
Users get the most from Gitaly, the service responsible for the storage and maintenance of all Git repositories in GitLab, when traffic hitting it is efficiently handled. Therefore, we must ensure our Git repositories remain in a well-optimized state. When it comes to Git monorepositories, this maintenance can be a complex task that can cause a lot of overhead by itself because repository housekeeping becomes more expensive the larger the repositories get. This blog post explains in depth what we have done over the past few GitLab releases to rework our approach to repository housekeeping for better scaling and to maintain an optimized state to deliver the best peformance for our users.
The challenge with Git monorepository maintenance
To ensure that Git repositories remain performant, Git regularly runs a set of
maintenance tasks. On the client side, this usually happens by automatically
running git-gc(1) periodically, which:
- Compresses revisions into a
packed-refsfile. - Compresses objects into
packfiles. - Prunes objects that aren't reachable by any of the revisions and that have not been used for a while.
- Generates and updates data structures like
commit-graphsthat help to speed up queries against the Git repository.
Git periodically runs git gc --auto automatically in the background, which
analyzes your repository and only performs maintenance tasks if required.
At GitLab, we can't use this infrastructure because it does not give us enough control over which maintenance tasks are executed at what point in time. Furthermore, it does not give us full control over exactly which data structures we opt in to. Instead, we have implemented our own maintenance strategies that are specific to how GitLab works and catered to our specific needs. Unfortunately, the way GitLab implemented repository maintenance has been limiting us for quite a while by now.
- It is unsuitable for large monorepositories.
- It does not give us the ability to easily iterate on the employed maintenance strategy.
This post explains our previous maintenance strategy and its problems as well as how we revamped the architecture to allow us to iterate faster and more efficiently maintain repositories.
Our previous repository maintenance strategy
In the early days of GitLab, most of the application ran on a single server. On this single server, GitLab directly accessed Git repositories. For various reasons, this architecture limited us, so we created the standalone Gitaly server that provides a gRPC API to access Git repositories.
To migrate to exclusively accessing Git repository data using Gitaly we:
- Migrated all the logic that was previously contained in the Rails application to Gitaly.
- Created Gitaly RPCs and updated Rails to not execute the logic directly, but instead invoke the newly-implemented RPC.
While this was the easiest way to tackle the huge task back then, the end result was that there were still quite a few areas in the Rails codebase that relied on knowing how the Git repositories were stored on disk.
One such area was repository maintenance. In an ideal world, the Rails server would not need to know about the on-disk state of a Git repository. Instead, the Rails server would only care about the data it wants to get out of the repository or commit to it. Because of the Gitaly migration path we took, the Rails application was still responsible for executing fine-grained repository maintenance by calling certain RPCs:
Cleanupto delete stale, temporary files that have accumulatedRepackIncrementalandRepackFullto either pack all loose objects into a new packfile or alternatively to repack all packfiles into a single onePackRefsto compress all references into a singlepacked-refsfileWriteCommitGraphto update the commit-graphGarbageCollectto perform various different tasks
These low-level details of repository maintenance were being managed by the client. But because clients didn't have any information on the on-disk state of the repository, they could not even determine which of these maintenance tasks had to be executed in the first place. Instead, we had a very simple heuristic: Every few pushes, we ran one of the above RPCs to perform one of the maintenance tasks. While this heuristic worked, it wasn't great for the following reasons:
- Repositories can be modified without using pushes at all. So if users only use the Web IDE to commit to repositories, they may not get repacked at all.
- Because repository maintenance is controlled by the client, Gitaly can't assume a specific repository state.
- The threshold for executing housekeeping tasks is set globally across all projects rather than on a per-project basis. Consequently, no matter whether you have a tiny repository or a huge monorepository, we would use the same intervals for executing maintenance tasks. As you may imagine though, doing a full repack of a Git repository that is only a few dozen megabytes in size is a few orders of magnitudes faster than repacking a monorepository that is multiple gigabytes in size.
- Specific types of Git repositories hosted by Gitaly need special care and we required Gitaly clients to know about these.
- Repository maintenance was inefficient overall. Clients do not know about the on-disk state of repositories. Consequently, they had no choice except to repeatedly ask Gitaly to optimize specific data structures without knowing whether this was required in the first place.
Heuristical maintenance strategy
It was clear that we needed to change the strategy we used for repository maintenance. Most importantly, we wanted to:
- Make Gitaly the single source of truth for how we maintain repositories. Clients should not need to worry about low-level specifics, and Gitaly should be able to easily iterate on the strategy.
- Make the default maintenance strategy work for repositories of all sizes.
- Make the maintenance strategy work for repositories of all types. A client should not need to worry about which maintenance tasks must be executed for what repository type.
- Avoid optimizing data structures that already are in an optimal state.
- Improve visibility into the optimizations we perform.
As mentioned in the introduction, Git periodically runs git gc --auto. This
command inspects the repository's state and performs optimizations only when it
finds that the repository is in a sufficiently bad state to warrant the cost.
While using this command directly in the context of Gitaly does not give us
enough flexibility, it did serve as the inspiration for our new architecture.
Instead of providing fine-grained RPCs to maintain various parts of a Git
repository, we now only provide a single RPC OptimizeRepository that works as
a black-box to the caller. This RPC call:
- Cleans up stale data in the repository if there is any.
- Analyzes the on-disk state of the repository.
- Depending on this on-disk state, performs only these maintenance tasks that are deemed to be necessary.
Because we can analyze and use the on-disk state of the repository, we can be far more intelligent about repository maintenance compared to the previous strategy where we optimized some bits of the repository every few pushes.
Packing objects
In the old-style repository maintenance, the client would call either
RepackIncremental or RepackFull. This would either: Pack all loose objects into a new packfile or repack all objects into a single packfile.
By default, we would perform a full repack every five repacks. While this may be a good default for small repositories, it gets prohibitively expensive for huge monorepositories where a full repack may easily take several minutes.
The new heuristical maintenance strategy instead scales the allowed number of
packfiles by the total size of all combined packfiles. As a result, the
larger the repository becomes, the less frequently we perform a full repack.
Pruning objects
In the past, clients would periodically call GarbageCollect. In addition to
repacking objects, this RPC would also prune any objects that are unreachable
and that haven't been accessed for a specific grace period.
The new heuristical maintenance strategy scans through all loose objects that
exist in the repository. If the number of loose objects that have a modification
time older than two weeks exceeds a certain threshold, it spawns the
git prune command to prune these objects.
Packing references
In the past, clients would call PackRefs to repack references into the
packed-refs file.
Because the time to compress references scales with the size of the
packed-refs file, the new heuristical maintenance strategy takes into account
both the size of the packed-refs file and the number of loose references that
exist in the repository. If a ratio between these two figures is exceeded, we
compress the loose references.
Auxiliary data structures
There are auxiliary data structures like commit-graphs that are used by Git
to speed up various queries. With the new heuristical maintenance strategy,
Gitaly now automatically updates these as required, either when they are
deemed to be out-of-date, or when they are missing altogether.
Heuristical maintenance strategy rollout
We rolled out this new heuristical maintenance strategy to GitLab.com in March 2022. Initially, we only rolled it out for
gitlab-org/gitlab, which is a
repository where maintenance performed particularly poorly in the past. You can
see the impact of the rollout in the following graph:
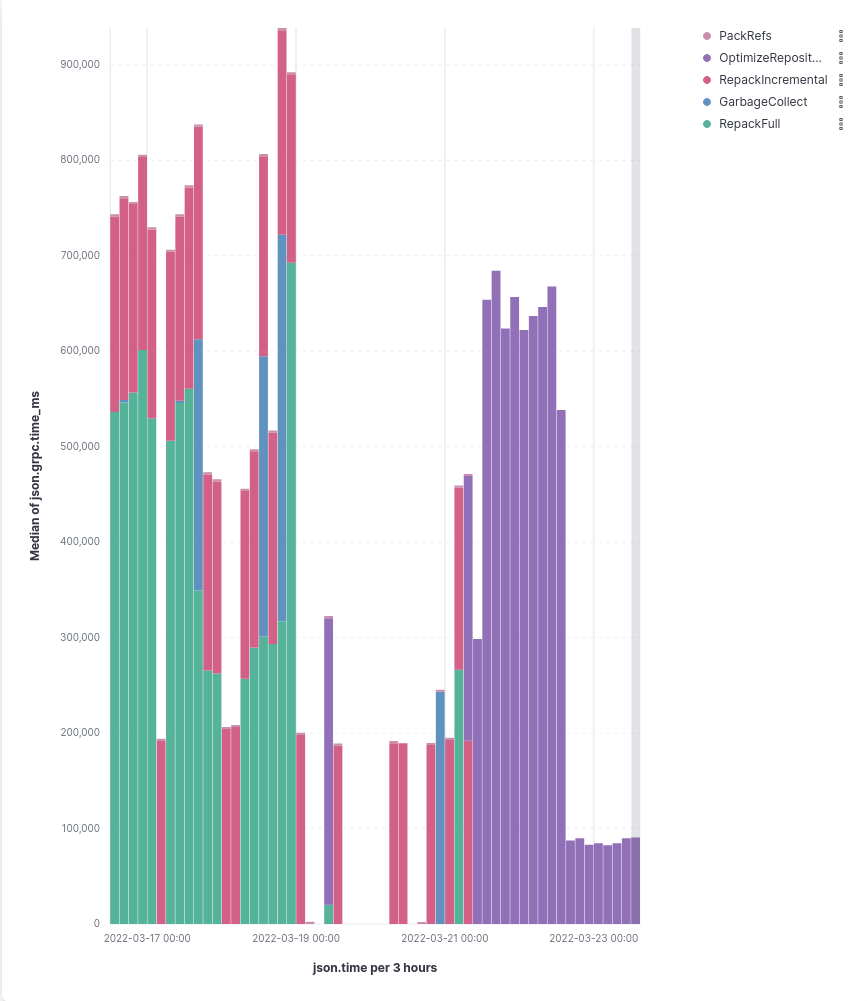
In this graph, you can see that:
-
Until March 19, we used the legacy fine-grained RPC calls. We spent most of the time in
RepackFull, followed byRepackIncrementalandGarbageCollect. -
Because March 19 and 20 occurred on a weekend, nothing much happens with housekeeping.
-
Early on March 21 we switched
gitlab-org/gitlabto use heuristical housekeeping usingOptimizeRepository. Initially, there didn't seem to be much of an improvement. There wasn't much difference in how much time we spent maintaining this repository compared to the past.However, this was caused by an inefficient heuristic. Instead of only pruning objects when there were stale ones, we always pruned objects when we saw that there were too many loose objects.
-
We deployed a fix for this bug on March 22, which led to a significant drop in time spent optimizing this repository compared to before.
This demonstrated two things:
- We're easily able to iterate on the heuristics that we have in Gitaly.
- Using the heuristics saves a lot of compute time as we don't unnecessarily optimize anymore.
We have subsequently rolled this out to all of GitLab.com, starting on March 29, 2022, with similar improvements. With this change, we more than halved the CPU load when performing repository optimizations.
Observability
While it is great that OptimizeRepository has managed to save us a lot of
compute power, one goal was to improve visibility into repository housekeeping.
More specifically, we wanted to:
- Gain visibility on the global level to see what optimizations are performed across all of our repositories.
- Gain visibility on the repository level to know what state a specific repository is in.
In order to improve global visibility, we expose a set of Prometheus metrics that allow us to observe important details about our repository maintenance. The following graphs show the optimizations performed in a 30-minute window of our production systems on GitLab.com.
-
The optimizations, which are being performed in general.

-
The average latency it takes to perform each of these optimizations.

-
What kind of stale data we are cleaning up.

To improve visibility into the state each repository is in we have started to log structured data that includes all the relevant bits. A subset of the information it exposes is:
- The number of loose objects and their sizes.
- The number of
packfilesand their combined size. - The number of loose references.
- The size of the
packed-refsfile. - Information about
commit-graphs, bitmaps and other auxiliary data structures.
This information is also exposed through Prometheus metrics:
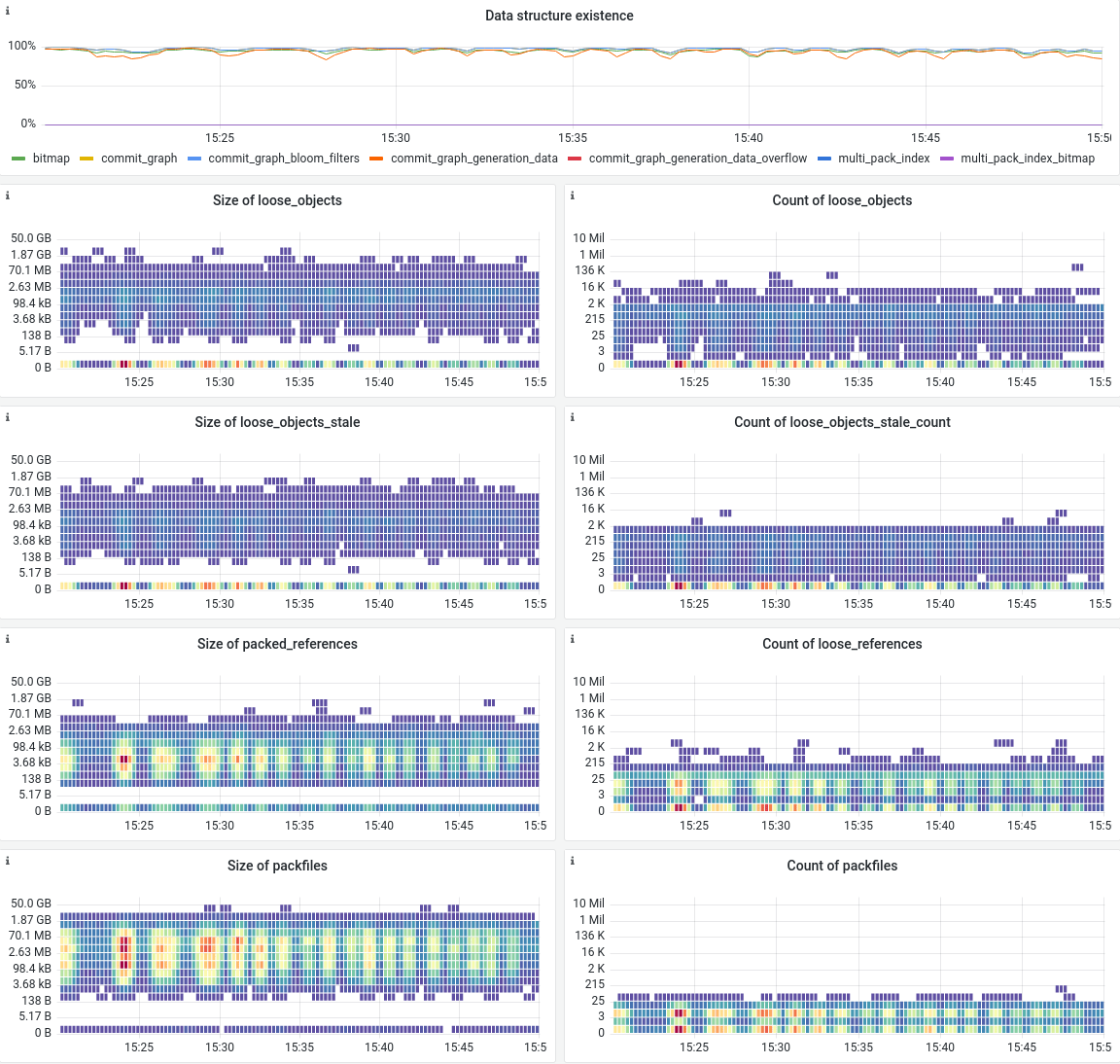
These graphs expose important metrics of the on-disk state of our repositories:
- The top panel shows which data structures exist.
- The heatmaps on the left show how large specific data structures are.
- The heatmaps on the right show how many of these data structures we have.
Combining both the global and per-repository information allows us to easily observe how repository maintenance behaves during normal operations. But more importantly, it gives us meaningful data when rolling out new features that change the way repositories are maintained.
Manually enabling heuristical housekeeping
While the heuristical housekeeping is enabled by default starting with GitLab
15.9, it has already been introduced with GitLab 14.10. If you want to use the
new housekeeping strategy before upgrading to 15.9, you can opt in by
setting the optimized_housekeeping feature flag.
You can do so via the gitlab-rails console:
Feature.enable(:optimized_housekeeping)
Future improvements
While the new heuristical optimization strategy has been successfully battle-tested for a while now for GitLab.com, at the time of writing this blog post, it still wasn't enabled by default for self-deployed installations. This has finally changed with GitLab 15.8, where we have default-enabled the new heuristical maintenance strategy.
We are not done yet, though. Now that Gitaly is the only source of truth for how repositories are optimized, we are tracking improvements to our maintenance strategy in epic 7443:
- Multi-pack indices and geometric repacking will help us to further reduce the time spent repacking objects.
- Cruft packs will help us to further reduce the time spent pruning objects and reduce the overall size of unreachable objects.
- Gitaly will automatically run housekeeping tasks when receiving mutating RPC
calls so that clients don't have to call
OptimizeRepositoryat all anymore.
So stay tuned!


