
Being part of the GitLab collective is an opportunity to learn first hand about the challenges the community using the DevOps Platform is facing. As a Collective Member logging between 2-3 times a week in StackOverflow reading the questions and discussion posted about GitLab and manually sorting them by 'Recent Activity', 'Trending' and using Dates, I asked myself: how can we leverage this wealth of data and discover feedback, while finding the most frequent topics where the community has questions?
This would be an opportunity to get a quick overview of topics where the community regularly needs help; this would also make it easier for us to create relevant content for them. Manually sorting and extracting the text of each question wouldn’t be sustainable, so creating an automated way would be the most efficient way to proceed.
Experimenting with data-oriented content creation
Finding out what the community is working on, and what they need help with while using GitLab, can help us to create better educational content that could expand their understanding of GitLab. To achieve this goal, the solution I created after a few iterations is depicted below:
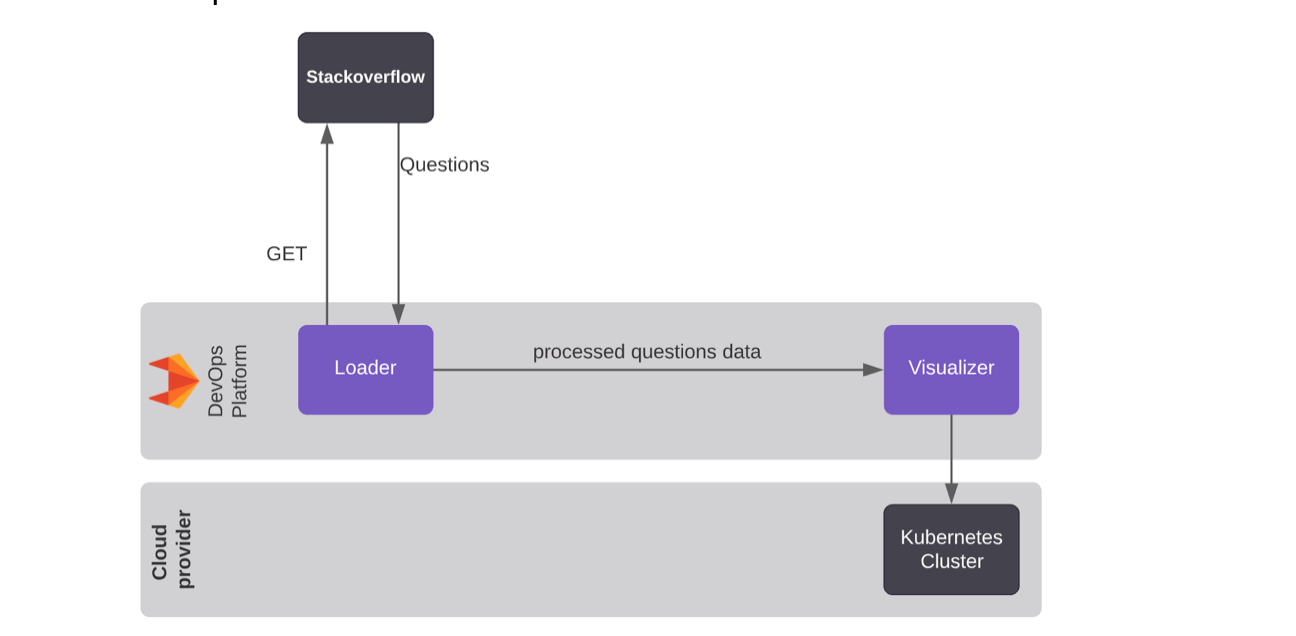
Where the Bill Of Materials consists mainly of:
- GitLab DevOps Platform
- Stackoverflow API
- Kubernetes Cluster
- Open Source Python libraries:
- scikit-learn (TF-IDF)
- Streamlit (front-end)
- Spacy
I leveraged the GitLab DevOps Platform to organize the projects using groups:
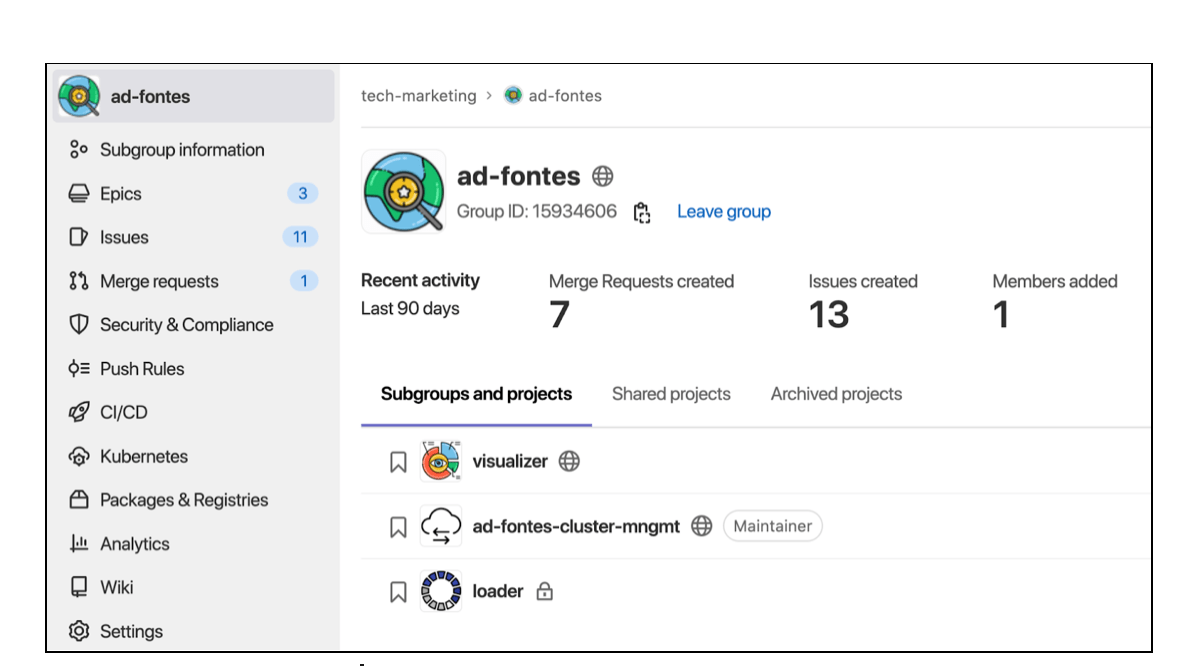
The Loader project pulls questions about GitLab from the StackOverflow API, pre-processes the text and makes it usable for a second project: a Visualizer to create customized dashboards.
The automated process executed using the DevOps Platform is outlined below:
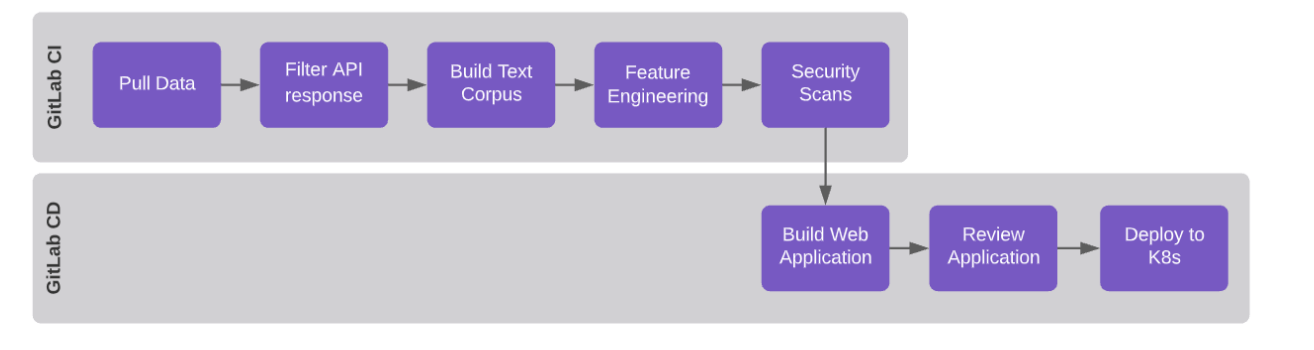
- Pull data from StackOverflow API
- Preprocess the response extracting relevant fields from returned JSON
- Build a corpus and calculate TF-IDF
- Scan for security vulnerabilities
- Review Application and display its resulting dashboards using Streamlit
- Deploy the built application to a Kubernetes cluster
Loader and Visualizer projects have their own codebase and pipelines, which is helpful if different teams need to work separately on them. However, one project can require the other, which raises the need for cross-project automation.

This scenario means a multi-project pipeline is useful to automate the whole process. The multi-project pipeline enables use cases such as:
- As an NLP Developer I want to work on the NLP Pipeline in the Loader Project and automatically trigger the creation of a new visualization
- As a Streamlit Developer I want to work independently in the buttons and data visualization without touching any NLP Pipeline backend
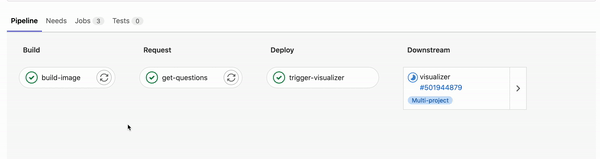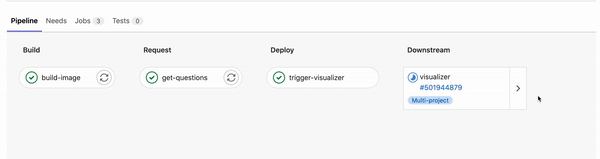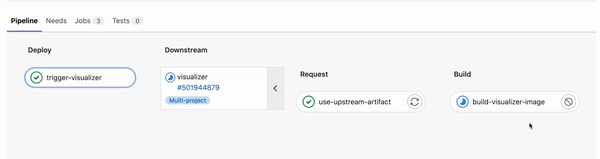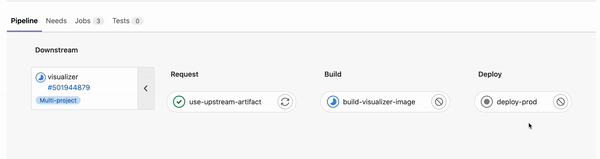
The outlined process above is automatically run defining the steps in a multi-project pipeline sharing artifact:
Finding the most frequently occurring words
The Feature Engineering step will help me to analyze the text in the whole dataset of GitLab questions. Using a simple yet powerful technique – TF-IDF – we aim to find the most relevant terms utilized by the community. By using this technique in the pipeline execution, I represent words in numerical values and later rank them in order of importance. This approach serves as a baseline for further improvements. More detail about this algorithm can be found here.
Did we achieve any success?
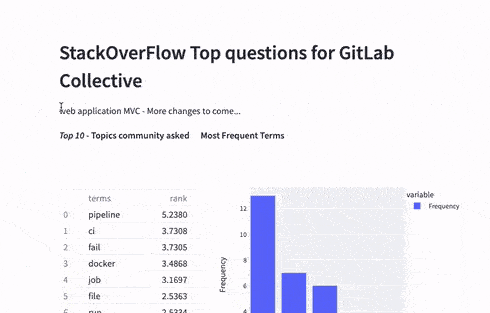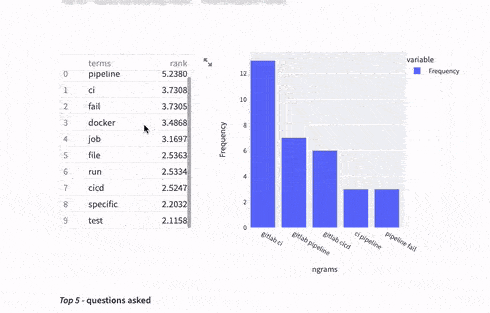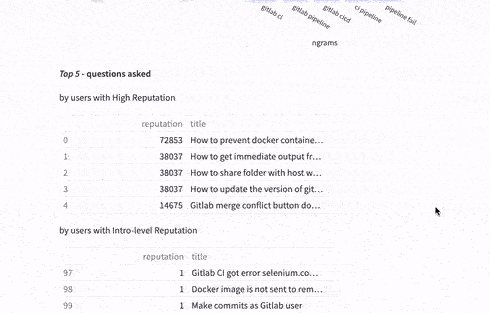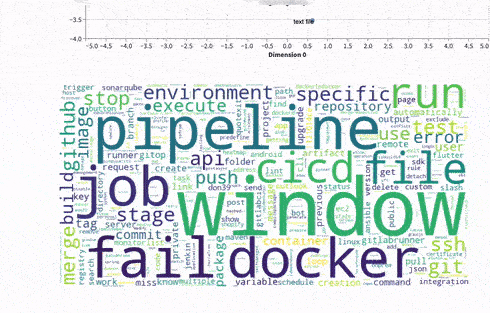
One run of the multi-pipeline in our solution results in dashboards such as this one:
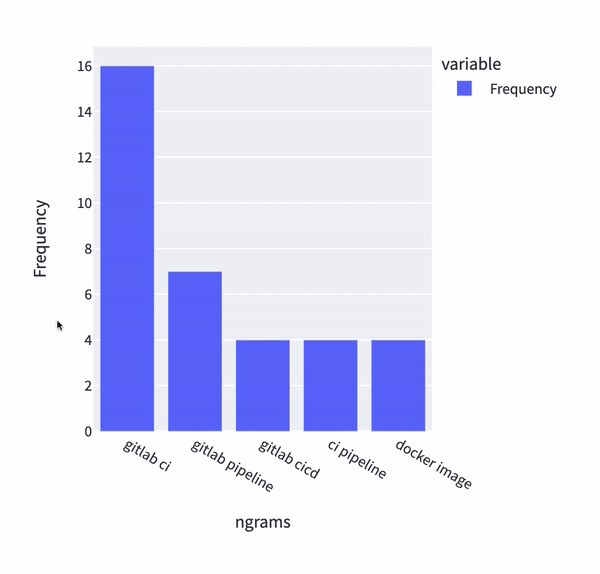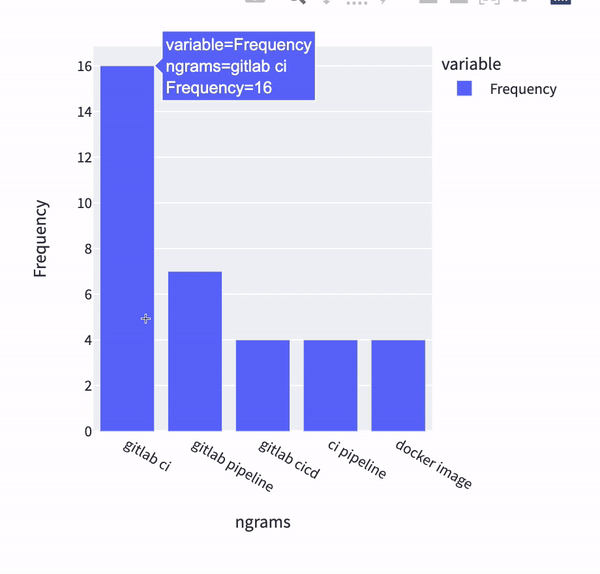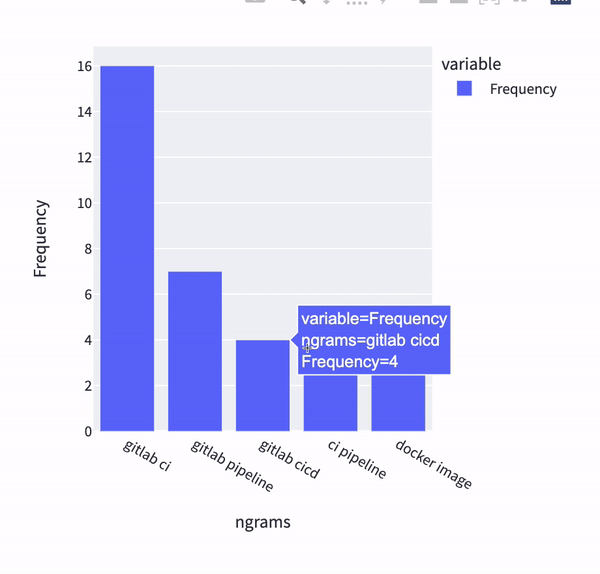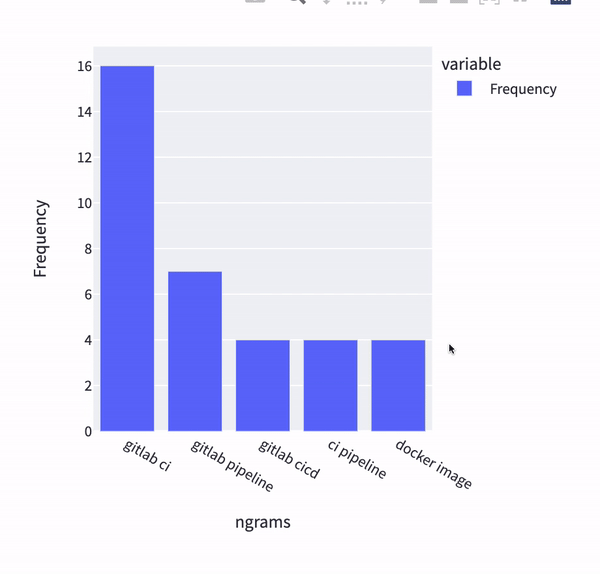
As an end-user of these dashboards I can immediately conclude that the main source of questions are around GitLab CI, pipelines and usage of Docker images. Not bad for a first run! Having the data processed enables us to ask more questions and use data to answer it, such as, what are the questions from the highest StackOverflow reputation users ?

Could these questions be inspiration for tutorials for the most advanced users, or the implementation of a new feature?
Because everyone can contribute, let's take a look at the users who just started gaining their StackOverflow reputation:

The question about access and reading/writing permissions in Portuguese is interesting. It makes me wonder about content localization and GitLab meetups in Portuguese-speaking countries. Not surprisingly, there were also questions about GitLab CI too as the text processing and ranking found most relevant in the corpus.
Did we achieve any success? Yes, using a baseline technique such as TF-IDF sped up by DevOps practices allowed us to find out relevant terms and help us to understand where the majority of the community needs help in their DevOps journey. I have automated many steps that will allow me to focus on data exploration and possible implementation of more complex NLP Techniques rather than infrastructure allocation or manual input of commands and tests.
As a Technical Marketing Manager, I want to create content that is relevant to enable or inspire the community to succeed.
A personal take away: Educating about the latest GitLab DevOps platform capabilities and the problems they solve is important and so is keeping an eye on the content that might not be related to a new feature but is needed right now.
Are we done? No, quoting Da Vinci's altered quote about Art but with software: "Software is never finished, only abandoned."
There is room for improvement and adding capabilities to this project. We continue iterating, listening to the community, and we encourage you to clone these projects, try it yourself, and adjust it with the topics that make sense to you. Create a merge request to improve the codebase and suggest new dashboards ideas!
Explore the group of projects and take a look at the dashboard.


