
Managing storage space on large GitLab instances, such as GitLab.com, can be a challenge. At the moment, we only have a restriction on repository limits, but no restriction on most of the other items that can consume storage space: wiki, lfs objects, artifacts, and packages, to mention a few.
We want to facilitate a method for easily viewing the amount of storage consumed by a group and allow easy management on GitLab.com by setting storage and limits management for groups. But to do that we need a way to track the statistics of a namespace, whether it is a Group or a User namespace.
Proposal to track the statistics of a namespace
- Create a new ActiveRecord model to hold the namespaces' statistics in an aggregated form: Only for root namespaces.
- Refresh the statistics in this model every time a project belonging to this namespace is changed.
The "refresh" part is the tricky one. Currently we don't have a pattern to update/refresh the namespace statistics every time a project belonging to the namespace is updated.
We refreshed projects statistics in the following way:
- We have a model called
ProjectStatistics, - The records on
ProjectStatisticsare updated through a callback every time the project is saved. - The summary of those statistics per namespace is then retrieved by
Namespaces#with_statisticsscope.
Analyzing this query we noticed that:
- It takes up to
1.2seconds for namespaces with over15 000projects. - Any attempt to run
EXPLAIN ANALYZEresults in query timeouts (15 seconds) when using our internal tooling.
Additionally, the callback to update the project statistics doesn't scale. It is currently one of the most frequently run and expensive database queries on GitLab.com. We can't add one more query to it as it will increase the transaction's length.
Because of these reasons, we can't apply the same pattern to store
and update the namespaces' statistics, as the namespaces table is one
of the largest tables on GitLab.com. Therefore, we have to find a performant and
alternative method.
Our Attempts
Attempt A: PostgreSQL materialized view
Update the ActiveRecord model with a refresh strategy based on project routes and a materialized view:
SELECT split_part("rs".path, '/', 1) as root_path,
COALESCE(SUM(ps.storage_size), 0) AS storage_size,
COALESCE(SUM(ps.repository_size), 0) AS repository_size,
COALESCE(SUM(ps.wiki_size), 0) AS wiki_size,
COALESCE(SUM(ps.lfs_objects_size), 0) AS lfs_objects_size,
COALESCE(SUM(ps.build_artifacts_size), 0) AS build_artifacts_size,
COALESCE(SUM(ps.packages_size), 0) AS packages_size
FROM "projects"
INNER JOIN routes rs ON rs.source_id = projects.id AND rs.source_type = 'Project'
INNER JOIN project_statistics ps ON ps.project_id = projects.id
GROUP BY root_path
We could then execute the query with:
REFRESH MATERIALIZED VIEW root_namespace_storage_statistics;
While this implied a single query update, it has some downsides:
- The query itself would not be fast, as it would need to update all the statistics every time it runs. Execution time of this query will increase as the number of namespaces and projects grow.
- Materialized views syntax varies from PostgreSQL and MySQL. At the time this feature was worked on, GitLab still supported MySQL, which it now no longer supports..
- Rails does not have native support for materialized views. We'd need to use a specialized gem to take care of the management of the database views, which implies additional work.
Attempt B: An update through a CTE
Update the ActiveRecord model with a refresh strategy through a Common Table Expression.
WITH refresh AS (
SELECT split_part("rs".path, '/', 1) as root_path,
COALESCE(SUM(ps.storage_size), 0) AS storage_size,
COALESCE(SUM(ps.repository_size), 0) AS repository_size,
COALESCE(SUM(ps.wiki_size), 0) AS wiki_size,
COALESCE(SUM(ps.lfs_objects_size), 0) AS lfs_objects_size,
COALESCE(SUM(ps.build_artifacts_size), 0) AS build_artifacts_size,
COALESCE(SUM(ps.packages_size), 0) AS packages_size
FROM "projects"
INNER JOIN routes rs ON rs.source_id = projects.id AND rs.source_type = 'Project'
INNER JOIN project_statistics ps ON ps.project_id = projects.id
GROUP BY root_path)
UPDATE namespace_storage_statistics
SET storage_size = refresh.storage_size,
repository_size = refresh.repository_size,
wiki_size = refresh.wiki_size,
lfs_objects_size = refresh.lfs_objects_size,
build_artifacts_size = refresh.build_artifacts_size,
packages_size = refresh.packages_size
FROM refresh
INNER JOIN routes rs ON rs.path = refresh.root_path AND rs.source_type = 'Namespace'
WHERE namespace_storage_statistics.namespace_id = rs.source_id
Unlike Attempt A, a CTE will be limited to the namespace we care about instead of operating on all namespaces. The downside of it, is that earlier versions of MySQL do not support Common Table Expressions.
Attempt C: Get rid of the model and store the statistics on Redis
We could get rid of the model that stores the statistics in aggregated form and instead use a Redis Set. This would be the boring solution and the fastest one to implement, as GitLab already includes Redis as part of its Architecture.
The downside of this approach is that Redis does not provide the same persistence/consistency guarantees as PostgreSQL, and the namespace statistics are information we can't afford to lose in a case of a Redis failure. Also, searching for information like the largest namespaces per repository size will be easier to do in PostgreSQL than in Redis.
Attempt D: Tag the root namespace and its child namespaces
Directly relate the root namespace to its child namespaces, so whenever a child namespace is created, it's also tagged with the root namespace ID:
| id | root_id | parent_id |
|---|---|---|
| 1 | 1 | NULL |
| 2 | 1 | 1 |
| 3 | 1 | 2 |
To aggregate the statistics inside a namespace we'd execute something like:
SELECT COUNT(...)
FROM projects
WHERE namespace_id IN (
SELECT id
FROM namespaces
WHERE root_id = X
)
Even though this approach would make aggregating much easier, it has some major downsides:
- We'd have to migrate all namespaces by adding and filling a new column. Because of the size of the table, dealing with the time/cost will not be great. The background migration will take approximately 153 hours.
- The background migration has to be shipped one release before we want to start using the new data, delaying the functionality by another milestone.
Attempt E: Update the namespace storage statistics asynchronously
For this approach we continue using the incremental statistics updates we already have, but we refresh them through Sidekiq jobs and in different SQL transactions:
- Create a second table (
namespace_aggregation_schedules) with two columnsidandnamespace_id. - Whenever the statistics of a project changes, insert a row into
namespace_aggregation_schedules- We don't insert a new row if there's already one related to the root namespace.
- Keeping in mind the length of the transaction that involves updating
project_statistics, the insertion should be done in a different transaction and through a Sidekiq Job.
- After inserting the row, we schedule another worker to be executed async at two different moments:
- One enqueued for immediate execution and another one scheduled in
1.5hhours. - We only schedule the jobs if we can obtain a
1.5hlease on Redis on a key based on the root namespace ID. - If we can't obtain the lease it indicates there's another aggregation already in progress or scheduled in no more than
1.5h.
- One enqueued for immediate execution and another one scheduled in
- This worker will:
- Update the root namespace storage statistics by querying all the namespaces through a service.
- Delete the related
namespace_aggregation_schedulesafter the update.
- Another Sidekiq job is also included to traverse any remaining rows on the
namespace_aggregation_schedulestable and schedule jobs for every pending row.- This job is scheduled with cron to run every night (UTC).
This implementation has the following benefits:
- All the updates are done async, so we're not increasing the length of the transactions for
project_statistics. - We're doing the update in a single SQL query.
- It is compatible with PostgreSQL and MySQL.
- No background migration is required.
The downsides of this approaches are:
- Namespaces' statistics are updated up to
1.5hours after the change is done, which means there's a brief window in time where the statistics are inaccurate. This is not a major problem because we're not currently enforcing storage limits. - From the implementation perspective, this approach is more complex than the migration approach (Attempt D).
namespace_aggregation_schedulestable will see a high rate of inserts and deletes, which may require that we tune auto vacuuming for this table.
We went with Attempt E because updating the storage statistics asynchronously was the less problematic and performant approach of aggregating the root namespaces.
Enabling the feature on GitLab.com
Given this is a performance improvement, we have to be very careful introducing this change to GitLab.com: Which is why we decided to release it under feature flag and roll it out gradually by:
- Enable it on our staging environment and measure the performance.
- Enable it on GitLab.com on different periods for the
gitlab-orggroup and measure the performance. - Enable it globally on GitLab.com on different periods and measure the performance.
Finally if no problem arises, we can be confident this change performs properly on GitLab.com and we can remove the feature flag.
Measuring the performance
To assess the execution of this approach, we monitored the Sidekiq dashboards on Kibana to ensure jobs were being executed flawlessly and without using too much memory or CPU. Particularly, we observed the "Sidekiq queue size," "Rate of running jobs," and "Running jobs" dashboards.
On staging
The feature was enabled globally on staging and the execution of the jobs was satisfactory. But there was barely any traffic to measure the impact of our changes:
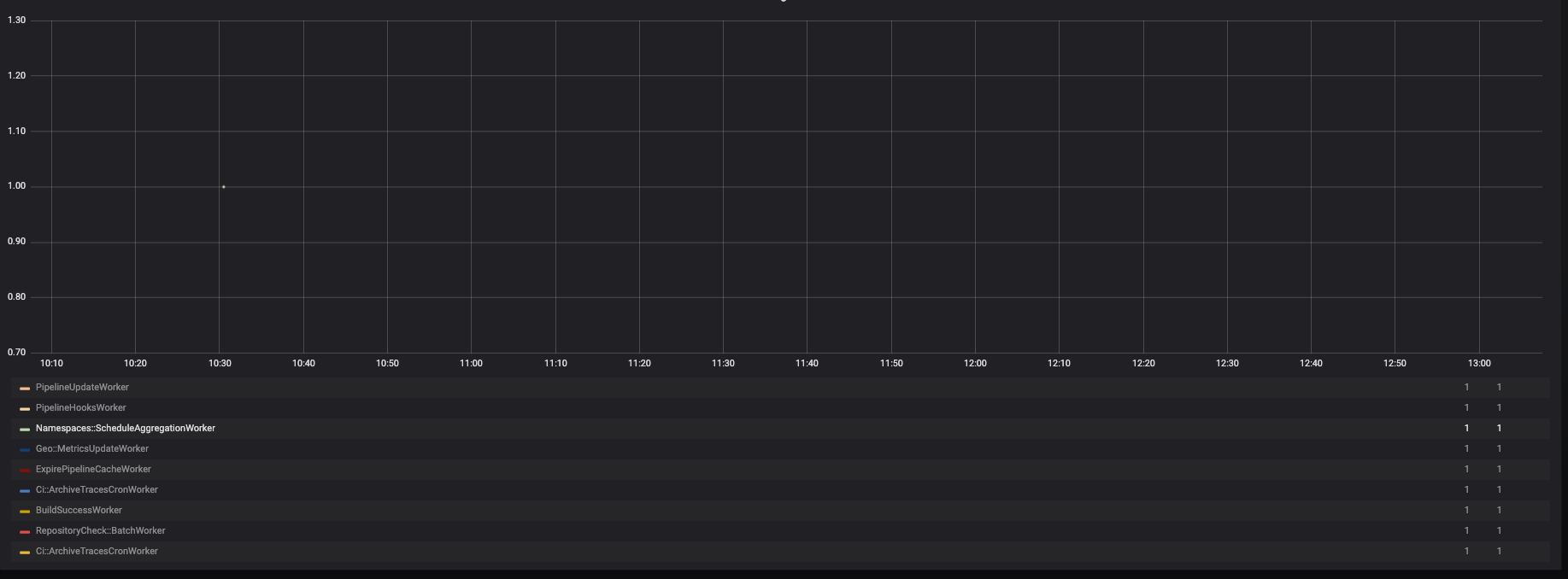
Enabling root namespaces on GitLab.com
Our results were different on GitLab.com. We first enabled it for the gitlab-org group and we quickly started to observe more traffic:
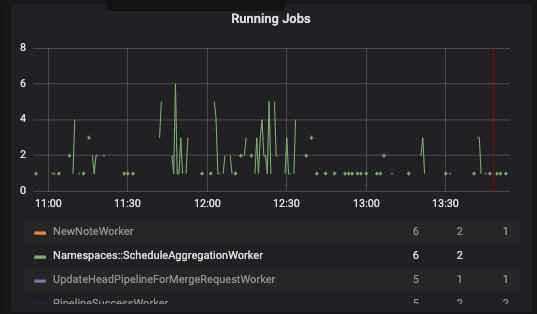
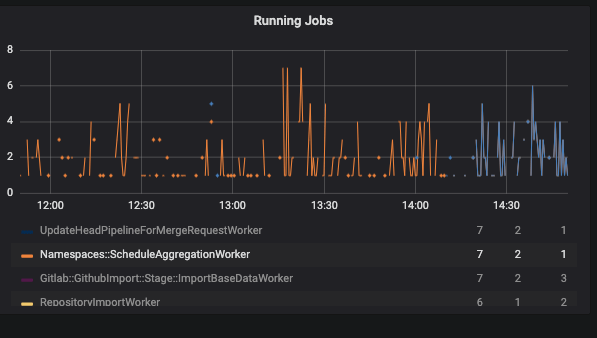
Once we enabled the feature flag globally, the rate of running jobs increased considerably:


Root namespaces on GitLab.com today
We currently have nearly 400 000 statistics stored for root namespaces on GitLab.com, which are updated at a high pace.
Being able to efficiently fetch those statistics allows one to easily track the top biggest repositories and/or namespaces on an instance
and to start paving the way to enforce storage limits for groups on GitLab.com.
Learn more about this use case by reading:
- The original issue
- Merge Request with the implementation
- Details of the performance measured against staging and production (GitLab.com)
Cover photo by Bill Oxford on Unsplash.


