
Gitaly, the service that is responsible for providing access to Git repositories in GitLab, needs to ensure that the repositories are maintained regularly. Regular maintenance ensures:
- fast access to these repostiories for users
- reduced resource usage for servers
However, repository maintenance is quite expensive by itself and especially so for large monorepos.
In a past blog post, we discussed how we revamped the foundations of repository maintenance so that we can iterate on the exact maintenance strategy more readily. This blog post will go through improved maintenance strategies for objects hosted in a Git repository, which was enabled by that groundwork.
- The object database
- The old way of packing objects
- All-into-one repacks
- Deletion of unreachable objects
- Reachability checks
- The new way of packing objects
- Cruft packs
- More efficient incremental repacks
- Geometric repacking
- Real-world results
The object database
Whenever a user makes changes in a Git repository, these changes come in the form of new objects written into the repository. Typically, any such object is written into the repository as a so-called "loose object," which is a separate file that contains the compressed contents of the object itself with a header that identifies the type of the object.
To demonstrate this, in the following example we use
git-hash-object(1) to write a new blob into the repository:
$ git init --bare repository.git
Initialized empty Git repository in /tmp/repository.git/
$ cd repository.git/
$ echo "contents" | git hash-object -w --stdin
12f00e90b6ef79117ce6e650416b8cf517099b78
$ tree objects
objects
├── 12
│ └── f00e90b6ef79117ce6e650416b8cf517099b78
├── info
└── pack
4 directories, 1 file
As you can see, the new object was written into the repository and stored as a separate file in the objects database.
Over time, many of these loose objects will accumulate in the repository. Larger repositories tend to have millions of objects, and storing all of them as separate files is going to be inefficient. To ensure that the repository can be served efficiently to our users and to keep the load on servers low, Git will regularly compress loose objects into packfiles. We can compress loose objects manually by using, for example, git-pack-objects(1):
$ git pack-objects --pack-loose-unreachable ./objects/pack/pack </dev/null
Enumerating objects: 1, done.
Counting objects: 100% (1/1), done.
Writing objects: 100% (1/1), done.
Total 1 (delta 0), reused 0 (delta 0), pack-reused 0
7ce39d49d7ddbbbbea66ac3d5134e6089210feef
$ tree objects
objects/
├── 12
│ └── f00e90b6ef79117ce6e650416b8cf517099b78
├── info
│ └── packs
└── pack
├── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.idx
└── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.pack
The loose object was compressed into a packfile (.pack) with a packfile index (.idx) that is used to efficiently access objects in that packfile.
However, the loose object still exists. To remove it, we can execute git-prune-packed(1) to delete all objects that have been packed already:
$ git prune-packed
$ tree objects/
objects/
├── info
│ └── packs
└── pack
├── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.idx
└── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.pack
For end users of Git, all of this happens automatically because Git calls git gc --auto regularly. This command uses heuristics to figure out what needs to be optimized and whether loose objects need to be compressed into packfiles. This command is unsuitable for the server side because:
- The command does not scale well enough in its current form. The Git project must be more conservative about changing defaults because they support a lot of different use cases. Because we know about the specific needs that we have at GitLab, we can adopt new features that allow for more efficient maintenance more readily.
- The command does not provide an easy way to observe what exactly it is doing, so we cannot provide meaningful metrics.
- The command does not allow us to fully control all its exact inner workings and so is not flexible enough.
Therefore, Gitaly uses its own maintenance strategy to maintain Git repositories, of which maintaining the object database is one part.
The old way of packing objects
Any maintenance strategy to pack objects must ensure the following three things to keep a repository efficient and effective with disk space:
- Loose objects must be compressed into packfiles.
- Packfiles must be merged into larger packfiles.
- Objects that are not reachable anymore must be deleted eventually.
Previous to GitLab 16.0, Gitaly used the following three heuristics to ensure that those three things happened:
- If the number of packfiles in the repository exceeds a certain threshold, Gitaly rewrote all packfiles into a single new packfile. Any objects that were unreachable were put into loose files so that they could be deleted after a certain grace period.
- If the number of loose objects exceeded a certain threshold, Gitaly compressed all reachable loose objects into a new packfile.
- If the number of loose objects that are older than the grace period for object deletion exceeded a certain threshold, Gitaly deleted those objects.
While these heuristics satisfy all three requirements, they have several downsides, especially in large monorepos that contain gigabytes of data.
All-into-one repacks
First and foremost, the first heuristic requires us to do all-into-one repacks where all packfiles are regularly compressed into a single packfile. In Git repositories with high activity levels, we usually create lots of packfiles during normal operations. But because we need to limit the maximum number of packfiles in a repository, we need to regularly do these complete rewrites of all objects.
Unfortunately, doing such an all-into-one repack can be prohibitively expensive in large monorepos. The repacks may allocate large amounts of memory and typically keep multiple CPU cores busy during the repack, which can require hours of time to complete.
So, ideally, we want to avoid these all-into-one repacks to the best extent possible.
Deletion of unreachable objects
To avoid certain race conditions, Gitaly and Git enforce a grace period before an unreachable object is eligible for deletion. This grace period is tracked using the access time of such an unreachable object: If the last access time of the object is earlier than the grace period, the unreachable object can be deleted.
To track the access time of a single object, the object must exist as a loose object. This means that all objects that are pending deletion will be evictedfrom any packfile they were previously part of and become loose objects.
Because the grace period we have in place for Gitaly is 14 days, large monorepos tend to grow a large number of such loose object that are pending deletion. This has two effects:
- The number of loose objects overall grows, which makes object lookup less efficient.
- Loose objects are stored a lot less efficiently than packed objects, which means that the disk space required for the objects that are pending deletion is signficantly higher than if those objects were stored in their packed form.
Ideally, we would be able to store unreachable objects in packed format while still being able to store their last access times separately.
Reachability checks
Compressing loose objects into a new packfile is done by using an incremental repack. Git will compute the reachability of all objects in the repository and then pack all loose objects that are reachable into a new packfile.
To determine reachability of an object, we have to perform a complete graph walk. Starting at all objects that are directly referenced, we walk down any links that those objects have to any other objects. Once we reach the root of the object graph, we have then split all objects into two sets, which are the reachable and unreachable objects.
This operation can be quite expensive and the larger the repository and the more objects it contains, the more expensive this computation gets. As mentioned above though, objects which are about to be deleted need to be stored as loose objects such that we can track their last access time. So if our incremental repack compressed all loose objects into a packfile regardless of their reachability, then this would impact our ability to track the grace period per object.
The ideal solution here would avoid doing reachability checks altogether while still being able to track the grace period of unreachable objects which are pending deletion individually.
The new way of packing objects
Over the past two years, the Git project has shipped multiple mechanisms that allow us to address all of these painpoints we had with our old strategy. These new mechanisms come in two different forms:
- Geometric repacking allows us to merge multiple packfiles without having to rewrite all packfiles into one. This feature was introduced in Git v2.32.0.
- Cruft packs allow us to store objects that are pending deletion in compressed format in a packfile. This feature was introduced in Git v2.37.0.
The Gitaly team has reworked the object database maintenance strategy to make use of these new features.
Cruft packs
Previous to Git v2.37.0, pruning objects with a grace period required Git to first unpack packed objects into loose objects. We did this so that we can track the per-object access times for unreachable objects that are pending deletion as explained above. This is inefficient though as it potentially requires us to keep a lot of unreachable objects in loose format until they can be deleted after the grace period.
With Git v2.37.0, git-repack(1) learned to write cruft packs. While a cruft pack looks just like a normal pack, it also has an accompanying
.mtimes file:
$ tree objects/
objects/
├── info
│ └── packs
└── pack
├── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.idx
├── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.mtimes
└── pack-7ce39d49d7ddbbbbea66ac3d5134e6089210feef.pack
This file contains per-object timestamps that record when the object was last accessed. With this, we can continue to track per-object grace periods while storing the objects in a more efficient way compared to loose objects.
In Gitaly, we started to make use of cruft packs in GitLab 15.10 and made the feature generally available in GitLab 15.11. Cruft packs allow us to store objects that are pending deletion more efficiently and with less impact on the overall performance of the repository.
More efficient incremental repacks
Cruft packs also let us fix the issue that we had to do reachability checks when doing incremental repacks.
Previously, we had to always ensure reachability when packing loose objects so that we don't pack objects that are pending deletion. But now that any such object would be stored as part of a cruft pack and not as a loose pack anymore, we can instead compress all loose files into a packfile. This change was introduced into Gitaly with GitLab 16.0.
In an artificial benchmark with the Linux repository, compressing all loose objects into a packfile led to more than a 90-fold speedup, dropping from almost 13 seconds to 174 milliseconds.
Geometric repacking
Last but not least, we still have the issue that we need to perform regular all-into-one repacks when we have too many packfiles in the repository.
Git v2.32.0 introduced a new "geometric" repacking strategy for the git-repack(1) command that will merge multiple packfiles into a single, larger packfile, that we can use to solve this issue.
This new "geometric" strategy tries to ensure that existing packfiles in the repository form a geometric sequence where each successive packfile contains at least n times as many objects as the preceding packfile. If the sequence isn't maintained, Git will determine a slice of packfiles that it must repack to maintain the sequence again. With this process, we can limit the number of packfiles that exist in the repository without having to repack all objects into a single packfile regularly.
The following figures demonstrate geometric repacking with a factor of two.
- We notice that the two smallest packfiles do not form a geometric sequence as they both contain two objects each.

- We identify the smallest slice of packfiles that need to be repacked in order to restore the geometric sequence. Merging the smallest two packfiles would lead to a packfile with four objects. This would not be sufficient to restore the geometric sequence as the next-biggest packfile contains four objects, as well.
Instead, we need to merge the smallest three packfiles into a new packfile that contains eight objects in total. As 8 × 2 ≤ 16 the geometric sequence is restored.

- We merge those packfiles into a new packfile.

Originally, we introduced this new feature into Gitaly in GitLab 15.11.
Unfortunately, we had to quickly revert this new mode. It turned out that the geometric strategy was not ready to handle Git repositories that had an alternate object database connected to them. Because we make use of this feature to deduplicate objects across forks, the new repacking strategy led to problems.
As active contributors to the Git project, we set out to fix these limitations in git-repack(1) itself. This led to an upstream patch series that fixed a bunch of limitations around alternate object directories when doing geometric repacks in Git that was then released with Git v2.41.
With these fixes upstream, we were then able to reintroduce the change and globally enable our new geometric repacking strategy with GitLab 16.0.
Real-world results
All of this is kind of dry and deeply technical. What about the real-world results?
The following graphs show the global time we spent repacking objects across all projects hosted on GitLab.com.
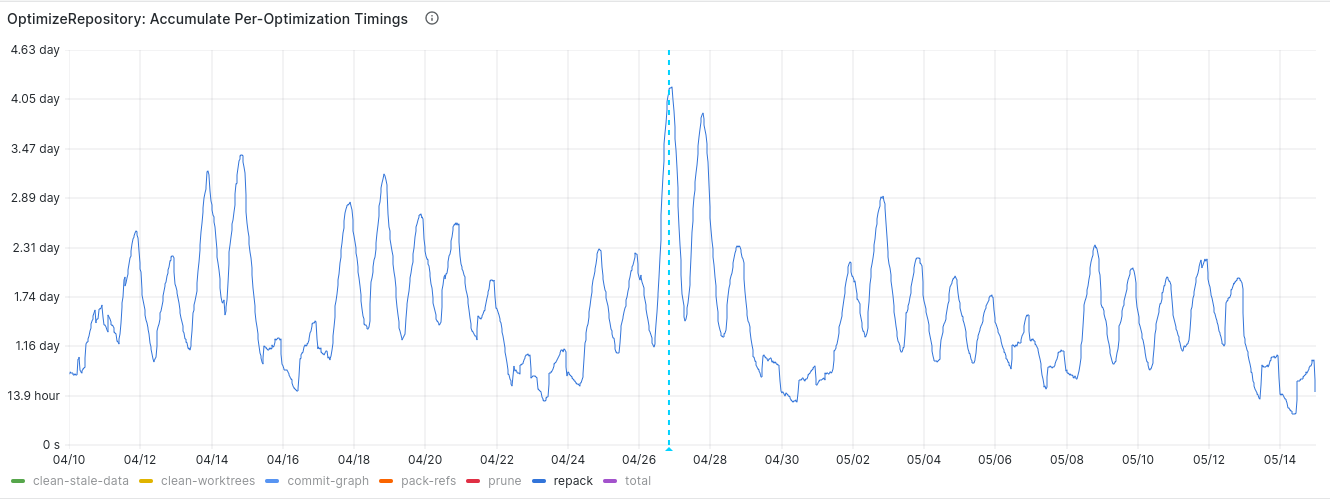
The initial rollout was on April 26 and progressed until April 28. As you can see, there was first a significant increase in repacking time. But after the initial dust settles, we can see that globally the time we spent repacking repositories roughly decreased by almost 20%.
In the two weeks before we enabled the feature, during weekdays and at peak times we were usually spending around 2.6 days per 12 hours repacking. In the two weeks after the feature was enabled, we spent around 2.12 days per 12 hours repacking objects.
This is a success by itself already, but the more important question is how it would impact large monorepos, which are significantly harder to keep well-maintained due to their sheer size. Fortunately, the effect of the new housekeeping strategy was a lot more significant here. The following graph shows the time we spent performing housekeeping tasks in our own gitlab-org and gitlab-com groups, which host some of the most active repositories that have caused issues in the past:
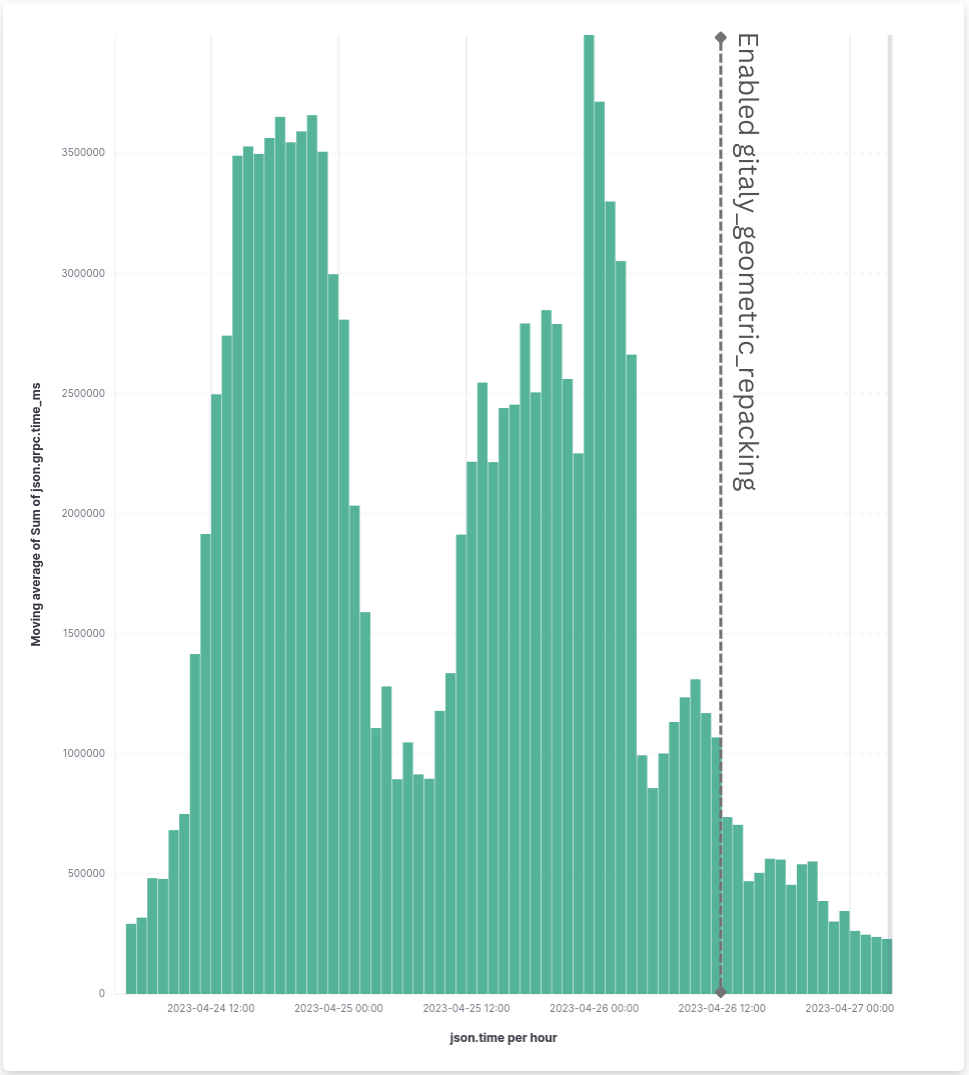
In summary, we have observed the following improvements:
| Before | After | Change | |
|---|---|---|---|
| Global accumulated repacking time | ~5.2 hours/hour | ~4.2 hours/hour | -20% |
| Large repositories of gitlab-org and gitlab-com groups | ~0.7-1.0 hours/hour | 0.12-0.15 hours/hour | -80% |
We have heard of other customers that saw similar improvements in highly active large monorepositories.
Manually enable geometric repacking
While the new geometric repacking strategy has been default-enabled starting with GitLab 16.0, it was introduced with GitLab 15.11. If you want to use the
new geometric repacking mode, you can opt in by setting the
gitaly_geometric_repacking feature flag. You can do so via the gitlab-rails
console:
Feature.enable(:gitaly_geometric_repacking)


