
Managing elastically scaled or highly available compute infrastructures is one of the key challenges the cloud was built for. Application scaling concerns can be handled by cloud services that are purpose designed, rigorously tested, and continually improved. This article dives into some specific enablement automation that brings the benefits of AWS Autoscaling Groups (ASG) to runner management. There are benefits to both the largest fleets and single instance runners.
Embedded in this article is a YouTube video that demonstrates the deployment of 100 GitLab runners on Amazon EC2 Spot compute in less than 10 minutes using less than 10 clicks. The video also shows updating this entire fleet in under 10 minutes to emphasize the time savings of built-in maintenace.
The information and automation in this article applies to GitLab Private Runners which are deployed on your own compute resources. Self-managed GitLab instances require private runners, but they can also be configured and used with GitLab.com SaaS accounts.
Well-architected runner management
There are many different reasons that a customer might need to deploy multiple runners with various characteristics. Some of the more popular ones are:
- Workloads that require large-scale runner fleets.
- To gain cost savings through Spot compute, uptime scheduling, and ARM architecture.
- Projects with high demand of CI activity to make sure that the runner is not being held up by jobs on another project.
- Jobs that have special security requirements, e.g., security credentials, role-based access or managed identities for Continuous Delivery (CD). These security requirements can enable instance-level (AWS IAM Instance Profile) security by allowing runners with sufficient rights to deploy in specific target environments. For example, a CD runner for non-production environments and a different runner for production.
- Implementing role-based access control rather than user-based. This means users don't have to use secrets to manage security requirements for CI jobs to accomplish their tasks.
- Development teams can be confident the runner has the same capabilities for CI and CD automation they test through their interactive logins by leveraging a common IAM role.
The challenges of building production-grade elastic GitLab Runners
The GitLab Runner is the workhorse of GitLab CI and CD capabilities. The runner can handle numerous operating environments and automation functions for a GitLab instance. The GitLab Runner has become very sophisticated due to the broad range of supported environments. In order to successfully configure the GitLab Runner as a set-it-and-forget-it service, the user has to work through many different decisions and considerations. We summarize some of the GitLab Runner-specific considerations that can be challenging:
- There are a lot of configuration options and scenarios to sort through. It can be an iterative process to discover what needs to be done to set up GitLab Runners.
- Ensuring runners are a production-grade capability requires Infrastructure as Code (IaC) development so that high availability and scaling can be achieved by automatically spawning new instances.
- Ensuring that runner deregistration happens correctly when GitLab Runners are automatically scaled in.
- Additional cost-saving configurations, such as Spot compute and scheduled runner uptime, can complicate the automation requirements for AWS Autoscaling Groups (ASGs).
- Large organizations often want developers to be able to easily self-service deploy runners with various configurations. Service Management Automation (SMA) has been made popular with products like Service Now, AWS Service Catalog, and AWS Control Tower. This automation is compatible with SMA.
- It can be difficult to map runners to AWS and map AWS to runners in large organizations with numerous runners and AWS accounts.
Introducing the GitLab HA Scaling Runner Vending Machine for AWS
An effective way to handle multiple design considerations is to make a reusable tool. To help you with best practice runner deployments on AWS, we created the GitLab HA Scaling Runner Vending Machine for AWS ("The GitLab Runner Vending Machine"). It is created in AWS’ Infrastructure as Code, known as CloudFormation.
Designed with AWS Well Architected: This automation has many features beyond the scope of this blog post. The primary focus of this blog post is on managing costs. See the full list of features here.
The GitLab Runner Vending Machine has the following cost management and scaling management benefits, exposed as a variety of parameters:
- The ability to leverage Spot compute instances. This is important because it leaves CI/CD pipeline developers in charge of whether specific Gitlab CI/CD jobs run on Spot compute or not.
- ASG-scheduled scaling so that a runner or runner fleet can be completely shutdown when not in use.
- The GitLab Runner Vending Machine can leverage ARM compute for Linux - which runs faster and costs less.
- It can also use ASG to update all runners in a fleet with the latest machine images and GitLab Runner version (or a specific version). When maintenance is not built-in, the labor cost of keeping things up-to-date can be significant.
- Runner naming and tagging in AWS and GitLab, which eases the burden of locating runner instances and managing orphaned runners registrations, whether it is manual or automated.
How to save money with The GitLab Runner Vending Machine
Significant savings are possible with this IaC, whether your team wants to save on a single runner or a fleet of them.
The savings calculations below are for a single runner and should be linear for a given workload. To calculate your savings for more runners, simply multiply the final result by the number of runner instances. The available "Runner Minutes" per hour is calculated as the runner's job concurrency setting multiplied by the minutes in an hour. For this exercise, we'll use job concurrency of "10". This number should be changed depending on the instance types you are using and the load testing of your typical CI/CD workloads.
Just like most performance analysis, we are assuming that hardware resource utilization is optimal and consistent. If a runner cluster can sustain respectable performance with 80% CPU loading, this calculation assumes that would be maintained regardless of the size of the cluster.
AWS Graviton ARM and Spot savings
The GitLab Runner engineering team has completed performance testing that demonstrates performance gains of more than 30% on some AWS Graviton (ARM-based) instance types. Assuming that runners are performance-managed for optimized utilization, this gain is a direct cost savings. Just recently, we shared how deploying GitLab on Arm-based AWS Graviton2 resulted in cost savings of 23% and 36% performance gains.
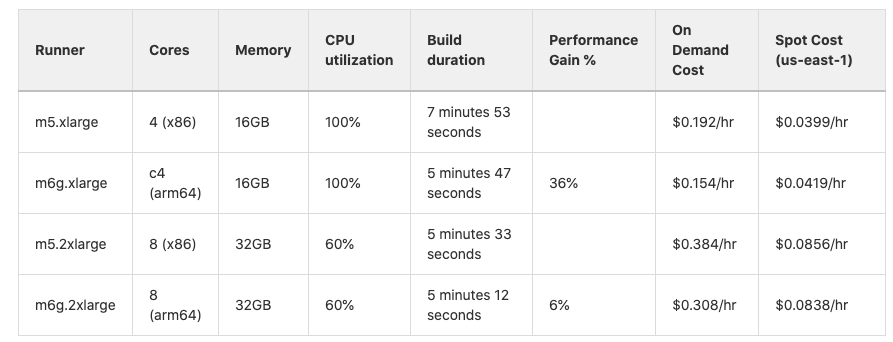 GitLab Runner testing results for ARM-efficiency gains.
GitLab Runner testing results for ARM-efficiency gains.
Scheduling savings
The savings can be dramatic when teams are able to turn off runners when not in use. For instance: Scheduling a runner to operate for 40-hours per week saves 76% when compared to the cost of running it for 168 hours. Runners that are just in use for 10 hours per week saves 94%.
Combining scheduling, Spot, and ARM to save 97%
Just for fun, let's see what savings are possible by comparing a standard runner scenario with deploying runners in customized, stand-alone instances to the maximum savings automation can deliver.
Imagine I am a developer who set up a custom GitLab Runner on an m5.xlarge instance, which is x86 the architecture, for a development team that works for 40 hours on the same time zone. Since there is no automation, the GitLab Runner runs 24/7. We will assume a job concurrency of 10, which gives 600 "runner minutes" per hour of run time. Scheduling uptime, running on Spot, and leveraging ARM can all be achieved quickly by redeploying the runner with The GitLab Runner Vending Machine.
Here is the calculation to run the configuration described above, for one week: On Demand, x86, Always On: 1 x m5.xlarge = .192/hr x 168 hrs/week = $32/week or $1664/year
Here are the savings that come from running Spot, ARM, and scheduling the Runner to be up just 40hrs/week: 1 x m6g.large Spot = .0419 x 40hrs/week x 64% (36% better performance) = $1/week
$1/$32 x 100 = 3.125% of the original cost for the same work. In other words, we just saved 97% without ever impacting the ability to get the job done.
In short, The GitLab Runner Vending Machine intends to bring the many cost saving mechanisms of AWS Cloud computing to your GitLab Runner fleets.
You can save costs by using ARM/Graviton instances, Spot compute, or by scheduling uptime. In many cases, you can combine all three savings mechanisms for maximum impact.
Special pipeline building concerns for Spot Runners
Spot instances can disappear with as little as two minutes of warning. This inevitably means some runners will be terminated while jobs are still in progress. CI/CD pipeline developers must take into account whether a job ought to run on compute resources that can disappear with short notice (so short as to be considered "no notice"). This comes down to deciding what jobs are OK to run on Spot and what jobs should instead run on AWS' persistent compute known as "On-Demand".
The GitLab Runner Vending Machine accounts for these constraints by tagging runner instances in GitLab with computetype-spot or computetype-ondemand – indicating in the "tags" segment of GitLab CI/CD jobs if a job should run on Spot compute.
Some types of CI workloads, e.g., mass performance testing or large unit testing suites, may already have work queues and work tracking that make it ideal for Spot compute. Other activities, e.g., polling another system for a deployment status, could suffer a material discrepancy if terminated permaturely. Others, such as building the application, are sort of in the middle. Usually, restarting the build is sufficient.
Job configuration for Spot
If you need to reschedule terminated work, it is helpful to configure GitLab’s job retry: keyword. When working with a dispatching engine or work queue that automatically accounts for incompleted work by processing agents, the retry configuration is unnecessary.
Here is an example that implements both of these concepts:
my-scaled-test-suite:
parallel: 100
tags:
- computetype-Spot
retry:
max: 2
when:
- runner_system_failure
- unknown_failure
The usage and limitations of retry: are discussed in greater detail in the GitLab CI documentation on retry.
How to get started
The CloudFormation templates for the GitLab Runner Vending Machine are managed in a public project on GitLab.com. There is a lot of information in the project about how the solution works and what problems it aims to solve, and will be useful for very experienced AWS builders.
But to keep it simple for users who want the quickest path to creating runners of all sizes, it also has an "easy button" page that has a table that looks like this:
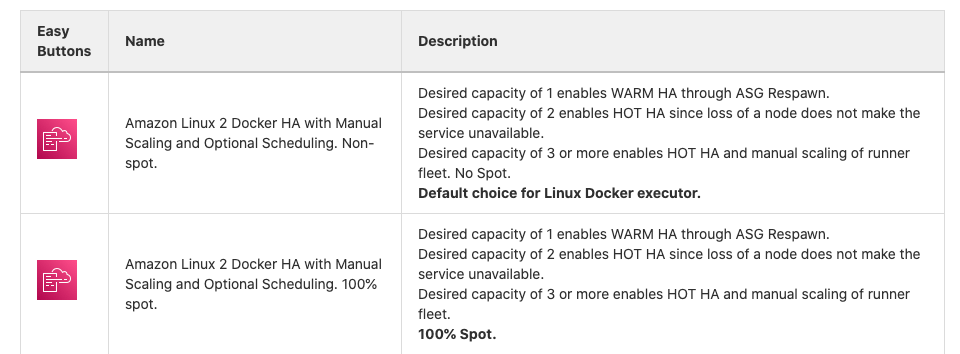 The easy buttons launch a CloudFormation Quick Create that only requires filling in a few fields.
The easy buttons launch a CloudFormation Quick Create that only requires filling in a few fields.
Keep in mind that easy buttons intentionally hide the high degree of customization that is possible with this automation by setting the parameters for the most common scenarios in advance. Advanced AWS users should read more of the documentation in the repository to understand that the GitLab Runner Vending Machine is also capable of creating sophisticated runner fleets.
First, click the CloudFormation icons to launch the Easy Button template directly into the CloudFormation Quick Create console. The Quick Create console is designed for simplicity to enable you to complete the prompts and then click one button to launch the stack.
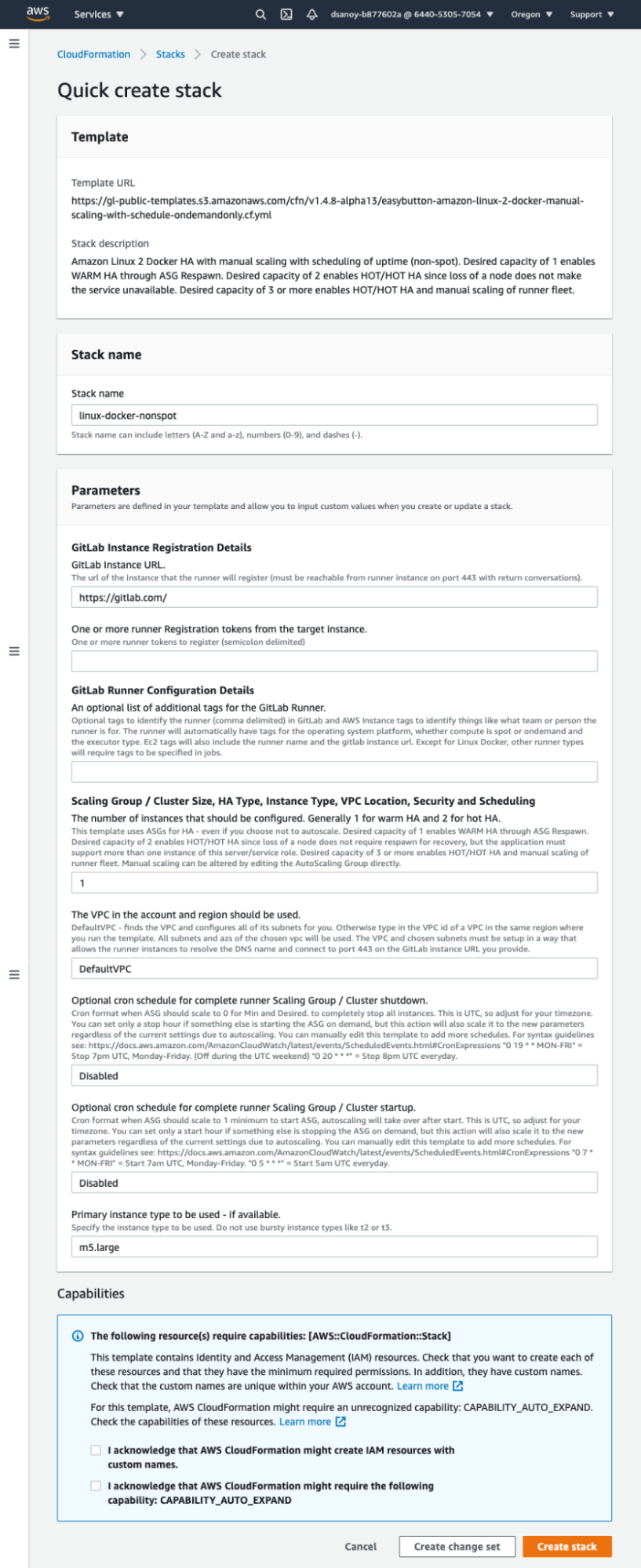 This is a typical Quick Create form for the GitLab Vending Machine easy buttons.
This is a typical Quick Create form for the GitLab Vending Machine easy buttons.
Next, select the deploy region by using the drop down menu in the upper right of the console (where the screenshot says "Oregon").
In most cases, you will only need to add your GitLab instance URL (GitLab.com is fine if that is where your repositories are), and the runner token, which you retrieve from the group level or project you wish to attach the runners to. If you are registering against a self-managed instance, you can use the instance-level tokens from the administrator console to register the runner for use across the entire instance. Read on for instructions for finding Runner Registration Tokens.
A few other customization parameters are available for your convenience.
Note that the automation attempts to use the default VPC of the region in which you deploy and the default security group for the VPC. In some organizations, default VPCs and/or their security groups are locked. You can deploy to custom VPCs by using the full template instead of an easy button. On the easy button page look for the footnote "Not any easy button person?"" to find a link to the full template.
Watch the video below to see the deployment of provisioning 100 GitLab Spot Runners on AWS in less than 10 minutes and in less than 10 clicks for just $5 per hour.
Check out the YouTube playlist for more relevant videos about GitLab and AWS
This automation does much, much more
While this article focused how much you can saving while using Spot for scaled runners, the underlying automation is capable of many other scenarios. Below is a summary of the additional features and benefits covered in the documentation.
- Scaled runners that are persistent (not Spot) (see more easy buttons here).
- Supports small, single runner setups and scaled ones.
- Supports GitLab.com SaaS or self-managed instances.
- Automates OS patching and Runner version upgrading.
- Supports Windows and Linux.
- Can be reused with Amazon provisioning services such as Service Catalog and Control Tower.
- Implements least privilege security throughout.
- Supports deregistering runners on scale-in or Spot termination.
A full feature list is in the document Features of GitLab HA Scaling Runner Vending Machine for AWS
Easy running
We hope that this automation will make deployment of runners of all sizes simple for you. We are open to your feedback, suggestions and contributions in the GitLab project.


