Published on: February 1, 2023
40 min read
Efficient DevSecOps workflows: Hands-on python-gitlab API automation
The python-gitlab library is a useful abstraction layer for the GitLab API. Dive into hands-on examples and best practices in this tutorial.


A friend once said in a conference presentation, “Manual work is a bug." When there are repetitive tasks in workflows, I tend to come back to this quote, and try to automate as much as possible. For example, by querying a REST API to do an inventory of settings, or calling API actions to create new comments in GitLab issues/merge requests. The interaction with the GitLab REST API can be done in different ways, using HTTP requests with curl (or hurl) on the command line, or by writing a script in a programming language. The latter can become reinventing the wheel again with raw HTTP requests code, and parsing the JSON responses.
Thanks to the wider GitLab community, many different languages are supported by API abstraction libraries. They provide support for all API attributes, add helper functions to get/create/delete objects, and generally aim to help developers focus. The python-gitlab library is a feature-rich and easy-to-use library written in Python.
In this blog post, you will learn about the basic usage of the library by working with API objects, attributes, pagination and resultsets, and dive into more concrete use cases collecting data, printing summaries and writing data to the API to create comments and commits. There is a whole lot more to learn, with many of the use cases inspired by wider community questions on the forum, Hacker News, issues, etc.
This blog post is a long read, so feel free to stick with the beginner's tutorial or skip to the advanced DevSecOps use cases, development tips and code optimizations by navigating the table of contents:
- Getting started
- Configuration
- Managing objects: The GitLab Object
- DevSecOps use cases for API read actions
- List branches by merged state
- Print project settings for review: MR approval rules
- Inventory: Get all CI/CD variables that are protected or masked
- Download a file from the repository
- Migration help: List all certificate-based Kubernetes clusters
- Team efficiency: Check if existing merge requests need to be rebased after merging a huge refactoring MR
- DevSecOps use cases for API write actions
- Advanced DevSecOps workflows
- Development tips
- Optimize code and performance
- More use cases
- Conclusion
Getting started
The python-gitlab documentation is a great resource for getting started guides, object types and their available methods, and combined workflow examples. Together with the GitLab API resources documentation, which provides the object attributes that can be used, these are the best resources to get going.
The code examples in this blog post require Python 3.8+, and the python-gitlab library. Additional requirements are specified in the requirements.txt file – one example requires pyyaml for YAML config parsing. To follow and practice the use cases code, it is recommended to clone the project, install the requirements and run the scripts. Example with Homebrew on macOS:
git clone https://gitlab.com/gitlab-da/use-cases/gitlab-api/gitlab-api-python.git
cd gitlab-api-python
brew install python
pip3 install -r requirements.txt
python3 <scriptname>.py
The scripts are intentionally not using a common shared library that provides generic functions for parameter reads, or additional helper functionality, for example. The idea is to show easy-to-follow examples that can be used stand-alone for testing, and only require installing the python-gitlab library as a dependency. Improving the code for production use is recommended. This can also help with building a maintained API tooling project that, for example, includes container images and CI/CD templates for developers to consume on a DevSecOps platform.
Configuration
Without configuration, python-gitlab will run unauthenticated requests against the default server https://gitlab.com. The most common configuration settings relate to the GitLab instance to connect to, and the authentication method by specifying access tokens. Python-gitlab supports different types of configuration: A configuration file or environment variables.
The configuration file is available for the API library bindings, and the CLI (the CLI is not explained in this blog post). The configuration file supports credential helpers to access tokens directly.
Environment variables as an alternative configuration method provide an easy way to run the script on terminal, integrate into container images, and prepare them for running in CI/CD pipelines.
The configuration needs to be loaded into the Python script context. Start by importing the os library to fetch environment variables using the os.environ.get() method. The first parameter specifies the key, the second parameter sets the default value when the variable is not available in the environment.
import os
gl_server = os.environ.get('GL_SERVER', 'https://gitlab.com')
print(gl_server)
The parametrization on the terminal can happen directly for the command only, or exported into the shell environment.
$ GL_SERVER=’https://gitlab.company.com’ python3 script.py
$ export GL_SERVER=’https://gitlab.company.com’
$ python3 script.py
It is recommended to add safety checks to ensure that all variables are set before continuing to run the program. The following snippet imports the required libraries, reads the GL_SERVER environment variable and expects the user to set the GL_TOKEN variable. If not, the script prints and throws errors, and calls sys.exit(1) indicating an error status.
import gitlab
import os
import sys
GITLAB_SERVER = os.environ.get('GL_SERVER', 'https://gitlab.com')
GITLAB_TOKEN = os.environ.get('GL_TOKEN')
if not GITLAB_TOKEN:
print("Please set the GL_TOKEN env variable.")
sys.exit(1)
We will look into a more detailed example now which creates a connection to the API and makes an actual data request.
Managing objects: The GitLab object
Any interaction with the API requires the GitLab object to be instantiated. This is the entry point to configure the GitLab server to connect, authenticate using access tokens, and more global settings for pagination, object loading and more.
The following example runs an unauthenticated request against GitLab.com. It is possible to access public API endpoints and for example get a specific .gitignore template for Python.
python_gitlab_object_unauthenticated.py
import gitlab
gl = gitlab.Gitlab()
# Get .gitignore templates without authentication
gitignore_templates = gl.gitignores.get('Python')
print(gitignore_templates.content)
The next sections provide more insights into:
- Objects managers and loading
- Pagination of results
- Working with object relationships
- Working with different object collection scopes
Objects managers and loading
The python-gitlab library provides access to GitLab resources using so-called “managers". Each manager type implements methods to work with the datasets (list, get, etc.).
The script shows how to access subgroups, direct projects, all projects including subgroups, issues, epics and todos. These methods and API endpoint require authentication to access all attributes. The code snippet, therefore, uses variables to get the authentication token, and also uses the GROUP_ID variable to specify a main group at which to start searching.
#!/usr/bin/env python
import gitlab
import os
import sys
GITLAB_SERVER = os.environ.get('GL_SERVER', 'https://gitlab.com')
# https://gitlab.com/gitlab-da/use-cases/
GROUP_ID = os.environ.get('GL_GROUP_ID', 16058698)
GITLAB_TOKEN = os.environ.get('GL_TOKEN')
if not GITLAB_TOKEN:
print("Please set the GL_TOKEN env variable.")
sys.exit(1)
gl = gitlab.Gitlab(GITLAB_SERVER, private_token=GITLAB_TOKEN)
# Main
main_group = gl.groups.get(GROUP_ID)
print("Sub groups")
for sg in main_group.subgroups.list():
print("Subgroup name: {sg}".format(sg=sg.name))
print("Projects (direct)")
for p in main_group.projects.list():
print("Project name: {p}".format(p=p.name))
print("Projects (including subgroups)")
for p in main_group.projects.list(include_subgroups=True, all=True):
print("Project name: {p}".format(p=p.name))
print("Issues")
for i in main_group.issues.list(state='opened'):
print("Issue title: {t}".format(t=i.title))
print("Epics")
for e in main_group.issues.list():
print("Epic title: {t}".format(t=e.title))
print("Todos")
for t in gl.todos.list(state='pending'):
print("Todo: {t} url: {u}".format(t=t.body, u=t.target_url
You can run the script python_gitlab_object_manager_methods.py by overriding the GROUP_ID variable on GitLab.com SaaS for your own group to analyze. The GL_SERVER variable needs to be specified for self-managed instance targets. GL_TOKEN must provide the personal access token.
export GL_TOKEN=xxx
export GL_SERVER=”https://gitlab.company.com”
export GL_SERVER=”https://gitlab.com”
export GL_GROUP_ID=1234
python3 python_gitlab_object_manager_methods.py
Going forward, the example snippets won’t show the Python headers and environment variable parsing to focus on the algorithm and functionality. All scripts are open source under the MIT license and available in this project.
Pagination of results
By default, the GitLab API does not return all result sets and requires the clients to use pagination to iterate through all result pages. The python-gitlab library allows users to specify the settings globally in the GitLab object, or on each list() call. By default, all result sets would fire API requests, which can slow down the script execution. The recommended way is using iterator=True which returns a generator object, and API calls are fired on-demand when accessing the object.
The following example searches for the group name everyonecancontribute, and uses keyset pagination with 100 results on each page. The iterator is set to true on gl.groups.list(iterator=True) to fetch new result sets on demand. If the searched group name is found, the loop breaks and prints a summary, including measuring the duration of the complete search request.
SEARCH_GROUP_NAME="everyonecancontribute"
# Use keyset pagination
# https://python-gitlab.readthedocs.io/en/stable/api-usage.html#pagination
gl = gitlab.Gitlab(GITLAB_SERVER, private_token=GITLAB_TOKEN,
pagination="keyset", order_by="id", per_page=100)
# Iterate over the list, and fire new API calls in case the result set does not match yet
groups = gl.groups.list(iterator=True)
found_page = 0
start = timer()
for group in groups:
if SEARCH_GROUP_NAME == group.name:
# print(group) # debug
found_page = groups.current_page
break
end = timer()
duration = f'{end-start:.2f}'
if found_page > 0:
print("Pagination API example for Python with GitLab{desc} - found group {g} on page {p}, duration {d}s".format(
desc=", the DevSecOps platform", g=SEARCH_GROUP_NAME, p=found_page, d=duration))
else:
print("Could not find group name '{g}', duration {d}".format(g=SEARCH_GROUP_NAME, d=duration))
Executing python_gitlab_pagination.py found the everyonecancontribute group on page 5.
$ python3 python_gitlab_pagination.py
Pagination API example for Python with GitLab, the DevSecOps platform - found group everyonecancontribute on page 5, duration 8.51s
Working with object relationships
When working with object relationships – for example, collecting all projects in a given group – additional steps need to be taken. The returned project objects provide limited attributes by default. Manageable objects require an additional get() call which requests the full project object from the API in the background. This on-demand workflow helps to avoid waiting times and traffic by reducing the immediately returned attributes.
The following example illustrates the problem by looping through all projects in a group, and tries to call the project.branches.list() function, raising an exception in the try/except flow. The second example gets a manageable project object and tries the function call again.
# Main
group = gl.groups.get(GROUP_ID)
# Collect all projects in group and subgroups
projects = group.projects.list(include_subgroups=True, all=True)
for project in projects:
# Try running a method on a weak object
try:
print("🤔 Project: {pn} 💡 Branches: {b}\n".format(
pn=project.name,
b=", ".join([x.name for x in project.branches.list()])))
except Exception as e:
print("Got exception: {e} \n ===================================== \n".format(e=e))
# Retrieve a full manageable project object
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/groups.html#examples
manageable_project = gl.projects.get(project.id)
# Print a method available on a manageable object
print("🤔 Project: {pn} 💡 Branches: {b}\n".format(
pn=manageable_project.name,
b=", ".join([x.name for x in manageable_project.branches.list()])))
The exception handler in the python-gitlab library prints the error message, and also links to the documentation. It is helpful to take a debugging note that objects might not be available to manage whenever you cannot access object attributes or function calls.
$ python3 python_gitlab_manageable_objects.py
🤔 Project: GitLab API Playground 💡 Branches: cicd-demo-automated-comments, docs-mr-approval-settings, main
Got exception: 'GroupProject' object has no attribute 'branches'
<class 'gitlab.v4.objects.projects.GroupProject'> was created via a
list() call and only a subset of the data may be present. To ensure
all data is present get the object using a get(object.id) call. For
more details, see:
https://python-gitlab.readthedocs.io/en/v3.8.1/faq.html#attribute-error-list
=====================================
The full script is located here.
Working with different object collection scopes
Sometimes, the script needs to collect all projects from a self-managed instance, or from a group with subgroups, or from a single project. The latter is helpful for faster testing on the required attributes, and the group fetch helps with testing at scale later. The following snippet collects all project objects into the projects list, and appends objects from different incoming configuration. You will also see the manageable object pattern for project in groups again.
# Collect all projects, or prefer projects from a group id, or a project id
projects = []
# Direct project ID
if PROJECT_ID:
projects.append(gl.projects.get(PROJECT_ID))
# Groups and projects inside
elif GROUP_ID:
group = gl.groups.get(GROUP_ID)
for project in group.projects.list(include_subgroups=True, all=True):
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/groups.html#examples
manageable_project = gl.projects.get(project.id)
projects.append(manageable_project)
# All projects on the instance (may take a while to process)
else:
projects = gl.projects.list(get_all=True)
The full example is located in this script for listing MR approval rules settings for specified project targets.
DevSecOps use cases for API read actions
The authenticated access token needs read_api scope.
The following use cases are discussed:
- List branches by merged state
- Print project settings for review: MR approval rules
- Inventory: Get all CI/CD variables that are protected or masked
- Download a file from the repository
- Migration help: List all certificate-based Kubernetes clusters
- Team efficiency: Check if existing merge requests need to be rebased after merging a huge refactoring MR
List branches by merged state
A common ask is to do some Git housekeeping in the project, and see how many merged and unmerged branches are floating around. A question on the GitLab community forum about filtering branch listings inspired me look into writing a script that helps achieve this goal. The branches.list() method returns all branch objects that are stored in a temporary list for later processing for two loops: Collecting merged branch names, and not merged branch names. The merged attribute on the branch object is a boolean value indicating whether the branch has been merged.
project = gl.projects.get(PROJECT_ID, lazy=False, pagination="keyset", order_by="updated_at", per_page=100)
# Get all branches
real_branches = []
for branch in project.branches.list():
real_branches.append(branch)
print("All branches")
for rb in real_branches:
print("Branch: {b}".format(b=rb.name))
# Get all merged branches
merged_branches_names = []
for branch in real_branches:
if branch.default:
continue # ignore the default branch for merge status
if branch.merged:
merged_branches_names.append(branch.name)
print("Branches merged: {b}".format(b=", ".join(merged_branches_names)))
# Get un-merged branches
not_merged_branches_names = []
for branch in real_branches:
if branch.default:
continue # ignore the default branch for merge status
if not branch.merged:
not_merged_branches_names.append(branch.name)
print("Branches not merged: {b}".format(b=", ".join(not_merged_branches_names)))
The workflow is intentionally a step-by-step read, you can practice optimizing the Python code for the conditional branch name collection.
Print project settings for review: MR approval rules
The following script walks through all collected project objects, and checks whether approval rules are specified. If the list length is greater than zero, it loops over the list and prints the settings using a JSON pretty-print method.
# Loop over projects and print the settings
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/merge_request_approvals.html
for project in projects:
if len(project.approvalrules.list()) > 0:
#print(project) #debug
print("# Project: {name}, ID: {id}\n\n".format(name=project.name_with_namespace, id=project.id))
print("[MR Approval settings]({url}/-/settings/merge_requests)\n\n".format(url=project.web_url))
for ar in project.approvalrules.list():
print("## Approval rule: {name}, ID: {id}".format(name=ar.name, id=ar.id))
print("\n```json\n")
print(json.dumps(ar.attributes, indent=2)) # TODO: can be more beautiful, but serves its purpose with pretty print JSON
print("\n```\n")
Inventory: Get all CI/CD variables that are protected or masked
CI/CD variables are helpful for pipeline parameterization, and can be configured globally on the instance, in groups and in projects. Secrets, passwords and otherwise sensitive information could be stored there, too. Sometimes it can be necessary to get an overview of all CI/CD variables that are either protected or masked to get a sense of how many variables need to be updated when rotating tokens for example.
The following script gets all groups and projects and tries to collect the CI/CD variables from the global instance (requires admin permissions), groups and projects (requires maintainer/owner permissions). It prints all CI/CD variables that are either protected or masked, adding that a potential secret value is stored.
#!/usr/bin/env python
import gitlab
import os
import sys
# Helper function to evaluate secrets and print the variables
def eval_print_var(var):
if var.protected or var.masked:
print("🛡️🛡️🛡️ Potential secret: Variable '{name}', protected {p}, masked: {m}".format(name=var.key,p=var.protected,m=var.masked))
GITLAB_SERVER = os.environ.get('GL_SERVER', 'https://gitlab.com')
GITLAB_TOKEN = os.environ.get('GL_TOKEN') # token requires maintainer+ permissions. Instance variables require admin access.
PROJECT_ID = os.environ.get('GL_PROJECT_ID') #optional
GROUP_ID = os.environ.get('GL_GROUP_ID', 8034603) # https://gitlab.com/everyonecancontribute
if not GITLAB_TOKEN:
print("🤔 Please set the GL_TOKEN env variable.")
sys.exit(1)
gl = gitlab.Gitlab(GITLAB_SERVER, private_token=GITLAB_TOKEN)
# Collect all projects, or prefer projects from a group id, or a project id
projects = []
# Collect all groups, or prefer group from a group id
groups = []
# Direct project ID
if PROJECT_ID:
projects.append(gl.projects.get(PROJECT_ID))
# Groups and projects inside
elif GROUP_ID:
group = gl.groups.get(GROUP_ID)
for project in group.projects.list(include_subgroups=True, all=True):
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/groups.html#examples
manageable_project = gl.projects.get(project.id)
projects.append(manageable_project)
groups.append(group)
# All projects/groups on the instance (may take a while to process, use iterators to fetch on-demand).
else:
projects = gl.projects.list(iterator=True)
groups = gl.groups.list(iterator=True)
print("# List of all CI/CD variables marked as secret (instance, groups, projects)")
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/variables.html
# Instance variables (if the token has permissions)
print("Instance variables, if accessible")
try:
for i_var in gl.variables.list(iterator=True):
eval_print_var(i_var)
except:
print("No permission to fetch global instance variables, continueing without.")
print("\n")
# group variables (maintainer permissions for groups required)
for group in groups:
print("Group {n}, URL: {u}".format(n=group.full_path, u=group.web_url))
for g_var in group.variables.list(iterator=True):
eval_print_var(g_var)
print("\n")
# Loop over projects and print the settings
for project in projects:
# skip archived projects, they throw 403 errors
if project.archived:
continue
print("Project {n}, URL: {u}".format(n=project.path_with_namespace, u=project.web_url))
for p_var in project.variables.list(iterator=True):
eval_print_var(p_var)
print("\n")
The script intentionally does not print the variable values, this is left as an exercise for safe environments. The recommended way of storing secrets is to use external providers.
Download a file from the repository
The script goal is download a file path from a specified branch name, and store its content in a new file.
# Goal: Try to download README.md from https://gitlab.com/gitlab-da/use-cases/gitlab-api/gitlab-api-python/-/blob/main/README.md
FILE_NAME = 'README.md'
BRANCH_NAME = 'main'
# Search the file in the repository tree and get the raw blob
for f in project.repository_tree():
print("File path '{name}' with id '{id}'".format(name=f['name'], id=f['id']))
if f['name'] == FILE_NAME:
f_content = project.repository_raw_blob(f['id'])
print(f_content)
# Alternative approach: Get the raw file from the main branch
raw_content = project.files.raw(file_path=FILE_NAME, ref=BRANCH_NAME)
print(raw_content)
# Store the file on disk
with open('raw_README.md', 'wb') as f:
project.files.raw(file_path=FILE_NAME, ref=BRANCH_NAME, streamed=True, action=f.write)
Migration help: List all certificate-based Kubernetes clusters
The certificate-based integration of Kubernetes clusters into GitLab was deprecated. To help with migration plans, the inventory of existing groups and projects can be automated using the GitLab API.
groups = [ ]
# get GROUP_ID group
groups.append(gl.groups.get(GROUP_ID))
for group in groups:
for sg in group.subgroups.list(include_subgroups=True, all=True):
real_group = gl.groups.get(sg.id)
groups.append(real_group)
group_clusters = {}
project_clusters = {}
for group in groups:
#Collect group clusters
g_clusters = group.clusters.list()
if len(g_clusters) > 0:
group_clusters[group.id] = g_clusters
# Collect all projects in group and subgroups and their clusters
projects = group.projects.list(include_subgroups=True, all=True)
for project in projects:
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/groups.html#examples
manageable_project = gl.projects.get(project.id)
# skip archived projects
if project.archived:
continue
p_clusters = manageable_project.clusters.list()
if len(p_clusters) > 0:
project_clusters[project.id] = p_clusters
# Print summary
print("## Group clusters\n\n")
for g_id, g_clusters in group_clusters.items():
url = gl.groups.get(g_id).web_url
print("Group ID {g_id}: {u}\n\n".format(g_id=g_id, u=url))
print_clusters(g_clusters)
print("## Project clusters\n\n")
for p_id, p_clusters in project_clusters.items():
url = gl.projects.get(p_id).web_url
print("Project ID {p_id}: {u}\n\n".format(p_id=p_id, u=url))
print_clusters(p_clusters)
The full script is available here.
Team efficiency: Check if existing merge requests need to be rebased after merging a huge refactoring MR
The GitLab handbook repository is a large monorepo with many merge requests created, reviewed, approved and merged. Some reviews take longer than others, and some merge requests touch multiple pages when renaming a string, or all handbook pages. The marketing handbook needed restructuring (think of code refactoring), and as such, many directories and paths were moved or renamed. The issue tasks grew over time, and I was worried that other merge requests would run into conflicts after merging the huge changes. I remembered that the python-gitlab can fetch all merge requests in a given project, including details on the Git branch, source paths changed and much more.
The resulting script configures a list of source paths that are touched by all merge requests, and checks against the merge request diff with mr.diffs.list() and comparing if a pattern matches against the value in old_path. If a match is found, the script logs it, and saves the merge request in the seen_mr dictionary for the summary later. There are additional attributes collected to allow printing a Markdown task list with URLs for easier copy-paste into issue descriptions. The full script is located here.
PATH_PATTERNS = [
'path/to/handbook/source/page.md',
]
# Only list opened MRs
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/merge_requests.html#project-merge-requests
mrs = project.mergerequests.list(state='opened', iterator=True)
seen_mr = {}
for mr in mrs:
# https://docs.gitlab.com/api/merge_requests/#list-merge-request-diffs
real_mr = project.mergerequests.get(mr.get_id())
real_mr_id = real_mr.attributes['iid']
real_mr_url = real_mr.attributes['web_url']
for diff in real_mr.diffs.list(iterator=True):
real_diff = real_mr.diffs.get(diff.id)
for d in real_diff.attributes['diffs']:
for p in PATH_PATTERNS:
if p in d['old_path']:
print("MATCH: {p} in MR {mr_id}, status '{s}', title '{t}' - URL: {mr_url}".format(
p=p,
mr_id=real_mr_id,
s=mr_status,
t=real_mr.attributes['title'],
mr_url=real_mr_url))
if not real_mr_id in seen_mr:
seen_mr[real_mr_id] = real_mr
print("\n# MRs to update\n")
for id, real_mr in seen_mr.items():
print("- [ ] !{mr_id} - {mr_url}+ Status: {s}, Title: {t}".format(
mr_id=id,
mr_url=real_mr.attributes['web_url'],
s=real_mr.attributes['detailed_merge_status'],
t=real_mr.attributes['title']))
DevSecOps use cases for API write actions
The authenticated access token needs full api scope.
The following use cases are discussed:
- Move epics between groups
- Compliance: Ensure that project settings are not overridden
- Taking notes, generate due date overview
- Create issue index in a Markdown file, grouped by labels
Move epics between groups
Sometimes it is necessary to move epics, similar to issues, into a different group. A question in the GitLab marketing Slack channel inspired me to look into a feature proposal for the UI, quick actions, and later, thinking about writing an API script to automate the steps. The idea is simple: Move an epic from a source group to a target group, and copy its title, description and labels. Since epics allow to group issues, they need to be reassigned to the target epic, too. Parent-child epic relationships need to be taken into account to: All child epics of the source epics need to be reassigned to the target epic.
The following script looks up all source epic attributes first, and then creates a new target epic with minimal attributes: title and description. The labels list is copied and the changes are persisted with the save() call. The issues assigned to the epic need to be re-created in the target epic. The create() call actually creates the relationship item, not a new issue object itself. The child epics move requires a different approach, since the relationship is vice versa: The parent_id on the child epic needs to be compared against the source epic ID, and if matching, updated to the target epic ID. After copying everything successfully, the source epic needs to be changed into the closed state.
#!/usr/bin/env python
# Description: Show how epics can be moved between groups, including title, description, labels, child epics and issues.
# Requirements: python-gitlab Python libraries. GitLab API write access, and maintainer access to all configured groups/projects.
# Author: Michael Friedrich <[email protected]>
# License: MIT, (c) 2023-present GitLab B.V.
import gitlab
import os
import sys
GITLAB_SERVER = os.environ.get('GL_SERVER', 'https://gitlab.com')
# https://gitlab.com/gitlab-da/use-cases/gitlab-api
SOURCE_GROUP_ID = os.environ.get('GL_SOURCE_GROUP_ID', 62378643)
# https://gitlab.com/gitlab-da/use-cases/gitlab-api/epic-move-target
TARGET_GROUP_ID = os.environ.get('GL_TARGET_GROUP_ID', 62742177)
# https://gitlab.com/groups/gitlab-de/use-cases/gitlab-api/-/epics/1
EPIC_ID = os.environ.get('GL_EPIC_ID', 1)
GITLAB_TOKEN = os.environ.get('GL_TOKEN')
if not GITLAB_TOKEN:
print("Please set the GL_TOKEN env variable.")
sys.exit(1)
gl = gitlab.Gitlab(GITLAB_SERVER, private_token=GITLAB_TOKEN)
# Main
# Goal: Move epic to target group, including title, body, labels, and child epics and issues.
source_group = gl.groups.get(SOURCE_GROUP_ID)
target_group = gl.groups.get(TARGET_GROUP_ID)
# Create a new target epic and copy all its items, then close the source epic.
source_epic = source_group.epics.get(EPIC_ID)
# print(source_epic) #debug
epic_title = source_epic.title
epic_description = source_epic.description
epic_labels = source_epic.labels
epic_issues = source_epic.issues.list()
# Create the epic with minimal attributes
target_epic = target_group.epics.create({
'title': epic_title,
'description': epic_description,
})
# Assign the list
target_epic.labels = epic_labels
# Persist the changes in the new epic
target_epic.save()
# Epic issues need to be re-assigned in a loop
for epic_issue in epic_issues:
ei = target_epic.issues.create({'issue_id': epic_issue.id})
# Child epics need to update their parent_id to the new epic
# Need to search in all epics, use lazy object loading
for sge in source_group.epics.list(lazy=True):
# this epic has the source epic as parent epic?
if sge.parent_id == source_epic.id:
# Update the parent id
sge.parent_id = target_epic.id
sge.save()
print("Copied source epic {source_id} ({source_url}) to target epic {target_id} ({target_url})".format(
source_id=source_epic.id, source_url=source_epic.web_url,
target_id=target_epic.id, target_url=target_epic.web_url))
# Close the old epic
source_epic.state_event = 'close'
source_epic.save()
print("Closed source epic {source_id} ({source_url})".format(
source_id=source_epic.id, source_url=source_epic.web_url))
$ python3 move_epic_between_groups.py
Copied source epic 725341 (https://gitlab.com/groups/gitlab-de/use-cases/gitlab-api/-/epics/1) to target epic 725358 (https://gitlab.com/groups/gitlab-de/use-cases/gitlab-api/epic-move-target/-/epics/6)
Closed source epic 725341 (https://gitlab.com/groups/gitlab-de/use-cases/gitlab-api/-/epics/1)
The target epic was created and shows the expected result: Same title, description, labels, child epic, and issues.
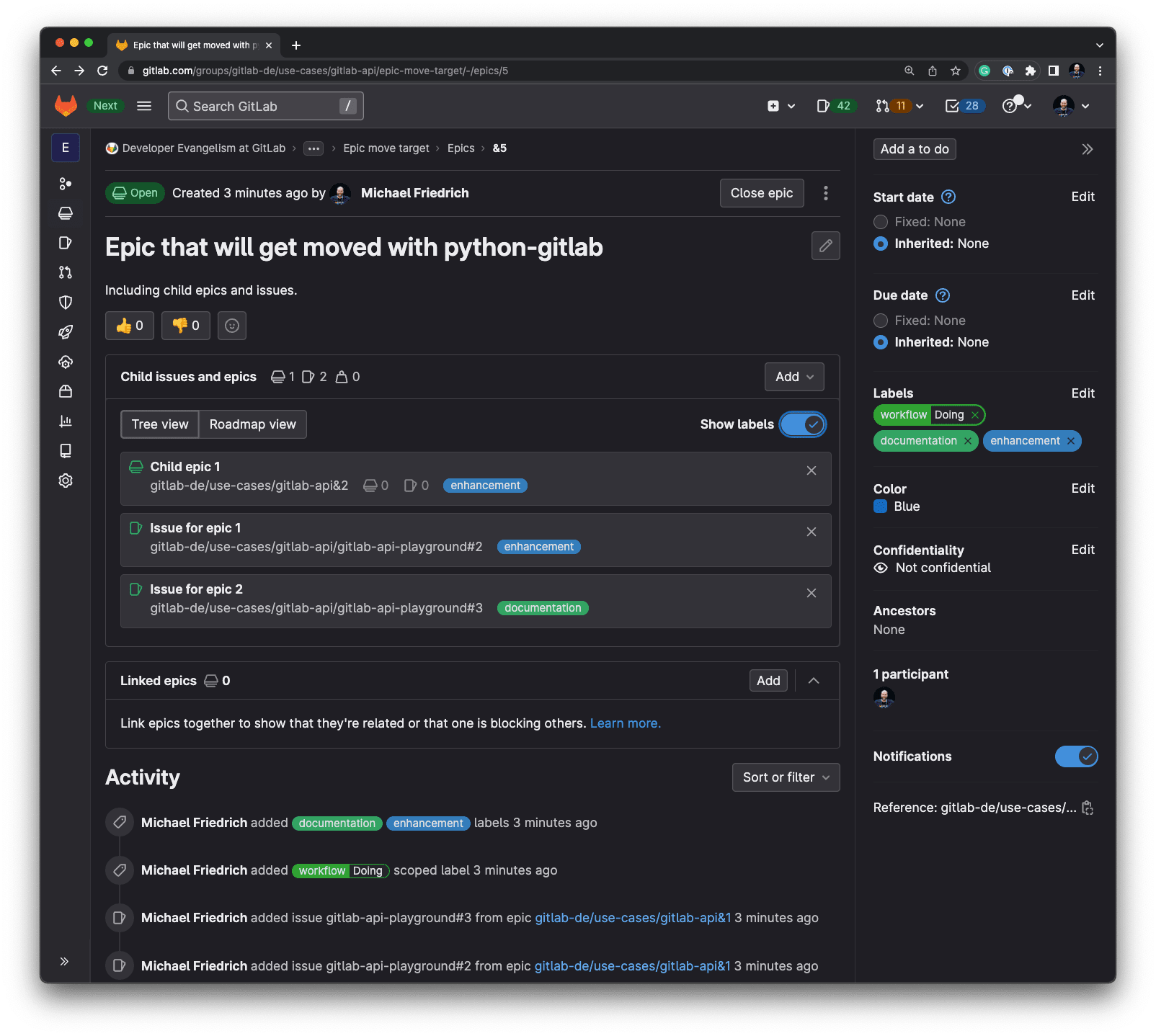
Exercise: The script does not copy comments and discussion threads yet. Research and help update the script – merge requests welcome!
Compliance: Ensure that project settings are not overridden
Project and group settings may be accidentally changed by team members with maintainer permissions. Compliance requirements need to be met. Another use case is to manage configuration with Infrastructure as Code tools, and ensure that GitLab instance/group/project/etc. configuration is persisted and always the same. Tools like Ansible or Terraform can invoke an API script, or use the python-gitlab library to perform tasks to manage settings.
The following example only has the main branch protected.

Let us assume that a new production branch has been added and should be protected, too. The following script defines the dictionary of protected branches and their access levels for push/merge permissions to maintainer level, and builds the comparison logic around the python-gitlab protected branches documentation.
#!/usr/bin/env python
import gitlab
import os
import sys
GITLAB_SERVER = os.environ.get('GL_SERVER', 'https://gitlab.com')
# https://gitlab.com/gitlab-da/use-cases/
GROUP_ID = os.environ.get('GL_GROUP_ID', 16058698)
GITLAB_TOKEN = os.environ.get('GL_TOKEN')
PROTECTED_BRANCHES = {
'main': {
'merge_access_level': gitlab.const.AccessLevel.MAINTAINER,
'push_access_level': gitlab.const.AccessLevel.MAINTAINER
},
'production': {
'merge_access_level': gitlab.const.AccessLevel.MAINTAINER,
'push_access_level': gitlab.const.AccessLevel.MAINTAINER
},
}
if not GITLAB_TOKEN:
print("Please set the GL_TOKEN env variable.")
sys.exit(1)
gl = gitlab.Gitlab(GITLAB_SERVER, private_token=GITLAB_TOKEN)
# Main
group = gl.groups.get(GROUP_ID)
# Collect all projects in group and subgroups
projects = group.projects.list(include_subgroups=True, all=True)
for project in projects:
# Retrieve a full manageable project object
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/groups.html#examples
manageable_project = gl.projects.get(project.id)
# https://python-gitlab.readthedocs.io/en/stable/gl_objects/protected_branches.html
protected_branch_names = []
for pb in manageable_project.protectedbranches.list():
manageable_protected_branch = manageable_project.protectedbranches.get(pb.name)
print("Protected branch name: {n}, merge_access_level: {mal}, push_access_level: {pal}".format(
n=manageable_protected_branch.name,
mal=manageable_protected_branch.merge_access_levels,
pal=manageable_protected_branch.push_access_levels
))
protected_branch_names.append(manageable_protected_branch.name)
for branch_to_protect, levels in PROTECTED_BRANCHES.items():
# Fix missing protected branches
if branch_to_protect not in protected_branch_names:
print("Adding branch {n} to protected branches settings".format(n=branch_to_protect))
p_branch = manageable_project.protectedbranches.create({
'name': branch_to_protect,
'merge_access_level': gitlab.const.AccessLevel.MAINTAINER,
'push_access_level': gitlab.const.AccessLevel.MAINTAINER
})
Running the script prints the existing main branch, and a note that production will be updated. The screenshot from the repository settings proves this action.
$ python3 enforce_protected_branches.py ─╯
Protected branch name: main, merge_access_level: [{'id': 67294702, 'access_level': 40, 'access_level_description': 'Maintainers', 'user_id': None, 'group_id': None}], push_access_level: [{'id': 68546039, 'access_level': 40, 'access_level_description': 'Maintainers', 'user_id': None, 'group_id': None}]
Adding branch production to protected branches settings

Taking notes, generate due date overview
A Hacker News discussion about note-taking tools inspired me to take a look into creating a Markdown table overview, fetched from files that take notes, and sorted by the parsed due date. The script is located here and more complex to understand.
# 2022-07-19 Notes
HN topic about taking notes: https://news.ycombinator.com/item?id=32152935
<!--
---
Tags: DevOps, Learn
Due: 2022-08-01
---
-->
Create issue index in a Markdown file, grouped by labels
A similar Hacker News question inspired me to write a script that parses all issues in a GitLab project by labels, and creates or updates a Markdown index file in the same repository. The issues are grouped by label.
First, the issues are fetched from the project, including all labels, and stored in the index dictionary.
p = gl.projects.get(PROJECT_ID)
labels = p.labels.list()
index={}
for i in p.issues.list():
for l in i.labels:
if l not in index:
index[l] = []
index[l].append("#{id} - {title}".format(id=i.id, title=i.title))
The second step is to create a Markdown formatted listing based on the collected index data, with the label name as key, holding a list of issue strings.
index_str = """# Issue Overview
_Grouped by issue labels._
"""
for l_name, i_list in index.items():
index_str += "\n## {label} \n\n".format(label=l_name)
for i in i_list:
index_str += "- {title}\n".format(title=i)
The last step is to create a new file in the repository, or update an existing one. This is a little tricky because the API expects you to define the action and will throw an error if you try to update a nonexistent file. The first condition checks whether the file path exists in the repository, and then defines the action attribute. The data dictionary gets built, with the final commits.create() method called.
# Dump index_str to FILE_NAME
# Create as new commit
# See https://docs.gitlab.com/ce/api/commits/#create-a-commit-with-multiple-files-and-actions
# for actions detail
# Check if file exists, and define commit action
f = p.files.get(file_path=FILE_NAME, ref=REF_NAME)
if not f:
action='create'
else:
action='update'
data = {
'branch': REF_NAME,
'commit_message': 'Generate new index, {d}'.format(d=date.today()),
'actions': [
{
'action': action,
'file_path': FILE_NAME,
'content': index_str
}
]
}
commit = p.commits.create(data)
Advanced DevSecOps workflows
- Container images to run API scripts
- CI/CD integration: Release and changelog generation
- CI/CD integration: Pipeline report summaries
Container images to run API scripts
Installing the Python interpreter and dependent libraries into the operating system may not always work, or it may be a barrier to using the API scripts. A container image that can be pulled from the GitLab registry is a good first step towards more DevSecOps automation and future CI/CD integrations, and provides a tested environment. The python-gitlab project provides container images which can be used for testing.
The cloned script repository can be mounted into the container, and the settings are configured using environment variables. Example with Docker CLI:
$ docker run -ti -v "`pwd`:/app" \
-e "GL_SERVER=http://gitlab.com" \
-e "GL_TOKEN=$GITLAB_TOKEN" \
-e "GL_GROUP_ID=16058698" \
registry.gitlab.com/python-gitlab/python-gitlab:slim-bullseye \
python /app/python_gitlab_manageable_objects.py
CI/CD integration: Release and changelog generation
Creating a Git tag and a release in GitLab often requires a changelog attached. This provides a summary into all Git commits, all merged merge requests, or something similar that is easier to consume for everyone interested in the changes in this new release. Automating the changelog generation in CI/CD pipelines is possible using the GitLab API. The simplest list uses the Git commit history shown in the create_simple_changelog_from_git_history.py script below:
project = gl.projects.get(PROJECT_ID)
commits = project.commits.list(ref_name='main', lazy=True, iterator=True)
print("# Changelog")
for commit in commits:
# Generate a markdown formatted list with URLs
print("- [{text}]({url}) ({name})".format(text=commit.title, url=commit.web_url, name=commit.author_name))
Executing the script on the o11y.love project will print a Markdown list with URLs.
$ python3 create_changelog_from_git_history.py
# Changelog
- [Merge branch 'topics-ebpf-opentelemetry' into 'main'](https://gitlab.com/everyonecancontribute/observability/o11y.love/-/commit/75df97e13e0f429803dc451aac7fee080a51f44c) (Michael Friedrich)
- [Move eBPF/OpenTelemetry into dedicated topics pages ](https://gitlab.com/everyonecancontribute/observability/o11y.love/-/commit/8fa4233630ff8c1d65aff589bd31c4c2f5df36cb) (Michael Friedrich)
- [Merge branch 'workshop-add-k8s-o11y-toc' into 'main'](https://gitlab.com/everyonecancontribute/observability/o11y.love/-/commit/8b7949b19af6aa6bf25f73ca1ffe8616a7dbaa00) (Michael Friedrich)
- [Add TOC for Kubesimplify Kubernetes Observability workshop ](https://gitlab.com/everyonecancontribute/observability/o11y.love/-/commit/63c8ad587f43e3926e6749a62c33ad0b6f229f47) (Michael Friedrich)
...
Exercise: The script is not production ready yet but should get you going to group by commits by Git tag/release, filter merge commits, attach the changelog file or content into the GitLab release details, etc.
CI/CD integration: Pipeline report summaries
When developing new API script in Python, a CI/CD integration with automated runs can be desired, too. My recommendation is to focus on writing and testing the script stand-alone on the command line first, and once it works reliably, adapt the code to run the script to perform actions in CI/CD, too. After writing a few scripts, and practicing a lot, you will have learned to write code that can be executed on the CLI, in containers and in CI/CD jobs.
A good preparation for CI/CD is to focus on environment variables to configure the script. The environment variables can be defined as CI/CD variables, and there is no extra work with additional configuration files, or command line parameters involved. This keeps the CI/CD configuration footprint small and reusable, too.
An example integration to automatically create security summaries as markdown comment in a merge request was described in the "Fantastic Infrastructure-as-Code security attacks and how to find them" blog post. This use case required research and testing before actually writing the full API script:
- Read the python-gitlab documentation to learn how merge request comments (notes) can be created.
- Create a test project and a test merge request for testing.
- Start writing code which instantiates the GitLab connection object, fetches the project object, and gets the merge request object from a pre-defined ID.
- Run
mr.notes.create({‘body’: ‘This is a test by dnsmichi’}) - Iterate on the body content and pre-fill a string with a markdown table.
- Fetch pre-defined CI/CD variables to get the
CI_MERGE_REQUEST_IDvalue which will be required to update as target. - Verify the API permissions and learn that the CI job token is not sufficient.
- Implement the full algorithm, integrated CI/CD testing and add documentation.
The script runs continuously after security scans have been completed with a report. Another use case can be using Pipeline schedules which provide synchronization capabilities, and the comments get posted to an issue summary.
Development tips
Code and abstraction libraries are helpful but sometimes it can be hard to see the problem why an attribute or object does not provide the expected behavior. It is helpful to take a step back, and look into different ways to fetch data from the REST API, for example using jq and curl. The GitLab CLI can also be used to query the API and get immediate results.
Developing scripts that interact with APIs can become a repetitive task, adding more needed attributes, and the need to learn about object relations, methods and how to store the retrieved data. Especially for larger datasets, it can be a good idea to use the JSON library to dump data structures into a file cache on disk, and provide a debug configuration option to read the data from that file, instead of firing the API requests again all the time. This also helps to mitigate potential rate limiting.
Adding timing points to the code can help measure the performance, and efficiency of the algorithm used. The following snippet measures the duration of requests to retrieve the merge request status. It is part of a script that was used to analyze a potential problem with the detailed_merge_status attribute in this issue.
mrs = project.mergerequests.list(state='opened', iterator=True, with_merge_status_recheck=True)
for mr in mrs:
start = timer()
#print(mr.attributes) #debug
# https://docs.gitlab.com/api/merge_requests/#list-merge-request-diffs
real_mr = project.mergerequests.get(mr.get_id())
print("- [ ] !{mr_id} - {mr_url}+ Status: {s}, Title: {t}".format(
mr_id=real_mr.attributes['iid'],
mr_url=real_mr.attributes['web_url'],
s=real_mr.attributes['detailed_merge_status'],
t=real_mr.attributes['title']))
end = timer()
duration = end - start
if duration > 1.0:
print("ALERT: > 1s ")
print("> Execution time took {s}s".format(s=(duration)))
More tips are discussed in the following sections:
Advanced custom configuration
When you are developing a script that requires advanced custom configuration, choose a format that fits best into existing infrastructure and development guidelines. Python provides libraries for parsing YAML, JSON, etc. The following example configuration file and script showcase a YAML configuration option. It is based on a script that automatically updates a list of issues/epics with a comment, reminding responsible team members for a recurring update for a cross-functional initiative at GitLab.
python_gitlab_custom_yaml_config.yml
tasks:
- name: "Backend"
url: "https://gitlab.com/group1/project2/-/issues/1"
- name: "Frontend"
url: "https://gitlab.com/group2/project4/-/issues/2"
python_gitlab_custom_script_config_yaml.py
import os
import yaml
CONFIG_FILE = os.environ.get('GL_CONFIG_FILE', "python_gitlab_custom_yaml_config.yml")
# Read config
with open(CONFIG_FILE, mode="rt", encoding="utf-8") as file:
config = yaml.safe_load(file)
#print(config) #debug
tasks = []
if "tasks" in config:
tasks = config['tasks']
# Process the tasks
for task in tasks:
print("Task name: '{n}' Issue URL to update: {id}".format(n=task['name'], id=task['url']))
# print(task) #debug
$ python3 python_gitlab_custom_script_config_yaml.py ─╯
Task name: 'Backend' Issue URL to update: https://gitlab.com/group1/project2/-/issues/1
Task name: 'Frontend' Issue URL to update: https://gitlab.com/group2/project4/-/issues/2
CI/CD code linting for different Python versions
All code examples in this blog post have been tested with Python 3.8, 3.9, 3.10 and 3.11, using parallel matrix builds in GitLab CI/CD and pyflakes for code linting. Automating the tests helps focus on development, and ensuring that the target platforms support the language features. Some Linux distributions do not provide Python 3.11 yet for example, and Python language features cannot be used or may need an alternative implementation.
include:
- template: Security/SAST.gitlab-ci.yml
- template: Dependency-Scanning.gitlab-ci.yml
- template: Secret-Detection.gitlab-ci.yml
stages:
- lint
- test
.python-req:
image: python:$VERSION
script:
- pip install -r requirements_dev.txt
parallel:
matrix:
- VERSION: ['3.8', '3.9', '3.10', '3.11'] # https://hub.docker.com/_/python
lint-python:
extends: .python-req
stage: lint
script:
- !reference [.python-req, script]
- pyflakes .
sast:
stage: test
Optimize code and performance
Lazy objects
When working with objects that do not immediately need all attributes loaded, you can specify the lazy=True attribute to not invoke an API call immediately. A follow-up method call will then invoke the required API calls.
# Lazy object, no API call
project = gl.projects.get(PROJECT_ID, lazy=True)
try:
print("Trying to access 'snippets_enabled' on a lazy loaded project object. This will throw an exception that we capture.")
print("Project settings: snippets_enabled={b}".format(b=project.snippets_enabled))
except Exception as e:
print("Accessing lazy loaded object failed: {e}".format(e=e))
project.snippets_enabled = True
project.save() # This creates an API call
print("\nLazy object was loaded after save() call.")
print("Project settings: snippets_enabled={b}".format(b=project.snippets_enabled))
Executing the python_gitlab_lazy_objects.py script shows that the lazy object did not fire an API call, thus throwing an exception when accessing the project setting snippets_enabled. To show that the object still can be managed, the code catches the exception to proceed with updating the setting locally, and calling project.save() to persist the change and call the API update.
$ python3 python_gitlab_lazy_objects.py ─╯
Trying to access 'snippets_enabled' on a lazy loaded project object. This will throw an exception that we capture.
Accessing lazy loaded object failed: 'Project' object has no attribute 'snippets_enabled'
If you tried to access object attributes returned from the server,
note that <class 'gitlab.v4.objects.projects.Project'> was created as
a `lazy` object and was not initialized with any data.
Lazy object was loaded after save() call.
Project settings: snippets_enabled=True
Object-oriented programming
For better code quality, it makes sense to follow object-oriented programming and create classes that store attributes, provide methods, and enable better unit testing. The storage analyzer tool was developed to create a summary of projects that consume lots storage, for example CI/CD job artifacts. By inspecting the Git history, you can learn from the different iterations to a first working version.
The following example is a trimmed version which shows how to initialize the class GitLabUseCase, add helper functions for logging and JSON pretty-printing, and print all project attributes.
#!/usr/bin/env python
import gitlab
import os
import sys
import json
# Print an error message with prefix, and exit immediately with an error code.
def error(text):
logger("ERROR", text)
sys.exit(1)
# Log a line with a given prefix (e.g. INFO)
def logger(prefix, text):
print("{prefix}: {text}".format(prefix=prefix, text=text))
# Return a pretty-printed JSON string with indent of 4 spaces
def render_json_output(data):
return json.dumps(data, indent=4, sort_keys=True)
# Class definition
class GitLabUseCase(object):
# Initializer to set all required parameters
def __init__(self, verbose, gl_server, gl_token, gl_project_id):
self.verbose = verbose
self.gl_server = gl_server
self.gl_token = gl_token
self.gl_project_id = gl_project_id
# Debug logger, controlled via verbose parameter
def log_debug(self, text):
if self.verbose:
print("DEBUG: {d}".format(d=text))
# Connect to the GitLab server and store the connection handle
def connect(self):
self.log_debug("Connecting to GitLab API at {s}".format(s=self.gl_server))
# Supports personal/project/group access token
# https://docs.gitlab.com/api/#personalprojectgroup-access-tokens
self.gl = gitlab.Gitlab(self.gl_server, private_token=self.gl_token)
# Use the stored connection handle to fetch a project object by id,
# and print its attribute with JSON pretty-print.
def print_project_attributes(self):
project = self.gl.projects.get(self.gl_project_id)
print(render_json_output(project.attributes))
## main
if __name__ == '__main__':
# Fetch configuration from environment variables.
# The second parameter specifies the default value when not provided.
gl_verbose = os.environ.get('GL_VERBOSE', False)
gl_server = os.environ.get('GL_SERVER', 'https://gitlab.com')
gl_token = os.environ.get('GL_TOKEN')
if not gl_token:
error("Please specifiy the GL_TOKEN env variable")
gl_project_id = os.environ.get('GL_PROJECT_ID', 42491852) # https://gitlab.com/gitlab-da/use-cases/gitlab-api/gitlab-api-python
# Instantiate new object and run methods
gl_use_case = GitLabUseCase(gl_verbose, gl_server, gl_token, gl_project_id)
gl_use_case.connect()
gl_use_case.print_project_attributes()
Running the script with the GL_PROJECT_ID environment variable pretty-prints the project attributes as JSON on the terminal.
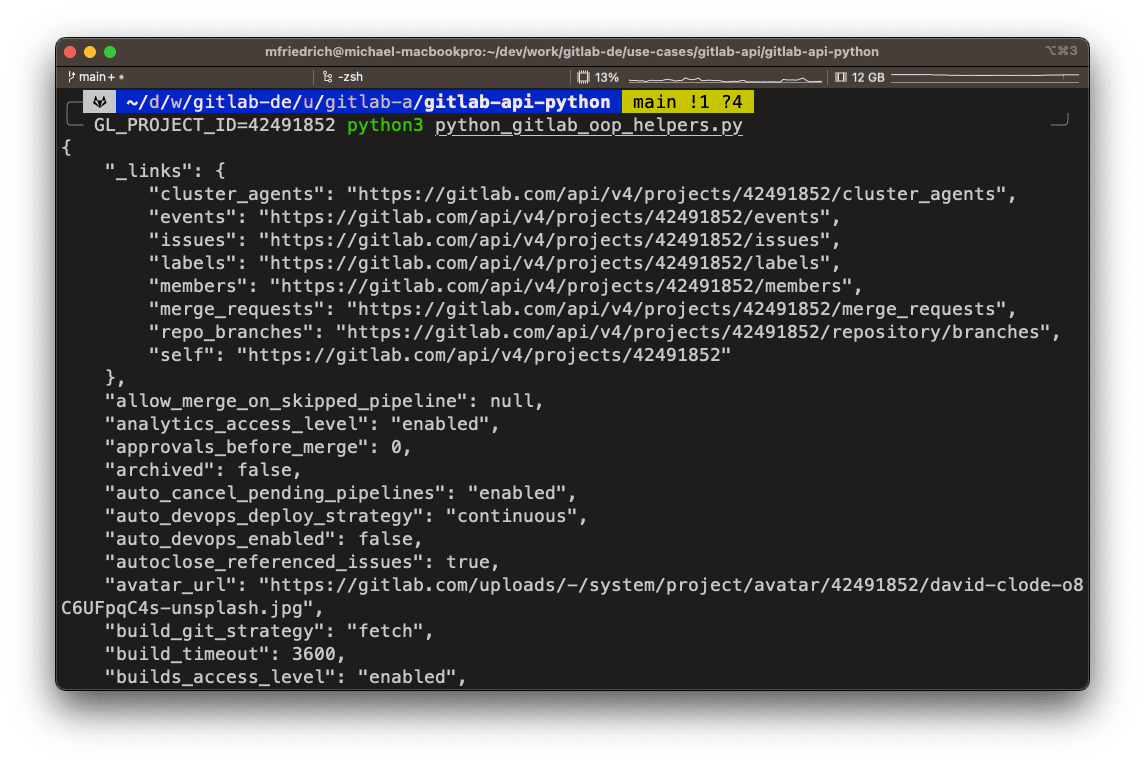
More use cases
Better performance with API requests can be achieved by looking into parallelization and threading in Python. Users have been testing the storage analyzer script, and provided feedback to optimize the performance for the single-threaded script by using tasks and Python threading, similar to this community project. I might follow up on this topic in a future blog post, there are many more great use cases to cover using python-gitlab.
There is so much more to learn, here are a few examples from the GitLab community forum that could not make it into this blog post:
- Fetch review app environment URL from Merge Request
- Project visibility, project features, permissions
- Download GitLab CI/CD job artifacts using Python
Conclusion
The python-gitlab library helps to abstract raw REST API calls, and to keep access to attributes, functions and objects short and relatively easy. There are many use cases that can be solved efficiently. Alternative programming language libraries for the GitLab REST API are available in the API clients section here.
The GitLab Community Forum is a great place to collaborate on use cases and questions about possible solutions or code snippets. We'd love to hear from you about your use cases and challenges using the python-gitlab library.
Shoutout to the python-gitlab maintainers and contributors, developing this fantastic API library for many years now! If this blog post and the python-gitlab library helped you get more efficient, please consider contributing to python-gitlab. When there is a GitLab API feature missing, look into contributing to GitLab, too. Thank you!
Cover image by David Clode on Unsplash
More to explore
View all blog posts


We want to hear from you
Enjoyed reading this blog post or have questions or feedback? Share your thoughts by creating a new topic in the GitLab community forum.
Share your feedback