
In a recent blog post discussing the progress of integrating novel machine learning (ML) algorithms into GitLab we introduced our new ModelOps stage. This stage is focused on enabling and empowering data science workloads on GitLab. GitLab ModelOps aims to bring data science into GitLab within existing features to make them smarter and more intelligent and empowering GitLab customers to build and integrate data science workloads within GitLab.
An interesting question we hear a lot is how will this be useful for DevOps professionals? So we wanted to dive into who exactly we’re building ModelOps features for and why. To begin, here is an overview of how we’ve chosen to structure our new ModelOps stage.
ModelOps: Enabling and empowering data science workloads
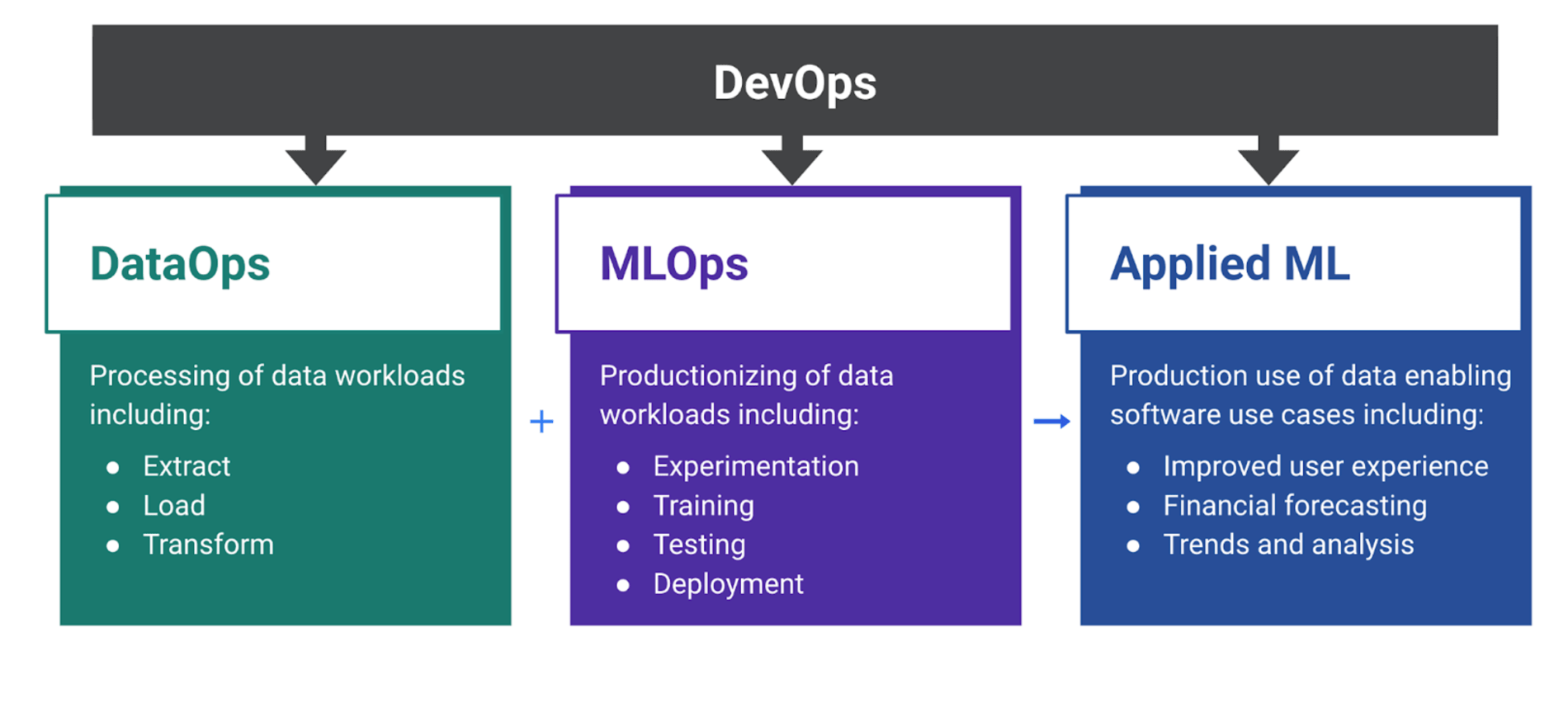
ModelOps is about taking all the best practices we’ve learned building a DevOps platform and applying them to the unique challenges of AI and ML workloads. Our ModelOps stage is divided into three primary groups: DataOps, MLOps, and AI Assisted. Each group has specific jobs to be done and challenges. Part of the reason we chose this organization model is due to the different user personas we’re trying to solve problems for in each of these areas. Now let’s dive into the people in each group, as well as the challenges each group aims to solve.
DataOps: Get the data, clean it, and process it
DataOps is focused on everything required to process data workloads, including fetching data, cleaning it, and processing it. You may have heard this called ELT, or Extract, Load, Transformation, of data. But DataOps is more than just the ELT, there are lots of other problems that come with data sources. For example, data located in many disparate systems in many formats and lacking common data definitions. Most data sources require a lot of processing to access, move, clean, and interpret data. We have specialists whose entire job is all of the work to get data into usable states so organizations can do something of business value with it.
Depending on the organization, these data professionals may have different titles such as data engineer, data architect, or data analyst. These data wranglers have many assorted jobs: aggregating disparate data sources, cleaning and shaping data into usable formats, making data available to the business, and even analyzing data and answering business questions.
The data experts leverage many tools such as ELT platforms, big data warehouses, data pipelines, and database technologies like SQL and elastic search. Data management tooling can be an extremely complex series of connections piping data in and out of various platforms. These challenges are the heart of the problems we’re aiming to solve.
MLOps: Do something useful with the data
Next is MLOps, which is what most people associate with data science. MLOps aims to enable customer data science use cases, including accessing and interacting with data, AI/ML toolchain integrations, and compute environment integrations. Basically, everything that is required to build, test, train, and deploy AI/ML models into production systems. MLOps leverages math to solve problems using computing power to find patterns in the data that we just discussed with DataOps.
Data science teams feature professionals with titles such as data scientists, ML engineers, or ML specialists. These experts usually have a mix of higher-level math and statistics skills, software engineering, and basic DevOps skills. They can cobble together environments to build, train, test, and explore data science models to solve specific business problems.
The work data scientists do is more than just building ML models. They have to understand the business data and problems they are trying to leverage data science to solve. It’s usually very experimental and requires a lot of iteration to find a solution that solves a particular business problem in a useful way. It’s common for data scientists to spend a lot of time exploring and understanding datasets and the business problems organizations are hoping data science can solve. They then build and train AI/ML models, evaluate model output, and then iterate their models.
Among the common tools these data scientists use are Python notebooks, which allow them to leverage scripting to explore and manipulate data and try different modeling techniques. They also may use many open source ML and data science frameworks, as well as special data science platforms that help manage, version, interpret, and monitor models. Most of this work almost never happens in production environments. It happens on local machines or in cloud computing platforms where data scientists can leverage highly specialized compute, optimized for running data science models. That leaves an interesting challenge of how do you deploy their work to production systems. Our last use case, DevOps, provides the solution.
AI Assisted: Leverage data to solve business problems
While our AI Assisted group isn't specifically focused on any one user persona, we are planning to enrich existing GitLab features with ML. Our goal is to take features that require manual work to leverage and apply ML to automate these tasks. Tasks like assigning and labeling issues, choosing code reviewers, and even triaging and fixing security vulnerabilities. You can read more about our AI Assisted plans on our direction page or check in on the status of our first Applied ML feature, suggested reviewers. Now that we've touched on improving GitLab for everyone, let's go back to GitLab's main persona, DevOps engineers.
DevOps: Build, test, and deploy software
DevOps is probably the most understood use case that we’re trying to solve with our ModelOps stage. However, we’re focused on the intersection of DevOps and data science workloads. Specifically what happens when you need to deploy a data science model to a production system. GitLab’s DevOps platform is already an established and mature platform for building, testing, and deploying traditional software applications. But the software stacks of modern organizations are evolving and becoming more sophisticated, including leveraging ML. We’ve described some of the challenges and new personas that are involved with the development of data science workloads, but what happens when it’s time to go to production?
Today, data science teams and DevOps engineers work in separate silos with very different skills sets and technology challenges. So when a data science team has a new ML model they want to push into a production software environment and integrate into a running application, in walks a whole new set of challenges.
Just about every software company now has DevOps teams focused on repeatability, stability, and velocity of software development lifecycles. Everything relating to the design, build, testing, deployment, security, and monitoring of software from idea to deploy into a production system. These teams are usually comprised of software engineers and DevOps engineers. The people who write, build, and test code with repeatable CI/CD, allowing software teams to seamlessly develop software applications.
Helping them all work together
Our goal with ModelOps is to help all of these people work together to build and deploy data-rich modern applications leveraging novel ML workloads. We want to bring data science into GitLab within existing features to make them smarter and more intelligent and to empower GitLab customers to build and integrate data science workloads in their own applications built and deployed with GitLab. Each of these groups has unique challenges and use cases that are interconnected. That’s part of what makes data science difficult. It has a lot of moving parts and crosses every aspect of modern software development lifecycles with very unique challenges.
If all of this is interesting to you, you may also enjoy watching our recent Contribute session, where we discuss more about what we plan to accomplish with our ModelOps stage, which you can watch on YouTube.
This blog post contains information related to upcoming products, features and functionality.
It is important to note that the information in this blog post is for informational purposes only. Please do not rely on this information for purchasing or planning purposes.
As with all projects, the items mentioned in this blog post and linked pages are subject to change and delay. The development, release, and timing of any products, features, or functionality remain at the sole discretion of GitLab Inc.


