacted intermittently, but the impact is not observed in metrics, nor reported, to be widespread or systemic. |
| Partial Service Disruption |
Users are impacted at a rate that violates our SLO. The Incident Manager On Call must be engaged and monitoring to resolution is required to last longer than 30 minutes. |
| Service Disruption |
This is an outage. The Incident Manager On Call must be engaged. |
| Security Issue |
A security vulnerability has been declared public and the security team has requested that it be published on the status page. |
Severities
Incident Severity
Incident severity should be assigned at the beginning of an incident to ensure proper response across the organization. Incident severity should be determined based on the information that is available at the time. Severities can and should be adjusted as more information becomes available. The severity level reflects the maximum impact the incident had and should remain in that level even after the incident was mitigated or resolved.
Incident Managers and Engineers On-Call can use the following table as a guide for assigning incident severity.
| Severity |
Description |
Example Incidents |
~severity::1 |
- GitLab.com is unavailable or severely degraded for the typical GitLab user
- Any data loss directly impacting customers
- The guaranteed self-managed release date is put in jeopardy
- It is a high impact security incident
- It is an internally facing incident with full loss of metrics observability (Prometheus down)
Incident Managers should be paged for all ~severity::1 incidents |
Past severity::1 Issues |
~severity::2 |
- There is a recorded impact to the availability of one or more GitLab.com Primary Service with a weight > 0. This includes api, container registry, git access, API and web.
- GitLab.com is unavailable or degraded for a small subset of users
- GitLab.com is degraded but a reasonable workaround is available (includes widespread frontend degradations)
- Any moderate impact security incident
- CustomersDot is offline
Incident Managers should be paged for all ~severity::2 incidents |
Past severity::2 Incidents |
~severity::3 |
- Broad impact on GitLab.com and minor inconvenience to typical user’s workflow
- A workaround is not needed
- Any low impact security incident
- Most internally facing issues pertaining to blocked deployments (should a higher-severity incident be blocked by deployments, the severity for the blocker is still 3)
- CustomersDot is in maintenance mode |
Past severity::3 Incidents |
~severity::4 |
- Minimal impact on GitLab.com typical user’s workflow |
Past severity::4 Incidents |
Alert Severities
- Alerts severities do not necessarily determine incident severities. A single incident can trigger a number of alerts at various severities, but the determination of the incident’s severity is driven by the above definitions.
- Over time, we aim to automate the determination of an incident’s severity through service-level monitoring that can aggregate individual alerts against specific SLOs.
Incident Data Classification
There are four data classification levels defined in GitLab’s Data Classification Standard.
- RED data should never be included in incident issues, even if the issue is confidential.
- ORANGE and YELLOW data can be included and the Incident Manager managing the incident should ensure the incident issue is marked as confidential or is in an internal note.
The Incident Manager should exercise caution and their best judgement, in general we prefer to use internal notes instead of marking an entire issue confidential if possible.
A couple lines of non-descript log data may not represent a data security concern, but a larger set of log, query, or other data must have more restrictive access.
If assistance is required follow the Infrastructure Leadership Escalation process.
Incident Workflow
Summary
In order to effectively track specific metrics and have a single pane of glass for incidents and their reviews, specific labels are used. The below workflow diagram describes the path an incident takes from open to closed. All S1 incidents require a review, other incidents can also be reviewed as described here.
GitLab uses the Incident Management feature of the GitLab application. Incidents are reported and closed when they are resolved. A resolved incident means the degradation has ended and will not likely re-occur.
If there is additional follow-up work that requires more time after an incident is resolved and closed (like a detailed root cause analysis or a corrective action) a new issue may need to be created and linked to the incident issue.
It is important to add as much information as possible as soon as an incident is resolved while the information is fresh, this includes a high level summary and a timeline where applicable.
Assignees
The EOC and the Incident Manager On Call, at the time of the incident, are the default assignees for an incident issue. They are the assignees for the entire workflow of the incident issue.
Timeline
Incidents use the Timeline Events feature, the timeline can be viewed by selecting the “Timeline” tab on the incident.
By default, all label events are added to the Timeline, this includes ~"Incident::Mitigated" and ~"Incident::Resolved".
At a minimum, the timeline should include when start and end times of user impact.
You may also want to highlight notes in the discussion, this is done by selecting the clock icon on the note which will automatically add it to the timeline.
For adding timeline items quickly, use the quick action, for example:
/timeline DB load spiked resulting in performance issues | 2022-09-07 09:30
/timeline DB load spike mitigated by blocking malicious traffic | 2022-09-07 10:00
Labeling
The following labels are used to track the incident lifecycle from active incident to completed incident review. Label Source
Workflow Labeling
In order to help with attribution, we also label each incident with a scoped label for the Infrastructure Service (Service::) and Group (group::) scoped labels among others.
| Label |
Workflow State |
~Incident::Active |
Indicates that the incident labeled is active and ongoing. Initial severity is assigned when it is opened. |
~Incident::Mitigated |
Indicates that the incident has been mitigated. A mitigated issue means that the impact is significantly reduced and immediate post-incident activity is ongoing (monitoring, messaging, etc.). The mitigated state should not be used for silenced alerts, or alerts that may reoccur. In both cases you should mark the incident as resolved and close it. |
~Incident::Resolved |
Indicates that SRE engagement with the incident has ended and the condition that triggered the alert has been resolved. Incident severity is re-assessed and determined if the initial severity is still correct and if it is not, it is changed to the correct severity. Once an incident is resolved, the issue will be closed. |
Root Cause Labeling
Labeling incidents with similar causes helps develop insight into overall trends and when combined with Service attribution, improved understanding of Service behavior. Indicating a single root cause is desirable and in cases where there appear to be multiple root causes, indicate the root cause which precipitated the incident.
The EOC, as DRI of the incident, is responsible for determining root cause.
The current Root Cause labels are listed below. In order to support trend awareness these labels are meant to be high-level, not too numerous, and as consistent as possible over time.
| Root Cause |
Description |
~RootCause::Config-Change |
configuration change, other than a feature flag being toggled |
~RootCause::Database-Failover |
database failover event |
~RootCause::DB-Migration |
resulting from a database migration or a post-deploy migration |
~RootCause::ExternalAgentMaliciousBehavior |
ostensibly malicious behavior by an external agent |
~RootCause::External-Dependency |
resulting from the failure of a dependency external to GitLab, including various service providers. Use of other causes (such as ~RootCause::SPoF or ~RootCause::Saturation) should be strongly considered for most incidents. |
~RootCause::FalseAlarm |
an incident was created by a page that isn’t actionable and should result into adjusting the alert or deleting it |
~RootCause::Feature-Flag |
a feature flag toggled in some way (off or on or a new percentage or target was chosen for the feature flag) |
~RootCause::Flaky-Test |
an incident, usually a deployment pipeline failure found to have been caused by a flaky QA test |
~RootCause::GCP-Networking |
GCP networking event |
~RootCause::Indeterminate |
when an incident has been investigated, but the root cause continues to be unknown and an agreement has been formed to not pursue any further investigation. |
~RootCause::Known-Software-Issue |
known/existing technical debt in the product that has yet to be addressed |
~RootCause::Malicious-Traffic |
deliberate malicious activity targeted at GitLab or customers of GitLab (e.g. DDoS) |
~RootCause::Naive-Traffic |
elevated external traffic exhibiting anti-pattern behavior for interface usage |
~RootCause::Release-Compatibility |
forward- or backwards-compatibility issues between subsequent releases of the software running concurrently, and sharing state, in a single environment (e.g. Canary and Main stage releases). They can be caused by incompatible database DDL changes, canary browser clients accessing non-canary APIs, or by incompatibilities between Redis values read by different versions of the application. |
~RootCause::Saturation |
failure resulting from a service or component which failed to scale in response to increasing demand (whether or not it was expected) |
~RootCause::Security |
an incident where the SIRT team was engaged, generally via a request originating from the SIRT team or in a situation where Reliability has paged SIRT to assist in the mitigation of an incident not caused by ~RootCause::Malicious-Traffic |
~RootCause::Software-Change |
feature or other code change |
~RootCause::SPoF |
the failure of a service or component which is an architectural SPoF (Single Point of Failure) |
Customer Communications Labeling
We want to be able to report on a scope of incidents which have met a level of impact which necessitated customer communications. An underlying assumption is that any material impact will always be communicated in some form. Incidents are to be labeled indicating communications even if the impact is later determined to be lesser, or when the communication is done by mistake.
Note: This does not include Contact Requests where the communication is due to identifying a cause.
The CMOC is responsible for ensuring this label is set for all incidents involving use of the Status Page or where other direct notification to a set of customers is completed (such as via Zendesk).
| Customer Communications |
Description |
~Incident-Comms::Status-Page |
Incident communication included use of the public GitLab Status Page |
~Incident-Comms::Private |
Incident communication was limited to fewer customers or otherwise was only directly communicated to impacted customers (not via the GitLab Status Page) |
~Contact Request |
Applied to issues where it is requested that Support contact a user or customer |
~Contact Request::Awaiting Contact |
Support has yet to contact the user(s) in question in this issue. |
~Contact Request::Contacted |
Support has contacted the user(s) in question and is awaiting confirmation from Production. |
~CMOC Required |
Marks issues that require a CMOC involvement. |
Service Labeling
- In the incident description, we allow multiple service labels for impact. The service label on the incident issue itself should be for the root cause, not the impact.
- All Infrastructure changes and configuration that is maintained by the Infrastructure department (not application code) should use one of the specific labels for the component (eg: Consul, Prometheus, Grafana, etc.), or the
~Service::Infrastructure label
- We may not know what service caused the impact until after the incident. In that case, it is best to use the
Service::Unknown label until more information is available.
It is not always very clear which service label to apply, especially when causes span service boundaries that we define in Infrastructure.
When unsure, it’s best to choose a label that corresponds to the primary cause of the incident, even if other services are involved.
The following services should primarily be used for application code changes or feature flag changes, not changes to configuration or code maintained by the Infrastructure department:
~Service::API~Service::Web~Service::Git~Service::Registry~Service::Pages~Service::Gitaly~Service::GitLab Rails
Service labeling examples:
| Example |
Outcome |
| An incident is declared but we don’t know yet what caused the impact. |
Use ~Service::Unknown |
| A bug was deployed to Production that primarily impacted API traffic. |
Use ~Service::API |
| A bug in frontend code caused problems for most browser sessions. |
Use ~Service::Web |
| A featureflag was toggled that caused a problem that mostly affected Git traffic. |
Use ~Service::Git |
| A bad configuration value in one of our Kubernetes manifests caused a service disruption on the Registry service. |
Use ~Service::Infrastructure |
| A mis-configuration of Cloudflare caused some requests to be cached improperly. |
Use ~Service::Cloudflare |
| Monitoring stopped working due to a Kubernetes configuration update on Prometheus |
Use ~Service::Prometheus |
| A site-wide outage caused by a configuration change to Patroni. |
Use ~Service::Patroni |
| A degradation in service due to missing index on a table. |
Use ~Service::GitLab Rails |
“Needed” and “NotNeeded” Scoped Labels
The following labels are added and removed automatically by triage-ops:
| Needs Label |
Description |
~{RootCause,Service,CorrectiveActions,IncidentReview}::Needed |
Will be added automatically if the corresponding label has not been set. If this label persists the DRI of the incident will be mentioned on a note to correctly label the incident |
~{RootCause,Service,CorrectiveActions,IncidentReview}::NotNeeded |
In rare cases, the corresponding label won’t be needed, this label can be used to disable the periodic notes to remind the DRI to update the label |
Required Labeling
These labels are always required on incident issues.
| Label |
Purpose |
~Service::* |
Scoped label for service attribution. Used in metrics and error budgeting. |
~Severity::* (automatically applied) |
Scoped label for severity assignment. Details on severity selection can be found in the availability severities section. |
~RootCause::* |
Scoped label indicating root cause of the incident. |
Other Incident Labels
These labels are added to incident issues as a mechanism to add metadata for the purposes of metrics and tracking.
| Label |
Purpose |
~incident (automatically applied) |
Label used for metrics tracking and immediate identification of incident issues. |
~self-managed |
Indicates that an incident is exclusively an incident for self-managed GitLab. Example self-managed incident issue |
~incident-type::automated traffic |
The incident occurred due to activity from security scanners, crawlers, or other automated traffic |
~backstage |
Indicates that the incident is internally facing, rather than having a direct impact on customers. Examples include issues with monitoring, backups, failing tests, self-managed release or general deploy pipeline problems. |
~group::* |
Any development group(s) related to this incident |
~review-requested |
Indicates that that the incident would benefit from undergoing additional review. All S1 incidents are required to have a review. Additionally, anyone including the EOC can request an incident review on any severity issue. Although the review will help to derive corrective actions, it is expected that corrective actions are filled whether or not a review is requested. If an incident does not have any corrective actions, this is probably a good reason to request a review for additional discussion. |
~Incident-Comms::* |
Scoped label indicating the level of communications. |
~blocks deployments |
Indicates that if the incident is active, it will be a blocker for deployments. This is automatically applied to ~severity::1 and ~severity::2 incidents. The EOC or Release Manager can remove this label if it is safe to deploy while the incident is active. A comment must accompany the removal stating the safety or reasoning that enables deployments to continue. This label may also be applied to lower severity incidents if needed. |
~blocks feature-flags |
Indicates that while the incident is active, it will be a blocker for changes to feature flags. This is automatically applied to ~severity::1 and ~severity::2 incidents. The EOC or Release Manager can remove this label if there is no risk in making feature flag changes while the incident is active. A comment must accompany the removal stating the safety or reasoning that enables feature flag changes to continue. This label may also be applied to lower severity incidents if needed. |
~Delivery impact::* |
Indicates the level of impact this incident is having on GitLab deployment and releases |
Duplicates
When an incident is created that is a duplicate of an existing incident it is up to the EOC to mark it as a duplicate.
In the case where we mark an incident as a duplicate, we should issue the following slash command and remove all labels on the incident issue:
/duplicate <incident issue>
There are related issue links on the incident template that should be used to create related issues from an incident.
- Corrective action: Creates a new corrective action in the reliability tracker.
- Investigation followup: Investigation follow-ups for any root cause investigation, analysis or tracking an alert silence that will be done after the incident is resolved
- Confidential / Support contact: For transparency, we prefer to keep incident issues public. If there is confidential information associated with an issue use this template to create a new issue using the confidential template. Use this template to create requests to the support team engage customers (aka Contact Request).
- QA investigation: To engage the QA team for a failing test, or missing coverage for an issue that was found in any environment.
- Infradev: For engaging development for any incident related improvement.
Workflow Diagram
graph TD
A(Incident is declared) --> |initial severity assigned - EOC and IM are assigned| B(Incident::Active)
A -.-> |all labels removed if duplicate| F(closed)
B --> |"Temporary mitigation is in place (see workflow labeling above)"| C(Incident::Mitigated)
B --> D
C --> D(Incident::Resolved)
D --> |severity is re-assessed| D
D -.-> |for review-requested incidents| E(Incident::Review-Completed)
- As soon as an incident transitions to
Incident::Resolved the incident issue will be closed
- All
Severity::1 incidents will automatically be labeled with review-requested
Alert Silences
If an alert silence is created for an active incident, the incident should be resolved with the ~"alertmanager-silence" label and the appropriate root cause label if it is known.
There should also be a linked ~infradev issue for the long term solution or an investigation issue created using the related issue links on the incident template.
Incident Board
The board which tracks all GitLab.com incidents from active to reviewed is located here.
Near Misses
A near miss, “near hit”, or “close call” is an unplanned event that has the potential to cause, but does not actually result in an incident.
Background
In the United States, the Aviation Safety Reporting System has been collecting reports
of close calls since 1976. Due to near miss observations and other technological improvements,
the rate of fatal accidents has dropped about 65 percent.
source
As John Allspaw states:
Near misses are like a vaccine. They help the company better defend against
more serious errors in the future, without harming anyone or anything in the process.
Handling Near Misses
When a near miss occurs, we should treat it in a similar manner to a normal incident.
- Open an incident issue, if one is not already opened. Label it with the severity label appropriate to the incident it would have caused, had the incident actually occurred. Label the incident issue with the
~Near Miss label.
- corrective actions should be treated in the same way as those for an actual incident.
- Ownership of the incident review should be assigned to the team-member who noticed the near-miss, or, when appropriate, the team-member with the most knowledge of how the near-miss came about.
Introduction This page is meant to be the starting point for onboarding as an Incident Managers.
As a means to ensure a healthy Incident Manager rotation with sufficient staffing and no significant burden on any single individual we staff this role with Team Members from across Engineering.
An Incident Manager On Call (IMOC) has the following goals during a call:
Identify/quantify impact to GitLab customers (metrics, customer support requests) Gather necessary folks to support area(s) of investigation/resolution Suggest politely that people not contributing leave the call, request that folks do so when the number of people in the call is a distraction (30 people as an somewhat arbitrary guideline).
