
We recently wrote about how our Security Automation team designed, tested and deployed a new anti-spam engine called Spamcheck. In this blog, we’d like to offer a deeper dive into our toolstack, the contributing factors surrounding some of those technical choices, and a look at the stack’s performance, including some lessons learned so far.
Building with flexibility and growth in mind
As mentioned in our previous blog on Spamcheck, we conceived and built the service to rely on Golang and gRPC from the beginning, and made this choice for 3 main reasons:
- Golang is one of the main languages (along with Ruby) that GitLab currently uses for its systems and services. We suspected from early interest and success that we’d need to eventually ship Spamcheck with Omnibus, so we needed to ensure minimal friction in build processes and shipment. Aligning Spamcheck’s stack with current GitLab engineering policies guaranteed we’d be flexible and efficient. Readers might wonder why Python wasn’t the foundation of such a data-driven, ML-powered service, despite Python being a requirement for GitLab since 11.10. While this is true, Python has only just recently been given serious consideration and attention at GitLab and our design, adaptation, integration and implementation work on Spamcheck has been ongoing for almost a year.
- Golang is high-performing, statically-linked and produces modestly-sized binaries most of the time. Other languages would have forced us to ship complex, voluminous environments; whereas, Golang allowed us to generate and ship small builds and images. Furthermore, we expected to expand analyses from GitLab issues to other user-generated artifacts, such as snippets and issue comments, so we’d need to be able to eventually process an even higher volume of requests efficiently.
- Finally, and as with any such service, we needed an invocation architecture, flexible and backwards-compatible API definitions, and out-of-the-box efficient serialization. What started as a proof-of-concept was starting to look more like a fundamental GitLab component, long-term. Thus, we decided to rely on gRPC, and Gitaly and Workhorse set successful precedents to follow. It was important to ensure the communication protocol between GitLab and Spamcheck would not become a bottleneck; leaving future growth and flexibility unhindered.
Selecting infrastructure components for stability and scalability
As a small, largely self-sufficient, cross-disciplinary development team without dedicated SREs, our Security Automation team decided on Google Kubernetes Engine (GKE) and Knative as our generic platform on which to develop, run, monitor and scale our workloads. This combination gave us the stability and scalability to provide a service that would eventually be integrated with GitLab.com. Today, we’re happy to share that Spamcheck has been successfully operating productively on all GitLab-related public projects on GitLab.com, the hardest hit by abuse, for about a month. We're targetting inclusion of Spamcheck in the 14.6 release for our GitLab self-managed customers.
At this point, however, it’s important to mention that the choices of Golang, gRPC, Kubernetes or Knative weren't decisions made lightly; here be dragons. A key consideration here was ensuring all team members involved were well-versed in the stack-components and aware of the custom deployment artifacts, the equivalent workflows for normal procedures such as debugging and more; as well as the rationale behind those workflows. If you choose to follow shiny objects, make sure to do so for the right reasons and be sure to full-heartedly commit to thoughtful, well-reasoned usage.
Removing complexity; adding accuracy and stability
Given the above, it’s worth asking how we removed much of this complexity from the team's day-to-day operations, so as not to interfere with productivity and the project's progress. For that, as is to be expected, we use GitLab CI/CD. We use GitLab pipelines for building, storing, tracking and deploying the Docker images that make up the Spamcheck service. GitLab’s Kubernetes integration and CI pipeline features make production deployments of our service a one-click operation for members of the Security Automation team. This integration removes much of the complexity associated with properly building ProtoBuf definitions as required by gRPC-enabled services, including gathering and shipping dependencies, etc. Being in control of the deployment allows us to iterate quickly. This came in handy during the early stages of the rollout when gathering metrics about Spamcheck’s operation under real-world conditions efficiently, then iterating on the codebase and redeploying quickly was crucial.
As Spamcheck is called during the creation and update of public GitLab issues, low latency, stability and high accuracy are critical. To ensure these constraints are fulfilled, our team employs a range of GCP Cloud Monitoring services, including logs-based metrics, custom metrics, uptime checks and alerting policies. All of these and the GKE setup are automated via Terraform wherever possible, following our own “Infrastructure as Code'' strategy.
Early wins and metric-driven iteration
At GitLab, measurement is more than a buzzword, it’s part of our “writing down promises” culture and measuring our creations in order to define precise destinations and reorient whenever needed.
Therefore, early on Spamcheck’s journey we set our sights on:
- Surpassing Akismet’s precision and recall
- Reducing the number of successfully submitted Spam issues our Trust and Safety team was dealing with on a day to day basis
Now that we've been operating Spamcheck on all GitLab-related public projects on GitLab.com for the last month, our metrics show that we've surpassed Akismet’s false negative and false positive rates by ~300% and ~30% respectively. This means we've considerably reduced the amount of spam-related issues that reach our Trust and Safety team. In case you were expecting a detail-sparse, but nonetheless production-near sneak peek, into our good-looking dashboards for inspiration or just out of curiosity, here’s an impression from this past week from Spamcheck’s accuracy tracking dashboard:
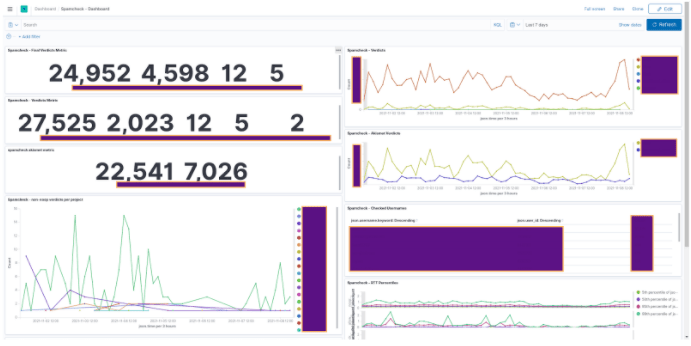 Spamcheck’s accuracy tracking dashboard.
Spamcheck’s accuracy tracking dashboard.
Connecting Spamcheck to existing tooling
The Spamcheck service integrates with Inspector, our in-house machine learning model built by our Trust and Safety team to detect spam on GitLab issues and other user artifacts. While being analyzed, each issue request is sent to Inspector which provides a spam or ham prediction based on the issue’s content. Inspector is written in Python and utilizes a few libraries, mainly Tensor-Flow and scikit-learn, which are open source and highly regarded by the machine learning community.
Additionally, use cases arose relatively early in Spamcheck’s development which led us to integrate GitLab’s main logging, monitoring, metrics and tracing infrastructure. Luckily, by leveraging LabKit, a minimalist library that implements these features for Golang and Ruby services at GitLab, we’re able to easily ship metrics and logs via Prometheus, Jaeger, LogStash and logrus to monitor, and when needed, we can troubleshoot our application in production.
Using these tools, services and strategies, we’re constantly monitoring Spamcheck’s performance, accuracy, and its impact on GitLab.com. We’re using our findings to continually improve our users’ experiences with our site.
Improvement and iteration
Operating Spamcheck successfully wouldn’t have been possible if we hadn’t committed to improving the product itself, via numerous public, and many more private issues that were opened as a result of our lessons learned by developing and operating Spamcheck.
For example, we evaluated possible improvements to BLOCK case handling in spam verdicts, stopped overriding Spamcheck verdicts !=ALLOW and now refuse to allow rescuing via reCAPTCHA and also extended blocking functionality to allow for shadow-banning.
Looking forward, we’ve started defining a better model development lifecycle, and integrating Inspector into Spamcheck to make it easier to deploy our service on self-managed instances. We’ve also started looking at potential retraining cadences and the versioning and testing of models to ensure that at any time our production system is using an optimally-trained model. We’re also looking to diversify our detection in other areas of GitLab where spam is encountered, including, for example, snippet spam using machine learning.
Cover image by Vincent Toesca on Unsplash


