How to create a user persona
This handbook page defines the process for creating user personas only.
At GitLab, we use two kinds of personas that we create based on data-driven insights that focus on user needs and emotions:
-
User personas - Used by UX professionals and Product Managers (PM) as a mechanism to connect with end users’ needs, motivations, behaviors, and skills. Owned by Product Managers, who are also the DRI on persona-related research efforts.
-
Buyer personas - Focus on the high-level goals of potential customers who may or may not be potential users. Owned by the Marketing team.
This insightful article by UX Collective goes into great detail on these differences and more.
User personas are developed to be useful to both Product Managers and Product Designers. They can be used to help understand the priority of potential features, increase the empathy in our communication and presentation to our users, and help shape design choices by understanding the background of our users. Each user persona is crafted to have a high amount of accuracy so that the information can remain useful for our stakeholders over a long period of time. Because of the importance of obtaining highly accurate information, the process of creating each persona is very detailed and can take a significant amount of time to research.
What makes up a user persona?
Each persona in GitLab’s persona page should have the following traits:
- Job Summary - Should include major focus areas and a general description of skills and responsibilities
- Alternative Titles
- Motivations - It’s suggested to keep to this format: When [situation], I want [feature] so that I can [task]
- Frustrations - A frustration should focus around a common blocker to their responsibilities
- Jobs to be Done (for recently updated personas)
(Optional)
- Personal Skills & Traits - Positive attributes that give life and empathy to your user persona
- Key Tools - Important software that helps the user complete their tasks
- Workflows- A series of steps the user will normally take to complete their tasks
- Collaborative Teams - Teams in their organization that they may have overlap in responsibilities with or are dependent on in their workflow
Our Simone (Software Engineer in Test) is a good example of many of these.
Not all of the additional details are necessary, so it can be helpful to discuss with stakeholders to know which could be useful. If there is any doubt, a guideline is the more detailed, the better.
Steps for building out a user persona
The process for building out user personas is based on data obtained through user research. The following steps are designed to provide teams with the data they need to build out a new user persona with a high degree of confidence and accuracy.
It’s strongly recommended to consult with a UX Researcher at the start and conclusion of each step. This will help set you up for success as you start efforts and also provide you with another set of eyes to review your data.
Step 1: Meet with Stakeholders
Stakeholders are team members who are likely to use this user persona in the process of their own work. Ideal team members would typically be Software Engineers, Product Managers, Product Designers, and so on, who have experience with tools for the persona you are trying to build. For example, if you are building a persona for a security analyst then your stakeholders should have experience with building security tools for those users.
The goal of this step is to increase our understanding of what information is most important to ask in the interviews and which information to use in the screeners to collect participants.
- Create a research issue for problem validation, and fill in the template to the best of your ability.
- Then, use the User Persona - Stakeholder conversation [Template] and fill in the information for your own persona.
- Place a link to this sheet in your issue.
- Write down a list of the stakeholders you want feedback from for this persona. This should be ideally 5 team members who would interact with this persona and have some knowledge of the users in question. Ask your stakeholders to fill out their own section of your User Persona Stakeholder Conversation sheet.
- If you are one of the stakeholders for this project, try not to contribute very much in this phase, and let your other stakeholders steer most of the insights.
- When filling out the sheet, consider different use cases, tools, job responsibilities, or anything else that the potential persona has to face in their job that could impact their interaction with GitLab.
- When all stakeholders have filled out the information, summarize their feedback in the ‘summary’ tab of the Google Sheet and write the results in your research issue.
Step 2: Internal Interviews
The second step is to interview between 5-10 GitLab team members who have the same or a similar job title to the user persona being created. This meeting should be approx. 30 min, but you may want to allow more time if you need more information.
The goal of this step is to expand on the information already gathered and to interact directly with the population you are trying to understand, which will help us know that we are asking the right participants the correct questions.
To conduct these interviews:
- Create a new research issue for tracking your interviews and results.
- Use the User Persona - Internal Stakeholder Script [Google Docs Template] and fill in the title and details with your persona.
- Link your Google Sheet in your issue.
- Use the GitLab team page, various department team pages (like the Engineering page), or put a message in a team’s slack channel (usually found near the bottom of a team page) to recruit internal participants for feedback.
- Use a Calendly link to schedule the 30 minute interview sessions.
- During each interview session:
- If you need to take notes, or have an additional note taker, use the user interview notes template.
- Summarize the interview data question by question to look for trends. Use the Persona - Screener Questions template to help guide what to look for.
- Document the summarized insights (including your screener questions) in the research issue, and ask stakeholders to review your data.
- Note whether any trends are different from what your stakeholders expected based on the previous research you conducted Step 1. If there are differences, then try to understand what assumptions were made and how to correct them.
Step 3: Validate user personas with users in the wider GitLab community
This is a critical step! The purpose of this step is to validate and prioritize the characteristics derived from our internal interviews and to establish the differences between our expectations and real-world findings. These moderated interviews should take approximately 1 hour. Recruit 8-10 participants for a given persona, focusing on participants who reflect the general makeup of the market. The goal of these interviews is to connect with our users and fill out the framework of our user persona with real user data.
A) Recruit & schedule participants
To kick off participant recruitment, refer to the UX handbook guide on how to recruit and schedule participants. Open a recruitment issue and use the screener derived from your previous research Step 2. Use the handbook page on writing screener questions for help, if needed.
B) Create Interview Script
Use the summarized information created from Step 1 and [Step 2 to craft the script for the external interviews. The first section of the script should focus on the top jobs of the persona, and the motivations and frustrations of those jobs.
If you are unfamiliar on GitLab’s JTBD, here is a small overview and guide
- The user’s objectives
- The tools and materials they use
- Understanding how they are evaluated on their job’s success
Later sections of the script may vary depending on what your past research indicates as important to the persona. You will most likely want to ask questions about key tools your persona uses, any areas of GitLab they use or have trouble in, or other teams that provide essential work to your persona.
C) Conduct interviews
After enough participants have been recruited and scheduled, it is time to conduct the interviews! To prepare for these interviews, be sure to understand GitLab’s handbook page on how to facilitate a user interview. More help can also be found in our discussion guide template.
To help streamline data intake during interviews, you may use this Persona Interview template (Google Form) as a script and tool to fill in participant responses.
To conduct these interviews:
- Create a new research issue for tracking your interviews and results.
- Use the User Persona - External Interviews Script (Google Form template) with your data from previous research. Use the form element as a method to read your script while recording the participant’s responses.
- Link your Google Sheet in your issue.
- During each interview session:
- Record the participant’s name and job title, and job description, and then read each question out loud, recording their answers in the form.
- If you need to take notes, or have an additional note taker, use the user interview notes template.
- Summarize the data in the Response tab of your Google Form, or export the data to a Google Sheet using the sheets export button.
- Document the summarized insights (including your screener questions) in the research issue, and ask stakeholders to review your data.
Step 4: Synthesize & Compare Results
A) Synthesize the user data
If you are using the Google Form template as described above, then the data synthesis will be a similar process for each round of research. If you need more help codifying the results, this handbook article on data synthesis may help.
For all open-ended questions, you first have to transform the qualitative data into something easier to understand. Do this by clustering responses into themes and tallying the counts of all themes. An example of this can be found in the table below:
| Question asked | Participant’s answer | Themes |
|---|---|---|
| What obstacles do you face when trying to accomplish the goals for your job? | Sometimes when I don’t see that a coworker has sent a merge request, it can take a while for me to approve it. | Missed communication |
For all close-ended questions, document the number of times each answer was given across all participants for each question to identify trends.
Once you have all answers counted, look at how many participants answered each question and evaluate the data for any trends. There are no set rules for this analysis, but some trends to look for include:
| Trend to look for | Example |
|---|---|
| 50% or more of participants selecting a small handful of answers | Answer A: 60% Answer B: 20% Answer C: 10% Answer D: 10% |
| A large drop off in certain answers compared to others | Answer A: 40% Answer B: 40% Answer C: 10% Answer D: 10% |
B) Compare Results
As you summarize each round of research, you can compare the answers from the previous participants to the most recent participants. If you see unexpected results, try to understand the reason for the differences and incorporate those into your final insights.
Step 5: Publish the new persona through a merge request
When all of the data has been collected and summarized, it’s time to update the Roles & Personas handbook page.
Copy the text from one of the already existing user personas, and paste it below the last persona that is currently filled out. Edit the information for the persona you have collected data on, and double check all of the information, including the name and title of the persona.
Assign the merge request to one of the managers found in the ‘Maintained By’ section on the same Roles & Personas page.
Keeping user personas up to date
The most common ways that personas become misaligned is when there is a business or technology change, or when there is a change to the user base. This helpful Nielsen Norman Group article goes into more detail on both of these if you are unsure on the difference or how to recognize them.
If stakeholders believe that a particular user persona no longer provides the information that it needs to, or if market data is indicating a change that impacts a persona, then it’s time to update an existing persona or create a new one.
Combining two or more personas
Personas that were originally independent from one another may become less distinct over time, either due to changes in roles or job duties. When stakeholders believe there are overlaps between two or more personas, there are some steps to follow prior to making a change.
- Stakeholders should collect all known information about the personas in question. For example, this can include interviews with customers or previously researched JTBD statements on a specific persona.
- All existing data about the personas should be mapped out, so that stakeholders can visualize all of the information at once. One way to assess the amount of overlap between personas is a Venn diagram.
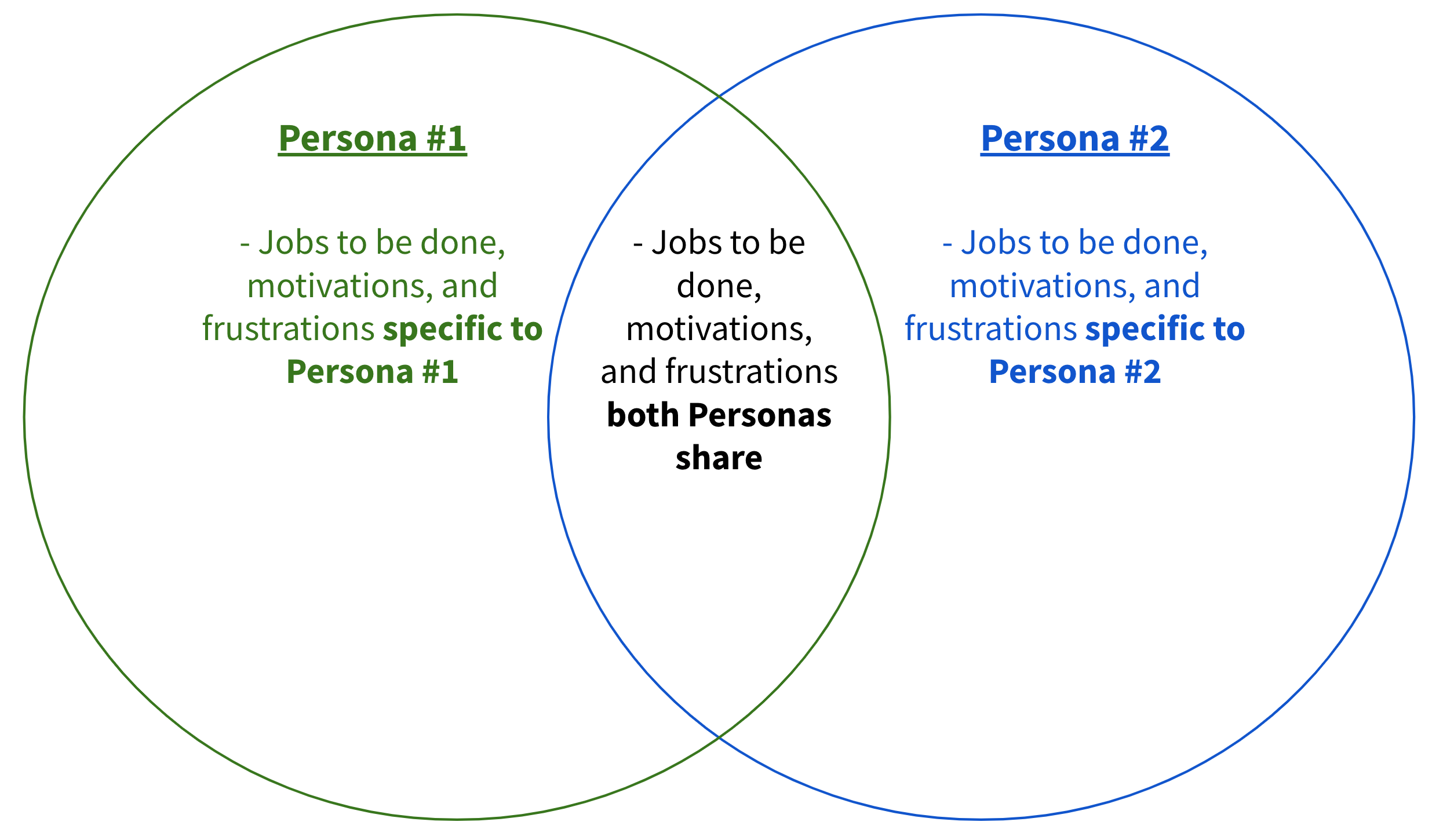
- There are some general guidelines to follow when creating your Venn diagram:
- If the number of bullet points (i.e., number of jobs to be done, motivations, and frustrations combined) that are similar between the personas in question are greater than the number of bullet points that are different, personas could be consolidated.
- If the number of bullet points that are similar between the personas in question are equal to the number of bullet points that are different, a new persona could be created.
- If the number of bullet points that are similar between the personas in question are less than the number of bullet points that are different, personas could be left unchanged.
- Based on the mapping exercise, stakeholders should consult with UX Research on the outcome of this mapping exercise to determine which direction to proceed (i.e., whether to combine existing personas together, leave personas as is, or create a new persona).
Frequently Asked Questions
How many personas should be used within a company? How many is too many?
There is no “correct” number of personas that a company should have. In general, personas should be distinct enough from one another, so that one persona is not easily mistaken for another. The more personas you have, the greater the chance that team members will not remember distinct information about them. A simple way to determine the number of personas within a company is to identify the most important user groups that you want to target with your product and create personas based on those groups.
Is a broader persona better or worse than a detailed one?
Personas should be detailed enough that they can be believable, but should be broad enough to represent specific types of user groups. The level of detail desired for personas will depend on the goal of the effort. Ideally, personas should be detailed enough to at least cover each of their goals, motivations, and frustrations.
When should personas be considered outdated? How often should personas be updated?
Personas should be evaluated over time to assess whether they represent the main types of users that were originally identified. Personas are seen as snapshots in time, so they can become outdated if you fail to consider changes in the business, marketplace, and demographics about your users. If you examine those factors and determine that there are differences between your data and current personas, additional research could be needed before you commit to update personas. If you need advice on potential research for personas, please consult with UX research for assistance.
There is no correct frequency for when to update personas, but companies should take into account time and resources needed to update personas (in addition to factors discussed above). Also, it is important to consider how much the product or user experience has changed since the persona was last researched. Generally, personas that have been stagnant for about 5 or more years might not be as valid as personas that are more up-to-date.
How much time should be spent to create personas?
External research looked into the amount of time that employees at large (more than 500 employees) organizations spent on creating user personas. Overall, there were differences in the amount of time it took to create personas when using non-empirical data (leveraging past data or knowledge about a user population) compared to empirical data (utilizing research efforts to learn about a user population). For projects that used non-empirical data, the amount of time needed to create personas was approximately 55 hours. For projects focused on obtaining empirical data, large companies needed approximately 102.5 hours to create personas.
88e02786)
