
Many companies stitch together multiple tools to handle alerts and incidents, which can be time-consuming and frustrating. Why should teams have to use so many tools for what is, essentially, a single workflow?
We hear you, and we think we’ve come up with some great new features to help alleviate this problem.
At GitLab, the Monitor team has been busily working behind the scenes to improve our offerings for Alerts and Incident Management.
What’s changed?
You can now send alerts from your monitoring tools straight to GitLab, where they will be displayed for you and your team to review. If an alert is serious enough, you can escalate that alert to an incident, a newly defined type of issue crafted specifically for this purpose. Once the incident is created, you can push the fixes immediately: all within a single tool.
We’re incredibly proud of what we’re creating but, how did we get here? How did we take what was a blank space and turn it into something that people could use? Dare I say, might even want to use?
The short answer: by working through GitLab’s Product Development Flow, by leaning on our value of iteration, and collaborating closely with the people who use GitLab every day.
Validating the problem
The first thing we needed to do was to ensure we understood what people were struggling with, in their current workflow, with their current tools. We call this Problem Validation, and it means asking the following question before getting started with any work: Do we clearly understand the problem(s) end-users have?
As part of the problem validation process, we reached out to Developers, SREs, and DevOps engineers. We wanted to better understand what tools they were using, what their current workflows were, and if there were any gaps in their workflows that we could fill within GitLab.
Through our research, we discovered something that was both a serious pain point and an opportunity for us at GitLab. Unsurprisingly, it turns out that many Developers are currently stitching together a multitude of tools for monitoring their applications, for creating and sending alerts, and for investigating and resolving the issues that are reported.
Stitching together all of these tools can work, but it’s messy for teams to manage. The context switching that’s required is difficult, and it means having to keep track of different pieces of information in multiple places. We heard, again and again, how burdensome and fatiguing this can be. What people need, instead, is an intentionally designed workflow for triaging alerts and responding to incidents.
Luckily for us, GitLab already had many pieces of this workflow in place, in that Developers can currently raise issues, create merge requests, and deploy their code within our product. The opportunity, and what we were missing, was a place to review and triage alerts.
If we could introduce a single location where all alerts (from multiple tools) can be received, reviewed, resolved, or escalated into incidents, we could create a seamless incident management workflow within GitLab: from the alert being received to the incident being created, all the way through to the code fix being deployed.
Validating the solution
With the desired workflow pinned down, we started ideating on designs for triaging and managing alerts. After creating some initial concepts, we wanted to validate them to make sure we were actually solving the problems we had identified.
Following our Product Development Flow for solution validation, we wanted to share our designs with the teams we thought would most benefit from using the features we designed.
To enable us to more quickly connect with the people who would be using our features, we decided to create a Special Interest Group (SIG). We went this route because we wanted to work more collaboratively with a well-defined group of people over a period of time. We felt that this could help us to understand their needs better, and it would mean we could check in with them more often, and on a more regular basis.
The SIG is composed of GitLab customers who are involved with responding to alerts and incidents within their organizations. To recruit this group, we sent out a survey to our First Look members. When we had a short list of people who fit our criteria, we scheduled introductory meetings to learn more about them, find out how they worked, and explain a bit more about the SIG. After ensuring they were on board with our experiment, we invited them to join our SIG.
As we generated designs – first for an alert list, then for an alert detail page – we shared these designs with the SIG members during live, individual feedback sessions. During these sessions, we asked them to take a short usability test where we gave them an imagined scenario and asked them to complete a task. We also asked them for their feedback more generally, to understand if what we were proposing would help improve their current workflow.
We met with the SIG monthly over a period of several months. Each time they reviewed our designs, we revised them. The feature set we ultimately arrived at owes a great deal to their feedback and their commitment to improving GitLab as a product.
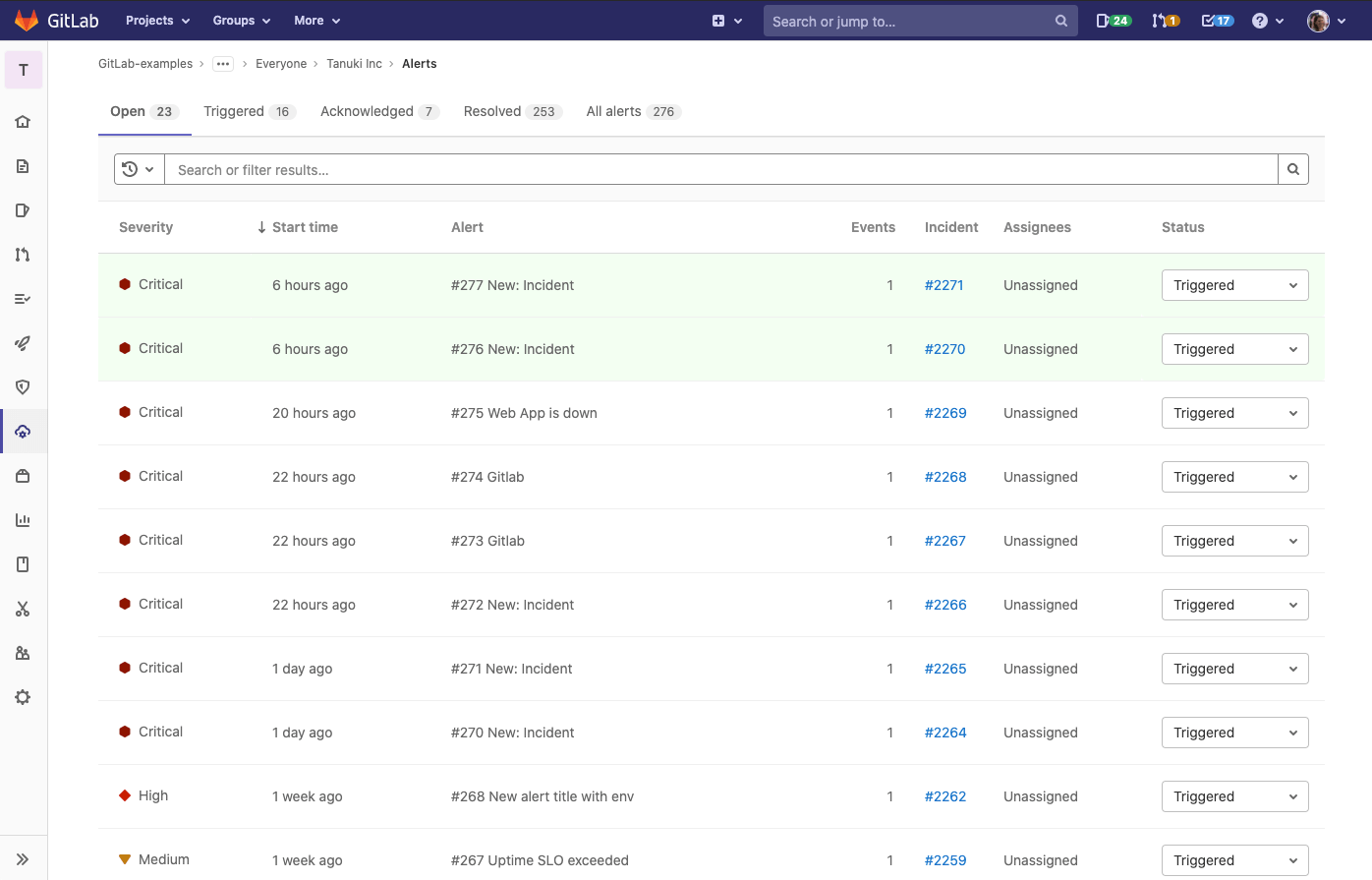
Alert list in GitLab
After validating our proposals with the SIG members we broke our designs down into what we call a Minimal Viable Change (MVC) that, over the course of several months, our engineering team built into GitLab: starting with the alert list, and then adding in the alert detail page. Additional functionality, such as the ability to change the status of an alert from within GitLab, was built on top of those two base elements.
Introducing dedicated incidents
Many alerts that are sent are not necessarily things that teams need to worry about. Maybe they are expected issues, or maybe they aren't things that need to be immediately addressed. But, what happens when an alert is serious enough to require additional investigation? What happens when the alert needs to become an incident?
For the MVC version of alert management, alerts would be received and, if they were serious enough, the alert could be escalated to a GitLab issue.
We used our existing issue framework for incidents because it was an easy way for us to complete the larger workflow. From a GitLab issue, people can create an MR to fix whatever is causing the alert in the first place. Then they can push the code that will publish the fix. So, by using issues, we were able to approximate a full incident management workflow: from alert receipt to live code.
However, in testing the alerting functionality we had built with our SIG, we learned that there were still many gaps in the experience of investigating and resolving incidents that issues couldn’t really help us fix.
For example, within incidents, you likely need quick access to various metrics or runbooks. Maybe you also need an incident timeline. There are hacky ways of making GitLab issues work for these purposes, but we wondered, "Is there a way that we can better surface the information needed for quickly resolving incidents within issues?"
These sorts of discussions ultimately resulted in us introducing dedicated incidents in GitLab. Incidents are a special kind of issue where the content displayed is updated to better fit the needs of people actively involved in investigating and resolving incidents.
In designing incidents, we removed items from our existing issues that were less relevant, replacing them with content that better fits the incident workflow. In both cases, we used feedback from customers to make decisions about what to include – and what to exclude. Our goal was to make sure that only the most relevant information is visible, so that incidents can be resolved as quickly and efficiently as possible.
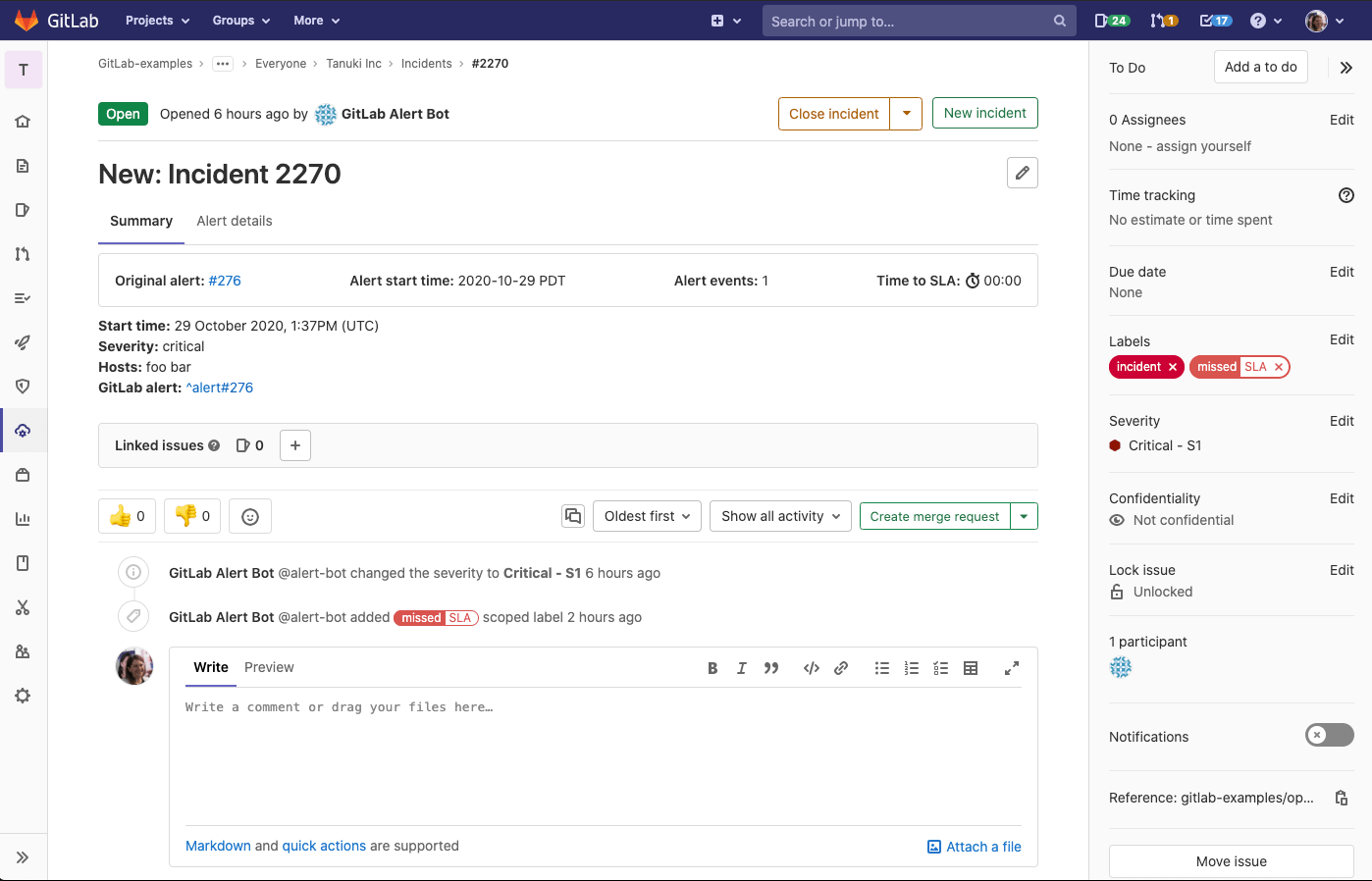
An example dedicated incident in GitLab
Creating a dedicated type of issue for incidents hasn’t been a quick process! By relying on our iteration value, we’ve been slowly transforming the GitLab issue into an incident over the course of many months. Now, incidents are finally taking shape, and we are at the point where people have started using them as part of their workflows. We’ve seen an increase in usage of 4,200%!
This is a huge step for incident management at GitLab, and we’re delighted to see how people will use incidents at their organizations.
Up next: On-call Management
The final piece of incident management is on-call management: How does your team know that incidents are happening and need to be addressed?
To tackle this next batch of work, we’re going back to our Product Development Flow’s Problem Validation step. We’re talking to people to ensure we understand their needs. Then we’ll start to think about designs for on-call schedules, escalation policies, and paging. We intend to build and release these features early next year.
Once these features are introduced, we will have enabled the end-to-end workflow for incident management within GitLab, from triggered alerts through post-incident review. After that point, we’ll investigate how people are experiencing the features we’ve built and how we can further improve them.
We look forward to hearing your feedback, so we can continue to make incident management in GitLab even better. What do you want to see us build next? Leave a comment on the issue if you have any suggestions. Additionally, if you'd like to participate in our customer feedback sessions, consider joining our First Look panel. We'd love for you to join us!
Cover image credit:
Cover image by Kelly Sikkema on Unsplash