Package Stage
🎯 Mission and Vision
The Package stage integrates with GitLab’s CI/CD product.
Our mission is to create a secure environment where both source code and dependencies can live by
allowing you to publish, consume, and discover packages of a large variety of languages and platforms
all in one place.
For more details about the vision for this product area, see the product vision page.
Who We Are
The Package stage is made up of two groups:
- Package:Container Registry
- Package:Package Registry
Package:Container Registry
Package:Package Registry
📈 Measuring results
In order to better align our effort with our customer’s needs we will use the following methodology to measure our results. We believe that our best measure of success and progress is our product category maturity plan. Progress towards these goals will be measured as follows:
- The long term product category maturity goals will be split into each stage: minimal, viable, complete and, loveable
- For each category’s next maturity stage, we’ll break down each feature into small iterations and give them issue weights
- These weighted issues will have the
Package:P1 label applied then be scheduled in upcoming milestones
- We’ll measure our delivery by the percentage of committed product issues that were completed within a given development phase. Our goal is 100% completion. We track this measurement with a Say Do Ratio.
- We will resolve security vulnerabilities in a timely manner, based on severity.
- We will reevaluate our ability to deliver on our long term goals in each iteration.
Product maturity goals
The below epics detail the work required to move each respective category to the next maturity level.
OKRs
We use quarterly Objectives and Key Results as a tool to help us plan and measure how to achieve Key Performance Indicators (KPIs).
Here is the standard, company-wide process for OKRs
We measure the value we contribute by using performance indicator metrics. The primary metric used for the Package group is the number of monthly active users or GMAU. For more details, please check out the Ops section’s performance indicators.
Dashboards
We monitor our features using different dashboards. It is recommended to check them weekly.
These dashboards are all internal and can be only accessed by GitLab Team members.
Error Budget
Error Budgets for stage groups have been established in order to help groups identify and prioritize issues that are impacting customers and infrastructure performance. The Error Budget dashboard is used to identify issues that are contributing to the Package group’s error budget spend.
The Package::Package error budget peformance indicator is tracked and updated weekly.
The engineering manager will review the error budget dashboard weekly to determine whether we’re exceeding our budget, determine what (if anything) is contributing to our error budget spend, and create issues addressing root cause for product manager prioritization. Issues created to address error budget spend should be created using appropriate labels as well as the label Error Budget Improvement in order to facilitate tracking and measurement.
Usage Funnels
We expect to track the journey of users through the following funnel.
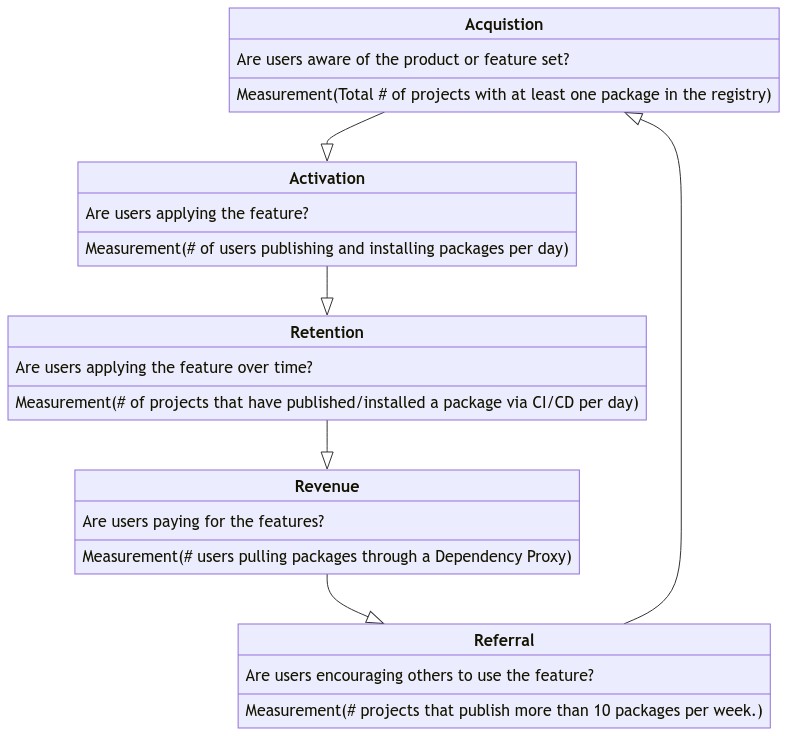
Follow along our instrumentation and measurement of Package-related metrics in gitlab-#2289.
Understanding our users
As a team, we are committed to understanding our users needs. We believe the best way to do that is by understanding the reason they hired GitLab, and how those motivations translate into our area of the product. For that, we apply a research-driven approach to Jobs to Be Done (JTBD) framework of innovation. This method aims to understand why a customer uses and buys a given solution. We apply the job statement to identify a list of specific, contextual user needs to fulfill their JTBD. In addition, we regularly evaluate the overall user experience of each JTBD, with UX Scorecards, to ensure that we are meeting the needs of our users.
JTBD
You can view and contribute to our current list of JTBD and job statements here.
Onboarding Enterprise customers
The GitLab Container and Package Registry currently handle hundreds of millions of events per week. However, when onboarding a large, enterprise customer it will be helpful for GitLab and the customer to understand their expected use case and workflows to ensure that the product scales reliably. When onboarding a new, large customer, it’s helpful to follow the below steps:
- Identify customer use cases and usage patterns;
- Estimate the expected number of events based on the above, broken down by type and action;
- Determine the percentage increase that the estimate above represents when looking at our current API request rate;
- Discuss with Infrastructure and Package engineers whether the expected increase might be problematic or not.
⏱ How we work
Roles and responsibilities
Our team emphasises ownership by people who have the information required. This means, for example, in the event of some discussion about UX considerations, our Product Designer will have ownership. When we’re building features, the Product Manager owns the decision on whether this is a feature that meets our customer needs. Our Engineers own the technical solutions being implemented.
The process of making sure that there are issues to evaluate and break down is the responsibility of our Product Manager. It is the responsibility of the engineering team to evaluate each issue and make sure it’s ready for development (using the workflow::ready for development label). It is the responsibility of our Product Designer to evaluate user experience and score our product maturity based on user research. This process will take some time to complete each time we achieve a new maturity stage. MR Rate will be used as an objective measure of our efficiency, not of alignment with our customer’s needs or our organizational goals.
Issue boards and projects
Issues for Package group can be found in the following projects:
- gitlab-org/gitlab - any issues for GitLab the product, this means all work and category issues.
- gitlab-com/www-gitlab-com - issues for any changes in handbook or blog
- Inside gitlab-org package-stage/package - any issues related to team organization, team styles, how we work, etc.
- package-combined-team/team (private) - any issues that don’t fit in the previous ones, and for major reasons, example, psychologically safe environment, we want to keep private to just the Package team members. Examples could be issues similar to retrospectives
To plan, visualize and organize better our work, we use the following issue boards:
Tips and Tricks
We have created a collection of Tips and Tricks for folks working with/around the Package Stage. You can view them on our Wiki Page.
Recurring meetings
| Meeting |
Purpose |
| Biweekly sync (rotate EMEA/APAC) |
Share news and information and provide an opportunity for people on the team to escalate concerns. |
| Retrospective (weekly) |
Discuss not only what went well or not but also how we did things and what we can do to improve for next week. |
| Think BIG (monthly) |
Discuss the vision, product roadmap, user research, design, and delivery around the Package solution. |
Retrospectives
The monthly Package retrospective takes place at the end of the milestone, following the process described in
the group retrospectives handbook page.
Follow-up and action items
Often times during a retrospective (monthly or weekly), there are suggestions on how to improve a given process. However, there are times
where suggestions are lost and no action is taken. Consider the following possible action items that can be created so that the issues are eventually addressed:
- Everything starts with a Merge Request! No matter if it is a small or big change, in the MR, you will have the opportunity to discuss the things you are suggesting with the rest of the team. Add the label
~Retrospective follow-up and relate the MR to the retrospective issue.
- For any other follow-up that cannot be resolved through an MR, open an issue in the Package retrospective issue tracker and apply the
~follow-up label. Assign a due-date to the next month. Link the issue back to the retrospective that prompted the action.
- Consider bringing some of the follow-up issues into the weekly retrospective for discussion.
- Follow the same process for issues raised during the weekly retrospective.
Missed deliverables retrospectives
When issues that we commit to delivering (have the Deliverable label) are not delivered in the milestone we commit to, we will hold an asynchronous retrospective on the miss to determine the root cause following the guidelines outlined in the handbook. In instances of a single issue, these retrospectives may be quite brief, in scenarios where we miss a larger effort, the root cause analysis will be more detailed. These should be conducted within the first week following the determination that we’ll miss the deliverable.
Standups
Async Daily Standups
The purpose of the daily standup is to allow team members to have visibility into what everyone else is doing, allow a platform for asking for and offering help, and provide a starting point for some social conversations. We use geekbot integrated with Slack.
While it is encouraged to participate in the full variety of daily questions, it is completely acceptable to skip questions by entering -.
The Geekbot asynchronous standup will be reserved for blocking items and merge announcements (merge parrot!).
Async Issue Updates
The purpose of daily updates is to inspect progress and adapt upcoming planned work as necessary. In an all-remote culture, we keep the updates asynchronous and put them directly in the issues.
The async daily update communicates the progress and confidence using an issue comment and the milestone health status using the Health Status field in the issue. A daily update may be skipped if there was no progress. It’s preferable to update the issue rather than the related merge requests, as those do not provide a view of the overall progress.
When communicating the health status, the options are:
on track - when the issue is progressing as plannedneeds attention - when the issue requires attention or intervention to keep it on scheduleat risk - when there is a risk the issue will not be completed according to schedule
The async update comment should include:
- what percentage complete the work is, in other words, how much work is done to put all the required MRs in review
- the confidence of the person that their estimate is correct
- notes on what was done and/or if review has started
- it could be good to include whether this is a front end or back end update if there are multiple people working on it
Example:
Complete: 80%
Confidence: 90%
Notes: expecting to go into review tomorrow
Concern: ~frontend
Include one entry for each associated MR
Example:
Issue status: 20% complete, 75% confident
MR statuses:
!11111 - 80% complete, 99% confident - docs update - need to add one more section
!21212 - 10% complete, 70% confident - api update - database migrations created, working on creating the rest of the functionality next
How to measure confidence?
Ask yourself, how confident am I that my % of completeness is correct?.
For things like bugs or issues with many unknowns, the confidence can help communicate the level of unknowns. For example, if you start a bug with a lot of unknowns on the first day of the milestone you might have low confidence that you understand what your level of progress is.
Epic weekly updates
A weekly async update should be added to epics related to quarter goals and to epics actively being worked on. The update should provide an overview of the progress across the feature. Consider adding an update if epic is blocked, if there are competing priorities, and even when not in progress, what is the confidence level to deliver by the end of the milestone/quarter. A weekly update may then be skipped until the situation changes. Anyone working on issues assigned to an epic can post weekly updates. At the beginning of the quarter, we look for a DRI for a feature, and they should be responsible for the parent epic updates.
Slackbot has been configured to send reminders to #s_package
The epic updates communicate a high level view of progress and status for quarterly goals using an epic comment. It does not need to have issue or MR level granularity because that is part of each issue updates.
The weekly update comment should include:
- Status: ok, so-so, bad? Is there something blocked in the general effort?
- How much of the total work is done? How much is remaining? Do we have an ETA?
- What’s your confidence level on the completion percentage?
- What is next?
- Is there something that needs help/support? (tag specific individuals so they know ahead of time)
Examples
Some good examples of epic updates that cover the above aspects:
Workflow
We generally follow the Product Development Flow:
workflow::problem validation - needs clarity on the problem to solve. Our Product Manager owns the problem validation backlog and problem validation process as outlined in the Product Development Workflow.workflow::design - needs a clear proposal (and mockups for any visual aspects).workflow::solution validation - designs need to be evaluated by customers, and/or other GitLab team members for usability and feasibility. Our Product Designer then owns the solution validation process. You can view all items and their current state in the Package: Validation Track issue board.workflow::refinement - needs a weight estimate and clarification to ensure an issue is ready for development. At the end of this process, the issues will be ready for the build track which is owned by the Engineers and lives in the Package:Workflow issue board.workflow::ready for developmentworkflow::in devworkflow::in reviewworkflow::verification - code is merged and pending verification by the DRI engineer.workflow::staging - code is in staging and has been verified.workflow::complete - the work is in production and has been verified. The issue is closed.
The Product Manager owns the process of populating the current milestone work following the prioritization guidelines. Engineers are empowered, once the planned work has been exhausted, to prioritize issues that will deliver customer value preferring smaller issues over larger ones.
Issues that we’re expecting to work on in the milestone will have the workflow::ready for development label added to them. Once labeled, they’ll appear in the Package:Workflow board. As engineers begin working on the issue, they’ll assign the workflow::in dev label.
Milestone Planning
- Our Product Manager, Product Designer, and Engineering Manager develop a plan for upcoming milestones.
- The PM creates an issue for milestone planning that includes the goals, priorities and work for the milestone. The milestone planning issues can be found in our Milestone Planning Epic.
- Everyone can contribute and collaborate in the milestone issue to propose work, raise concerns and clarify topics.
- To identify work and their priority, issues are assigned to the milestone and labelled as
Package:P1 or Package:P2 according to their priority. Our prioritization model can be found below in the section Priorities.
- Before commiting to the work for the milestone, engineers perform refinement and confirm all issues are ready for development.
- We commit to the
Package:P1 work in the milestone by having an engineer add the workflow::ready for development label and then having the engineering manager add the Deliverable label. We measure our predictability and commitments with Say/Do ratios.
Refinement
We follow the Product Development Flow. After problem and solution validation are complete, the next step is refinement, where engineers break down requirements and present a high-level MVC and feasible estimated solution.
Any issues needing refinement are labeled workflow::refinement. This label can be added by anyone throughout the issue lifecycle.
Issues that will likely be scheduled for implementation in the current quarter must have both the quarter label (e.g. FY23::Q3) and workflow::refinement. Having both labels makes issues that will soon be refined by engineers discoverable for the product designer. The product designer ensures the issue is still relevant, the issue description is complete, and the designs are up-to-date.
The product manager will determine issues that need to be refined by the engineers in the upcoming milestone and apply the label workflow::refinement. The expectation is by the end of the milestone, all of those issues have been refined by the engineers and move to workflow::ready for development.
To drive refinement, we use a randomly assigned refinement DRI. The refinement DRI is not necessarily the person completing the refinement tasks, but is responsible for ensuring they are completed within the assigned milestone.
Before the milestone starts:
- The product manager determines which issues need to be refined by engineers and applies the
workflow::refinement label
- Issues needing to be refined are listed on the milestone planning issue
When the milestone starts:
- The product manager, engineering manager, or product designer randomly assigns refinement issues to DRIs.
Before the milestone is finished:
- The engineers refine each issue with the label
workflow::refinement from the milestone planning issue
- When refinement is complete, each issue is moved to
workflow::ready for development
Refinement guidelines:
- Identify and resolve outstanding questions or discussions.
- Does the issue has a clear, updated, and confirmed design associated?
- Does the issue contains all the data necessary to start implementation?
- Identify missing dependencies.
- Is the issue dependent on any other issue in the milestone, or the dependency is explicitly communicated, noted in the description and the issue is linked?
- The GraphQL API or the REST API contains all the data necessary to implement the UI?
- The GraphQL API or the REST API implements all the necessary filters, sorting, and pagination to implement the UX?
- The GraphQL API or the REST API contains all the necessary mutation/actions to implement the UX?
- Raise any questions, concerns, or alternative approaches.
- Could this issue be resolved in different ways?
- What is the biggest risk?
- Involve stable counterparts.
- The impact on QA and Feature tests of this issue is clear and, if necessary, the SET stable counterpart is involved in reviewing them?
- The impact on security of this issue is clear, and if necessary, a stable counterpart is involved?
- Outline an implementation plan.
- What is the smallest thing possible to do?
- Should we use a feature flag?
- Assign labels.
- Assign a weight to the issue according to weighting guidelines.
- Create any follow-up issues that come out of refinement
Milestone Priorities
Throughout the workflow, issues should be addressed in the following priority order:
- Sustaining work: Based on the product prioritization framework,
bug::vulnerability, availability, infradev, Corrective Action, and ci-decomposition::phase* issues will be at the top of our Package:Milestones Board.
Package:P1 label: Used to identify high priority issues that should be committed to in a given milestone or scheduled in an upcoming milestone.Community Contribution label: When in the milestone planning, this identifies community contributions we committed to delivering in a given milestone.Package:P2 label: Used to stretch goals for a given milestone.workflow::refinement label: These are issues that require weighting, feedback, and scheduling before being moved to workflow::ready for development.
Issue Weighting
| Weight |
Description |
| 1: Trivial |
The problem is very well understood, no extra investigation is required, the exact solution is already known and just needs to be implemented, no surprises are expected, and no coordination with other teams or people is required.
Examples are documentation updates, simple regressions, and other bugs that have already been investigated and discussed and can be fixed with a few lines of code, or technical debt that we know exactly how to address, but just haven’t found time for yet.
This will map to a confidence greater or equal to 90%. |
| 2: Small |
The problem is well understood and a solution is outlined, but a little bit of extra investigation will probably still be required to realize the solution. Few surprises are expected, if any, and no coordination with other teams or people is required.
Examples are simple features, like a new API endpoint to expose existing data or functionality, or regular bugs or performance issues where some investigation has already taken place.
This will map to a confidence greater than or equal to 75%. |
| 3: Medium |
Features that are well understood and relatively straightforward. A solution will be outlined, and most edge cases will be considered, but some extra investigation will be required to realize the solution. Some surprises are expected, and coordination with other teams or people may be required.
Bugs that are relatively poorly understood and may not yet have a suggested solution. Significant investigation will definitely be required, but the expectation is that once the problem is found, a solution should be relatively straightforward.
Examples are regular features, potentially with a backend and frontend component, or most bugs or performance issues.
This will map to a confidence greater than or equal to 60%. |
| Larger: resize |
Features that are well understood, but known to be hard. A solution will be outlined, and major edge cases will be considered, but extra investigation will definitely be required to realize the solution. Many surprises are expected, and coordination with other teams or people is likely required.
Bugs that are very poorly understood, and will not have a suggested solution. Significant investigation will be required, and once the problem is found, a solution may not be straightforward.
Examples are large features with a backend and frontend component, or bugs or performance issues that have seen some initial investigation but have not yet been reproduced or otherwise “figured out”.
This will map to a confidence greater than or equal to 50%. |
Issue size
Anything larger than 3 should be broken down. Anything with a confidence percentage lower than 50% should be investigated prior to finalising the issue weight.
Our intention is to break up issues that have a weight greater than 3, either by converting the issue to an epic with sub issues or just separating the work into related issues. An issue weight of 3 should describe something that would take no more than 2 weeks to complete.
When starting work on an MR that involves unfamiliar tools/libraries, be sure to update the estimated weight depending on who picks up the issue to reflect the additional time that may be spent learning. For example, a developer who has never worked with GraphQL before may need to spend some additional time learning the library versus a developer who has experience with GraphQL. If the first developer picks up the issue, they should consider raising the weight so it is reflected that it may take longer for them to deliver it.
Refactoring
When working on an MR for a Deliverable, don’t lose track of the aim: release the Deliverable in time. That doesn’t mean that refactorings can’t happen or that we can’t take time to investigate side subjects. It means that we need to limit the time allocated for this type of work.
When considering a refactoring or a heavy refactoring, consider working iteratively. A refactoring can be implemented and refined many times but consider releasing a good enough first version so that depending work is not delayed or blocked. For an example of how we can work iteratively, please see how we worked through lifting the npm naming conventioon.
Bug Triaging
Investigation
A bug investigation is a two part process:
- Reproduce the bug locally with the same conditions as described in bug issue.
- Analyze the possible fix and its complexity.
At the end of this process, the engineer should be able to weight the issue.
The whole process can take a few minutes to several hours (or even days). The assigned engineer should timebox this process to avoid investing too much time in it, without communicating and coordinating with EM and PM, and thus hindering the milestone planning. We suggest that anything that goes above half a day should be coordinated with the team.
If a bug investigation takes more time than intended, it’s better to:
- Stop the investigation.
- Post the current situation in the issue.
- Inform the Engineering Manager and the Product Manager that will plan more time for the investigation.
Bug detection
When a bug is detected on staging, engineers should evaluate its severity will be on production. You can use kibana or other tools to evaluate the number of requests impacted. If the severity is high, appropriate actions should be taken.
In particular, when the most used package registries (npm, Maven) are impacted negatively, consider the bug a higher severity. If the bug disrupts the expected behavior of those package registries, consider blocking the next production deployment with the appropriate actions above.
Testing
To best understand how users use the GitLab package registry, when building and testing features, it is beneficial to test using projects that resemble real use-case scenarios. A Hello-World package is not going to simulate the same functionality that a large open source library or enterprise customer is going to experience. Depending on the feature that is being built, it is recommended during the development phase to test locally using a real package. Additionally, consider reviewing existing data to determine a good range of test cases. The package group has created an ad-hoc test projects group to store larger projects that can be used to test against. This group may contain copies of open source projects or projects specifically designed to test certain aspects of the GitLab package registry. It is not meant to be a static collection of projects, so the projects may be replaced, updated, or removed as seen fit.
File uploads
Package’s features regularly deal with file uploads. When testing these features locally using an environment like GDK, it is recommended to test changes using the default local storage configuration, but also using a cloud service for object storage. GCP is recommended when trying to best recreate the environment GitLab.com is running. For highest confidence in features working with uploads, testing using local storage, Minio, GCP, AWS S3, and Azure is recommended. The GDK docs have instructions on how to configure for each of these providers.
End to End Testing
The Package team uses GitLab QA for End-to-End testing. We have guidelines for how our team is leveraging these tests.
HackyStack
HackyStack is an open source cloud infrastructure management and orchestration platform for ephemeral demo, sandbox, testing, and training environments.
The GitLab Sandbox Cloud is GitLab’s deployment of HackyStack that is used by GitLab team members. See the handbook page for more details.
The Package team uses this platform to set up its epehemeral demo sandbox environment that launches an Omnibus instance with an active Container Registry and a project that can trigger multiple images/tags leveraging our CI capabilities.
Instructions on how to use it can be found here.
Seeding Utilities
We have two utilities we make use of when seeding Container Registries for testing purposes:
Code Review
Code reviews follow the standard process of using the reviewer roulette to choose a reviewer and a maintainer. The roulette is optional, so if a merge request contains changes that someone outside our group may not fully understand in depth, people are encouraged to ask for a preliminary review from members of the package group to focus on correctly solving the problem. The intent is to leave this choice to the discretion of the engineer but raise the idea that fellow package group members will sometimes be best able to understand the implications of the features we are implementing. The maintainer review will then be more focused on quality and code standards.
This tactic also creates an environment to ask for early review on a WIP merge request where the solution might be better refined through collaboration and also allows us to share knowledge across the team.
UI or Technical Writing Review
When a merge request needs to be reviewed for the experience or for the copy in the user interface, there are a few suggestions to ensure that the review process is quick and effecient:
- When the MR has a UX or copy review, we suggest initating that part of the review process first to avoid experience changes in the middle of code reviews.
- A Product Designer will review the UX and UI text, following the MR review guidelines. If there is substantial change, the Product Designer may bring in a Technical Writer for a more thorough copy/content related review.
- If the Technical Writer is unavailable and the MR is being slowed down, it is possible to create a follow up issue for the copy or documentation to be reviewed post-merge. This should be avoided when possible.
Quality
The Package team has a goal of shipping enterprise grade software with a focus on Quality. The team accomplishes this goal with the following practices:
Picking up an issue
If a community contributor wants to pick up an issue, or create an issue and a follow up merge request for it, please ping @gitlab-org/ci-cd/package-stage or an individual team member on the issue itself before starting the work, this ensures that:
- The issue will not conflict with other work of the team
- The issue will have feedback and advice from a team member
- The issue is well defined enough to be used as a validation of the merge request
Additionally, the Package team can help set realistic review/merge times based on the scope of the work.
Ultimately the aim is to enable community contributor to deliver meaningful work with the least amount of back and forth and minimising the risk of stumbling on a show stopper.
Definition
A merge request with the following properties:
- It impacts features or issues managed by the Package group. This means it has the
devops::package label
- Contributed by anyone in the wider community or at GitLab who isn’t part of the Package group
- Contributed by a team member who doesn’t work in the same functional area (Frontend engineer contributing to Backend code)
Handling community contributions
A Package group member will adopt the community contribution with the following tasks:
- Confirm the community merge request (MR) is properly triaged. This step includes important labeling for work type classification, stage and group and the
Community Contribution label.
- If the MR addresses an open issue, ensure that the issue is still valid and the description is up to date. Consider closing the issue and closing the MR if it is outdated.
- Evaluate the review effort and assign it using
package-review-weight::x labels.
- Consider reaching out to MR coaches or using the reviewer roulette to leverage support and provide contributors with a smoother and quicker experience.
- Assign themselves to the issue. This helps to identify a DRI for that issue in the milestone planning.
- Assign the community contributor to the issue. Note that this can only be done with quick actions
/assign @contributor.
- Assign the current milestone to the issue. This facilitates milestone planning and tracking.
- Assign the current milestone to the merge request.
- Make sure that the issue has the proper labels including work type, categories, etc. Do not forget to apply
workflow::in dev to signal that the issue is already in development.
- Make sure that the merge request has the proper labels. You can use
/copy_metadata quick action to copy the labels from the issue.
- Set aside some time per week to assist and coach the community contributor.
- Make sure that the effort is reviewed by the product manager and the product designer.
- Make sure that the reviews are happening. The team member can even suggest reviewers.
Prioritisation
- Effort to support community contributions can range from weekly check ins to active contribution. As an organisation, GitLab values our community and the idea that everyone can contribute. As such, effort contributed to community contributions can range from simply checking in with the author to contributing actively. While this effort doesn’t prevent us from delivering on our
Package:P1 issues, we should invest the time necessary to make sure the author is able to contribute.
Scheduling
Given the number of community contributions submitted (thank you!), the Package team will include them in Milestone Planning issues. We’ll schedule time for team members to assist with the various community contributions as part of our milestone plan. You can view guidelines for merge requests and a definition of done here.
The Package team will add review weight labels to community contributions to try to help understand the required effort and plan capacity. The intention is to help the team better plan for the support of community contributions among other priorities. We’ll start with labels for weights of 1, 2, 3, and 5 similar to the weights we use for our issues. The only difference is that a package-review-weight::5 won’t be replaced with an investigation.
Other points to consider for the Package group member:
- The coaching can range from commenting/reviewing the merge request to pair programming through Zoom.
- Contributing to features managed by the Package group can mean having to use the Enterprise Edition (EE) version of GitLab. This guideline will help with this aspect.
- Make sure that the merge request size and complexity stay at a reasonable level to ensure a smooth review process.
- If the merge request grows to an unexpected size or tries to solve too many issues at once, consider suggesting to the community contributor to split it into smaller ones and use a feature flag if necessary.
- If a merge request gets stalled for a long time, consider suggesting that you will finish the merge request. Check the proper section in Merge Request Coach responsibilities.
- Do not forget to credit the community contributor.
- If some aspects of the merge request become a high priority task (for example, a bug fix) and the work from the community contributor is less active or stalled, consider suggesting that you will extract this part to a small merge request to get it implemented as quickly as possible.
- The other aspects with less priority can still be worked out by the community contributor.
Deliverable issues
An issue that has the ~Deliverable label is expected to be completed within the assigned milestone. However, if a community member wants to work on that issue, it may seem unfair to assign the issue to them and expect them to deliver the changes by a given date.
In this scenario, the team member co-assigned to the issue will be responsible for working with the community contributor to try to deliver the changes needed in time.
If at any point in time the MR is stale or the contributor is unresponsive, the team member will follow the taking over a community merge request process outlined in the contributing guidelines.
If a community member acknowledges that they still want to work on a ~Deliverable issue
in the current or next milestone, the team will discuss and decide
whether or not this will effect the ability to ship the issue in the scheduled milestone.
To prevent these situations, the best action we can take is to proactively remove the
~Accepting contributions label when we schedule an issue as a deliverable.
Three actions could be taken:
- We kindly let the community contributor know that this issue needs to be
completed by internal team members.
- We allow the community contributor to work on the issue but let them know
that an internal team member may need to take over the MR at some point to
ensure it ships on time.
- We decide it is ok for this issue to slip, allow the community contributor
to work on the issue, and remove the
~Deliverable label.
If a community member has been working on a previously unscheduled issue that we would
like to schedule, we should do our best to make option (2.) work. If either option (1.)
or (2.) is taken, we should ensure the community contributor receives recognition for their
work.
For issues that are not scheduled as deliverables, we may still schedule reviews
and support for the community contributor in the given milestone, but without
committing to delivering it in a specific time frame.
Returning from PTO
It can be overwhelming to come back to work after taking time off. Remember to review the returning from PTO
section of our time-off policy, especially the key points:
- It is OK to take your time to catch up. You can consider blocking your calendar to do so.
- Taking time off doesn’t mean that you need to work extra hours before or after your vacation.
- It is impossible to know everything (AKA some things can be ignored).
- Consider scheduling a coffee chat or sync with other team members to help ease your way back.
- Consider asking in #s_package for a summary of what happened while you were gone.
Technical Knowledge Sharing Sessions
Team members are encouraged to organize periodic sessions where a volunteer member hosts a meeting to demonstrate, describe, or brainstorm various technical aspects. Topics may include development tools and techniques, tours of specific parts or functionalities of the GitLab applications, or discussions about problems and the thought process behind implementation decisions.
These sessions aim to facilitate the sharing of valuable insights and experiences among team members, strengthen team bonds, engage participants in thoughtful discussions, and encourage collective problem-solving.
Target Audience
These sessions are applicable to all development specialties (backend, frontend, Go, and Rails) across Package:Container Registry and Package:Package Registry. By making these sessions visible and open to engineers across all functional areas, the goal is to boost awareness and knowledge sharing across a wider audience. Members with non-development roles are also more than welcome to attend.
Process
- While there is no strict frequency requirement, team members are encouraged to hold at least one session per month for the entire team.
- To ensure efficiency and engagement, each session should be timeboxed to 30 minutes.
- Any team member can volunteer to present on a topic of their choice.
When hosting a session, the team member should:
- Create an issue under the Technical Knowledge Sharing Sessions epic. The issue should provide a brief description of the topic to be presented.
- Add an event for the session to the Package Stage Calendar, along with a link to the issue above to make other team members aware of the event.
- Host the session and ensure it is recorded.
- If any potentially sensitive information is mentioned or revealed during the session (such as demonstrating the debugging of a customer-reported issue), the recording should be kept private.
- At the end of the session, add the link to the recording to the session issue and close it.
- Any follow-up issues created out of the session should be related to the session issue for traceability and additional context.
- If possible, make the recording publicly available and list it under Demos & Speedruns.
🤝 Collaboration
Cross-Group Dependencies
Cross-group dependencies may exist as pre-requisites to deliver Package features or bug fixes. Issues to deliver such dependencies are owned by groups that Package depends on, such as Delivery or Distribution.
For discoverability, issues that represent cross-group dependencies should be labeled with package:cross-group-dependency. If working on one of these issues, Package engineers should ensure that they are labeled correctly. For visibility, these issues are shown in the Package:Cross-Group Assignments issue board.
The product manager should include cross-group dependencies in the milestone planning issue for review, discussion and prioritization.
Communication
We’re an all-remote group, effective and asynchronous communication is key for success.
When requiring attention from all the team members, use any of the following options or mix them.
- Ping the team using
@package-combined-team only once in an issue - When there will be multiple interactions and actions required. Consider this as the way to bring the issue to team members’ attention. For example, when a milestone planning issue is ready for team members to review and give feedback, and multiple actions could come up later in the conversations.
- Include a checklist for each team member in the description of the issue - When there is an action required for each team member and is required to track when the action is completed. For example, in training issues.
- Assign team members to the issue - When there is an action required for each team member. The expectation is that team members will unassign themselves when they complete the action requested, for example, in retrospective or training issues.
- For announcements (FYI), we prefer to share the message on Slack. For purposes of searching and historical information, we include the announcement also in the weekly sync agenda. For example, when new Production Change Lock (PCL) dates are announced.
For any other communication tailored to only certain members, we ping them individually on issues.
Partnering with Infrastructure
There are times during the development lifecycle that changes need to be communicated to the Infrastructure teams. For example:
Feature Category Details
🔗 Other Useful Links
Roadmap
Demos & Speedruns
Package Registry
Container Registry
Dependency Proxy
Dependency Firewall
Nexus Repository OSS (competitor product)
Overview The goal of this page is to document how the package group uses the GitLab QA framework (video walkthrough) to implement and run end-to-end tests. It also provides instructions on how to use HackyStack for demo purposes.
Supporting slides for the above tutorial
Why do we have them End-to-end testing is a strategy used to check whether your application works as expected across the entire software stack and architecture, including the integration of all micro-services and components that are supposed to work together.
Overview The goal of this page is to create, share and iterate the Risk Map for the Package team.
Goals Utilise the Risk Map as a tool to:
Understand the risks the team faces Increase transparency on mitigation plans Plan and prioritize effectively Collaborate strategically in improving Quality Risk Mapping Project The project documents Package’s risks as issues and its home to the Risk Mapping Tool.
Tool Open on the Risk Mapping website.
Overview The goal of this page is to create, share and iterate on the Jobs to be Done (JTBD) and their corresponding job statements for the Package stage. Our goal is to utilize the JTBD framework to better understand our buyers’ and users’ needs.
Goals Utilize JTBD and job statements to:
Understand our users’ motivations. Validate identified use cases and solutions. Continuously test and iterate features to ensure we are meeting our customers’ and users’ needs.
The Team The Container Registry is part of the GitLab Package stage, which integrates with GitLab’s CI/CD product.
Who We Are Team Members The following people are permanent members of the Container Registry Group:
Name Role Crystal Poole Senior Engineering Manager, Package Backend Engineer Backend Engineer, Package:Container Registry Hayley Swimelar Senior Backend Engineer, Package:Container Registry Jaime Martínez Senior Backend Engineer, Package:Container Registry João Pereira Staff Backend Engineer, Package:Container Registry Rahul Chanila Senior Frontend Engineer, Package:Container Registry Backend Engineer Backend Engineer, Package:Container Registry Stable Counterparts The following members of other functional teams are our stable counterparts:
📦 The Team The Package Registry is part of the GitLab Package stage, which integrates with GitLab’s CI/CD product.
Who We Are Team Members The following people are permanent members of the Package Registry Group:
Name Role Crystal Poole Senior Engineering Manager, Package David Fernandez Staff Backend Engineer, Package:Package Registry Dzmitry Meshcharakou Senior Backend Engineer, Package:Package Registry Moaz Khalifa Backend Engineer, Package:Package Registry Rad Batnag Senior Backend Engineer, Package:Package Registry Stable Counterparts The following members of other functional teams are our stable counterparts:
 Crystal Poole
Crystal Poole Hayley Swimelar
Hayley Swimelar Jaime Martínez
Jaime Martínez João Pereira
João Pereira Backend Engineer
Backend Engineer David Fernandez
David Fernandez Dzmitry Meshcharakou
Dzmitry Meshcharakou Moaz Khalifa
Moaz Khalifa Rad Batnag
Rad Batnag