
On the data team at GitLab, we are grateful to be empowered with best in-class tools that enable us to produce high-quality work. At the 2018 DataEngConf (now Data Council), GitLab data engineer Thomas La Piana spoke about how a team of three was supporting the data needs of a billion-dollar company. As he explains in this talk, we focus a lot on processes and workflows.
Where are the existing gaps?
Today, the data team has grown from three to seven: three engineers and four analysts. Since we've more than doubled in the last six months, we've had to take a step back and revisit our processes.
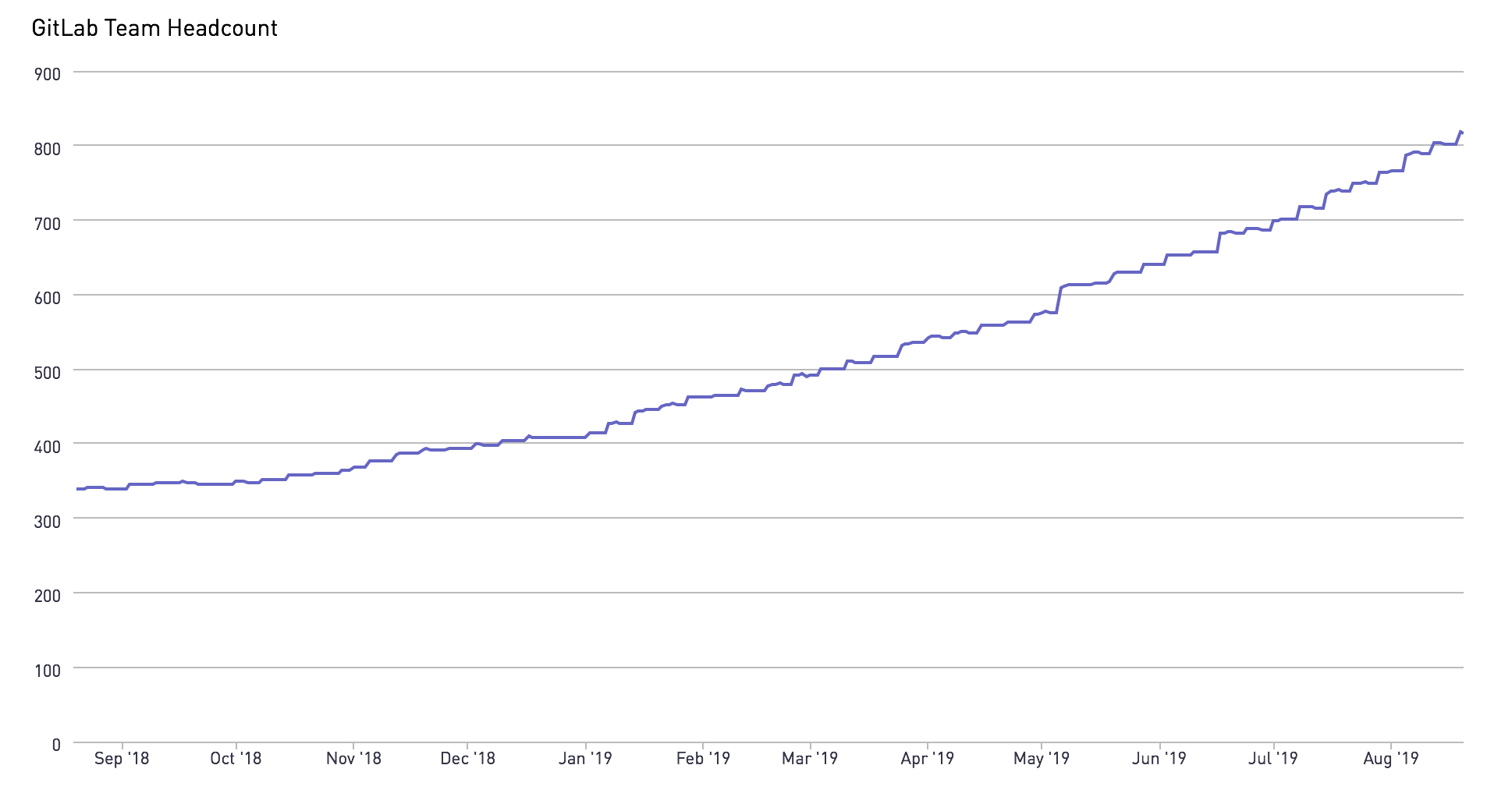 The GitLab team has grown significantly in the past few months.
The GitLab team has grown significantly in the past few months.
GitLab is growing fast
Despite the significant jump in the data team's headcount, our growth has not matched the exponential growth of the team supporting GitLab. As GitLab grows, more folks aim to include more data in their decision-making process. This means we're iterating quickly, collecting feedback, and constantly improving on the quality of the analyses we are producing for our business stakeholders. The demand for more data means there is a lot more to accomplish – making now an opportune time to review our processes and improve the data team's impact across GitLab.
For example, a data team member pointed out that refinement isn't a part of our milestone planning process. No wonder our backlog wasn't moving anywhere! We identified the root of the problem by asking our team, "What is the problem we're trying to solve?" and then laid out a plan to address it.
Onboarding can be hard
We've made some great data analyst hires recently! We don't require our new team members to be familiar with our existing data stack (Stitch/Singer - Snowflake - dbt - Periscope), but we do require them to have technical skills that match their role. This usually includes Git, SQL, and Python (Pandas) at the bare minimum, though we welcome R (tidyverse) as well. While onboarding at any company can be difficult, it's especially challenging in an all-remote organization such as GitLab.
In addition to introducing candidates to our specific technologies, part of the data analyst onboarding includes a unit on resource consumption. We spend time introducing the concepts of databases and warehouses in Snowflake, because storage and compute being separate are often novel ideas to folks joining GitLab from an on-premise data organization. In some cases, we are teaching our new hires a new way to think about the data-related problems they're solving, and introducing different resources to remedy these problems.
With great power comes great responsibility
We consume more resources as the data team headcount grows. I think about this like folks using water in a household. If everyone is on vacation, the water bill will be low, but if all the cousins come visit for a week, the bill will be high. Similarly to why we encourage a big group of visiting relatives to take shorter showers to conserve water, on the data team we work to steward resources effectively. This means we must identify wasted resources to recapture them. It's important that our operating expenses not balloon with headcount.
Are you protected against a leak?
As a homeowner, I can share a myriad of appliance-gone-wrong stories, but one tops them all: the time there was a leak in our front yard that we only discovered because of a $1,000 water bill. Often, homeowners can only measure water usage when the bill arrives, when it's always too late to fix it.
Lucky for our team and yours, Snowflake is much more generous than my water company. We can monitor our costs as it accrues. After having this process in place for a bit now, we'd encourage you to implement it in your stack.
Monitor your Snowflake spend with dbt and Periscope
We're excited to make our Snowflake spend dbt package widely available for use. Doing this is in line with our belief in the value of open source analytics.
To get started, you'll need to grant access to the snowflake database to your dbt-specific role with:
GRANT IMPORTED PRIVILEGES ON DATABASE snowflake TO ROLE <role>;
Then you'll need to update the packages.yml file in your dbt project to include the following:
packages:
- git: https://gitlab.com/gitlab-data/snowflake_spend.git
revision: v1.0.0
Today, you can only install the package directly from Git.
Since it doesn't depend on any other packages, you don't have to worry about version management, so this should not cause any problems.
You can run dbt deps to ensure the package is installed correctly.
You will need a csv called snowflake_contract_rates.csv which has two columns: effective date and rate. The effective date is the day the new contracted rate started and it should be in YYYY-MM-DD format. The rate is the per credit price for the given time period. You can see how the data team configures their csv file. You will need to run dbt seed for the csv to be loaded as a table and for the model to run succesfully.
Finally, you will need to update your dbt_project.yml file to enable this package with the following block.
models:
snowflake_spend:
enabled: true
You can see how the data team has configured the package in our dbt_project.yml file.
Running dbt compile will not only test that you've configured all of this correctly, but also will compile the files in the analysis directory. These are the queries that we use to underlie the exact Periscope dashboard that we have automatically posted in Slack every day.
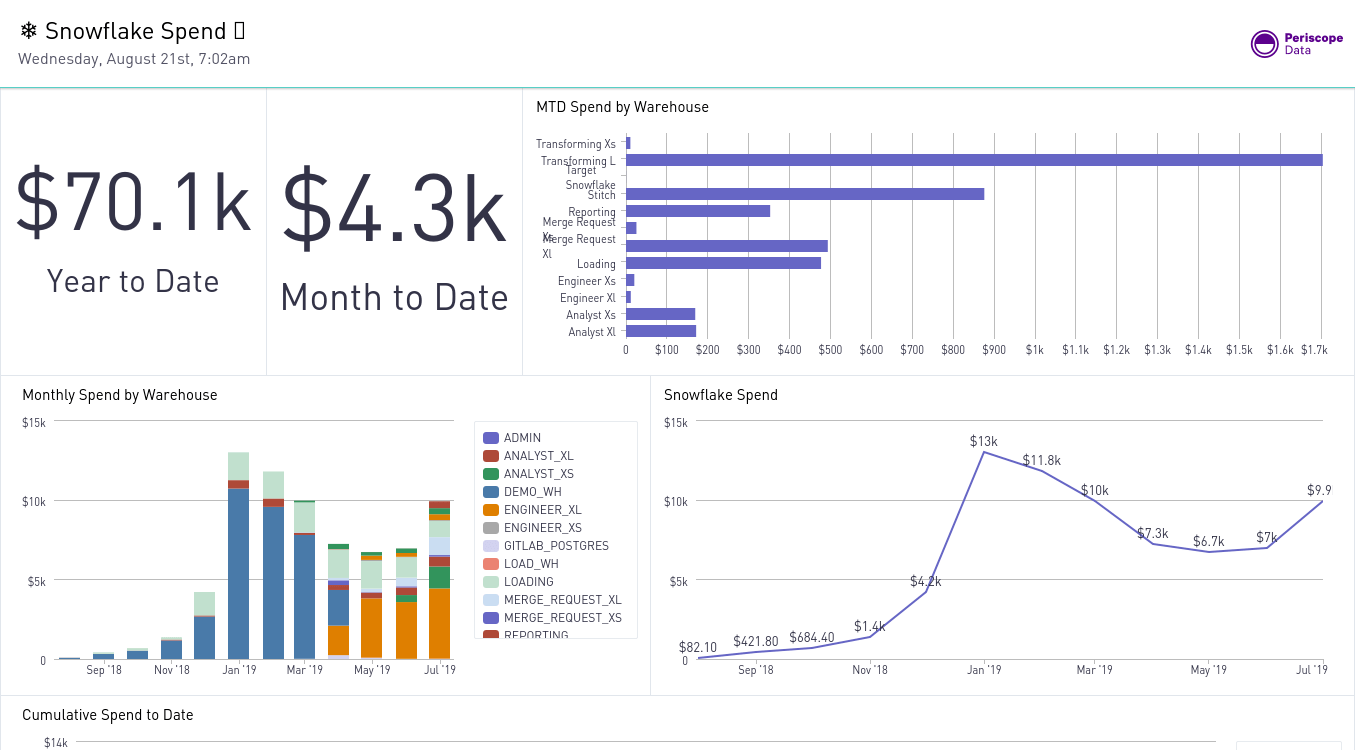
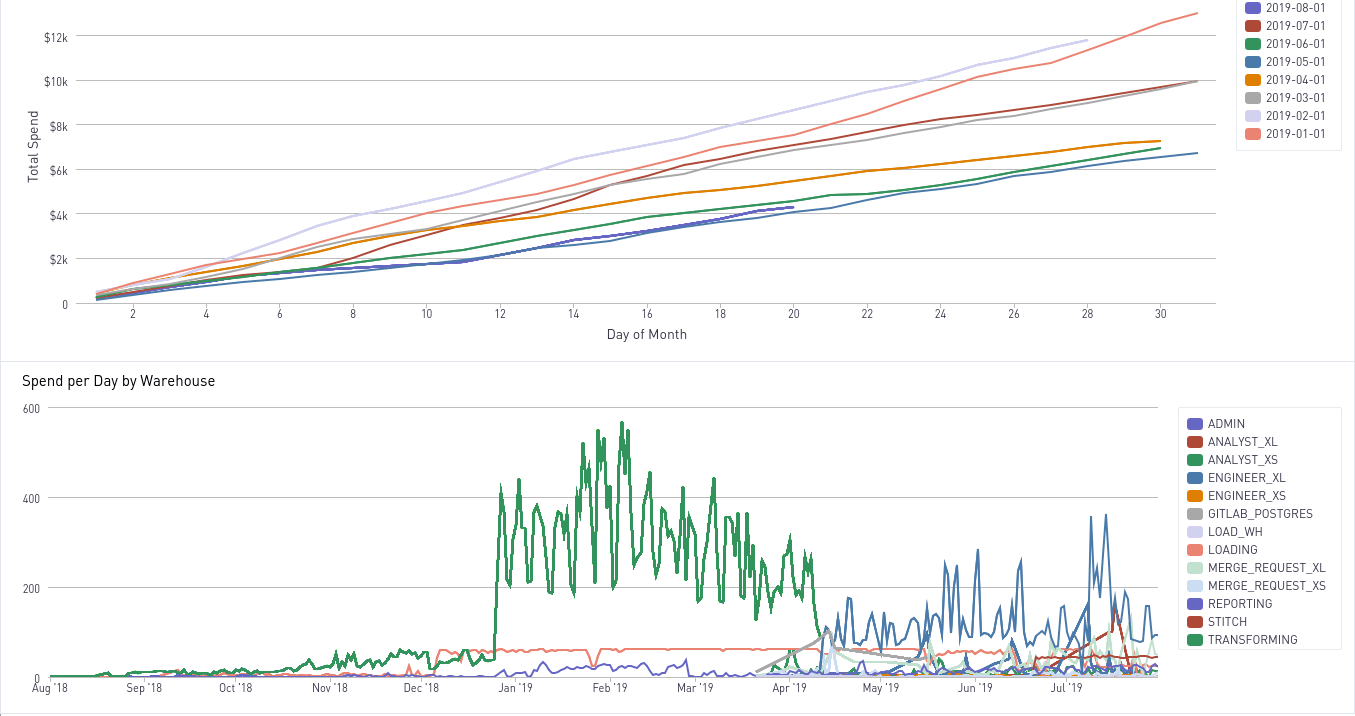
Once you've set up this dashboard, you can configure it to auto-refresh daily.
Then use Slack's /remind app.periscopedata.com/dashboardurl to have it regularly publish in the channel of your choice.
You can see how our resource management initiatives have been effective. We hope you'll find monitoring a key step to helping manage your own Snowflake spend.
Have any thoughts, questions, or suggestions? Create an issue.
Photo by Taylor Vick on Unsplash


