
The Git project recently released Git 2.44.0. In this blog post, we will highlight the contributions made by GitLab's Git team, as well as those from the wider Git community.
Fast scripted rebases via git-replay
The git-rebase command can be used to reapply a set of commits onto a different base commit. This can be quite useful when you have a feature branch where the main branch it was originally created from has advanced since creating the feature branch.
In this case, git-rebase can be used to reapply all commits of the feature branch onto the new commits of the main branch.
Suppose you have the following commit history with the main development branch main and your feature branch feature:
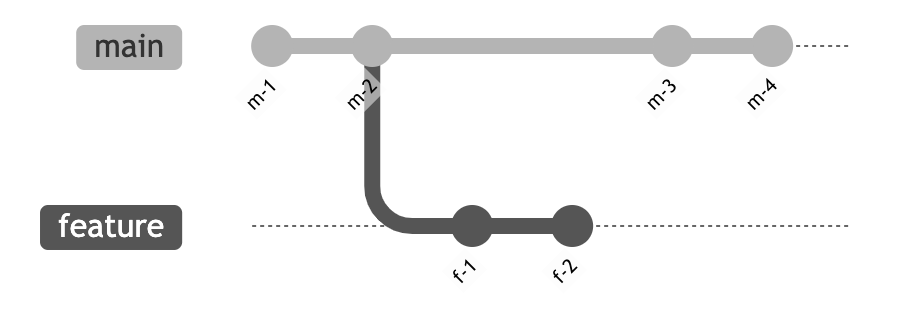
You have originally created your feature branch from m-2, but since then the main branch has gained two additional commits. Now git-rebase can be used to reapply your commits f-1 and f-2 on top of the newest commit m-4:
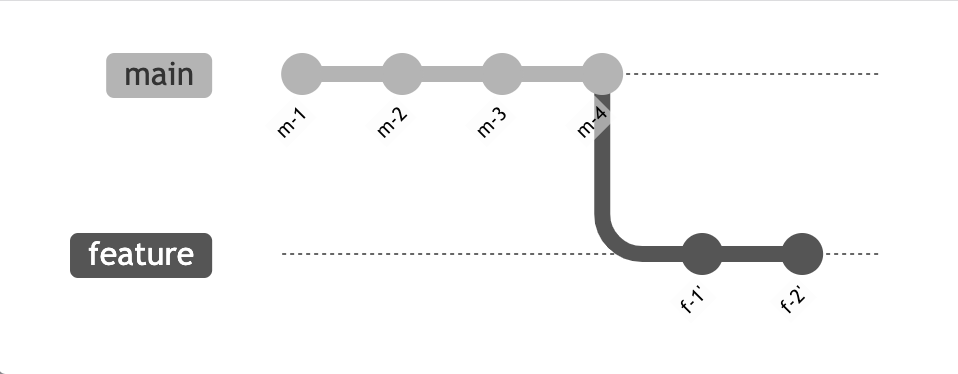
You can see this functionality in GitLab when you create a merge request. When you want to reapply the commits of your merge request onto new commits in the target branch, all you have to do is to create a comment that contains the /rebase command. The magic then happens behind the scenes.
There is one problem though: git-rebase only works on repositories that have a worktree (a directory where a branch, tag or commit has been checked out). The repositories we host at GitLab are “bare” repositories, which don’t have a worktree. This means that the files and directories tracked by your commits are only tracked as Git objects in the .git directory of the repository. This is mostly done to save precious disk space and speed up operations.
In the past, we used libgit2 to implement rebases. But for various reasons, we decided to remove this dependency in favor of only using Git commands to access Git repositories. But this created a problem for
us because we could neither use libgit2 nor git-rebase to perform rebases. While we could create an ad-hoc worktree to use git-rebase, this would have been prohibitively expensive in large monorepos.
Luckily, Elijah Newren has upstreamed a new merge algorithm called merge-ort in Git 2.33. Despite being significantly faster than the old recursive merge strategy in almost all cases, it also has the added benefit that it can perform merges in-memory. In practice, this also allows us to perform such rebases in-memory.
Enter git-replay, which is a new command that does essentially the same thing as git-rebase but in-memory, thus not requiring a worktree anymore. This is an
important building block to allow us to develop faster rebasing of merge requests in the future.
You may ask: Why a new command instead of updating git-rebase? The problem here was that git-rebase is essentially a user-focused command (also called a
"porcelain" command in Git). Thus it performs several actions that are not required by a script at all, like, for example, executing hooks or checking out files into the worktree. The new git-replay command is a script-focused
command (also called a "plumbing" command in Git) and has a different set of advantages and drawbacks. Furthermore, besides doing rebases, we plan to use it to do cherry-picks and reverts in the future, too.
This topic was a joint effort by Elijah Newren and Christian Couder.
Commit-graph object existence checks
You may know that each commit can have an arbitrary number of parents:
- The first commit in your repository has no parents. This is the "root" commit.
- Normal commits have a single parent.
- Merge commits have at least two, but sometimes even more than two parents.
This parent relationship is part of what forms the basis of Git's object model and establishes the object graph. If you want to traverse this object graph, Git must look up an entry point commit and from there walk the parent chain of commits.
To fully traverse history from the newest to the oldest commit, you must look up and parse all commit objects in between. Because repositories can consist of hundreds of thousands or even millions of such commits, this can be quite an expensive operation. But users of such repositories still want to be able to, for example, search for a specific commit that changes a specific file without waiting several minutes for the search to complete.
The Git project introduced a commit-graph data structure a long time ago that essentially caches a lot of the parsed information in a more accessible data structure. This commit-graph encodes the parent-child relation and some additional information, like, for example, a bloom filter of changed files.
This commit-graph is usually updated automatically during repository housekeeping. Because housekeeping only runs every so often, the commit-graph can be missing entries for recently added commits. This is perfectly fine and expected to happen, and Git knows to instead look up and parse the commit object in such a case.
Now, the reverse case also theoretically exists: The commit-graph contains cached information of an object that does not exist anymore because it has been deleted without regenerating the commit-graph. The consequence would be that lookups of this commit succeed even though they really shouldn't. To avoid this, in Git 2.43.0, we upstreamed a change into Git that detects commits that exist in the commit-graph but no longer in the object database.
This change requires us to do an existence check for every commit that we parse via the commit-graph. Naturally, this change leads to a performance regression, which was measured to be about 30% in the worst case. This was
deemed acceptable though, because it is better to return the correct result slowly than to return the wrong result quickly. Furthermore, the commit-graph still results in a significant performance improvement compared to not using the commit-graph at all. To give users an escape hatch in case they do not want this performance regression, we also introduced a GIT_COMMIT_GRAPH_PARANOIA environment variable that can be used to disable this check.
After this change was merged and released though, we heard of cases where the impact was even worse than 30%: counting the number of commits via git rev-list --count in the Linux repository regressed by about 100%. After some
discussion upstream, we changed the default so that we no longer verify commit existence for the commit-graph to speed up such queries again. Because repository housekeeping should ensure that commit-graphs are consistent, this change should stop us from needlessly pessimizing this uncommon case.
This change was implemented by Patrick Steinhardt.
Making Git ready for a new ref backend
A common theme among our customers is that large monorepos with many refs create significant performance problems with many workloads. The range of problems here are manyfold, but the more refs a repository has, the more pronounced the problems become.
Many of the issues are inherent limitations of the way Git stores refs. The so-called files ref backend uses a combination of two mechanisms:
- "Loose refs" are simple files that contain the object ID they point to.
- "Packed refs" are a single file that contains a collection of refs.
Whenever you update or create a ref, Git creates them as a loose ref. Every once in a while, repository housekeeping then compresses all loose refs into the packed-refs file and deletes the corresponding loose refs. A typical repo looks as follows:
$ git init --ref-format=files repo
Initialized empty Git repository in /tmp/repo/.git/
$ cd repo/
$ git commit --allow-empty --message "initial commit"
$ tree .git/
.git/
├── config
├── HEAD
├── index
└── refs
├── heads
│ └── main
└── tags
$ cat .git/HEAD
ref: refs/heads/main
$ cat .git/refs/heads/main
bf1814060ed3a88bd457ac4dca055d000ffe4482
$ git pack-refs --all
$ cat .git/packed-refs
# pack-refs with: peeled fully-peeled sorted
bf1814060ed3a88bd457ac4dca055d000ffe4482 refs/heads/main
While this model has served the Git project quite well, relying on a filesystem like this has several limitations:
- Deleting a single ref requires you to rewrite the
packed-refsfile, which can be gigabytes in size. - It is impossible to do atomic reads because you cannot atomically scan multiple files at once when a concurrent writer may modify some refs.
- It is impossible to do atomic writes because creating or updating several refs requires you to write to several files.
- Housekeeping via
git-pack-refsdoes not scale well because of its all-into-one repacking nature. - The storage format of both loose and packed refs is inefficient and wastes disk space.
- Filesystem-specific behavior can be weird and may restrict which refs can be created. For example, Case-insensitivity on filesystems like FAT32 can cause issues, when trying to create two refs with the same name that only differ in their case.
Several years ago, Shawn Pearce had proposed the "reftable" format as an alternative new format to store refs in a repository. This new format was supposed to help with most or all of the above issues and is essentially a binary format specifically catered towards storing references in Git.
This new "reftable" format has already been implemented by JGit and is used extensively by the Gerrit project. And, in 2021, Han-Wen Nienhuys upstreamed a library to read and write reftables into the Git project. What is still missing though is the backend that ties together the reftable library and Git, and unfortunately progress has stalled here. As we experience much of the pain that the reftable format is supposed to address, we decided to take over the work from Han-Wen and continue the upstreaming process.
Before we can upstream the reftable backend itself though, we first had to prepare several parts of Git for such a new backend. While the Git project already has a concept of different ref backends, the boundaries were very blurry because until now there only exists a single "files" backend.
The biggest contribution by GitLab in this release was thus a joint effort to prepare all the parts of Git for the new backend that were crossing boundaries:
- Some commands used to read or write refs directly via the filesystem without going through the ref backend.
- The ref databases of worktrees created via
git-worktreewere initialized ad-hoc instead of going through the ref backend. - Cloning a repository created the ref database with the wrong object format when using SHA256. This did not matter with the "files" backend because the format was not stored anywhere by the ref backend itself. But because the reftable backend encodes the format into its binary format, this was a problem.
- Many tests read or write refs via the filesystem directly.
- We invested quite some time already into bug fixing and performance optimizations for the reftable library itself.
- We introduced a new
refStorageextension that tells Git in which format the repository stores its refs. This can be changed when creating a new repository by specifying--ref-formatflag ingit-initorgit-clone. For now, only the “files” format is supported.
The overarching goal was to get the work-in-progress reftable backend into a state where it passes the complete test suite. And even though the reftable backend is not yet part of Git 2.44.0, I am happy to report that we have succeeded in this goal: Overall, we have contributed more than 150 patches to realize it. Given the current state, we expect that the new reftable backend will become available with Git v2.45.0.
We will not cover the new reftable format in this post because it is out of scope, but stay tuned for more details soon!
This project was a joint effort by John Cai, Justin Tobler, Karthik Nayak, Stan Hu, Toon Claes, and Patrick Steinhardt, who has led the effort. Credit also goes to Shawn Pearce as original inventor of the format and Han-Wen Nienhuys as the author of the reftable library.
Support for GitLab CI
As all the preparations for the new reftable backend demonstrate, we have significantly increased our investments into the long-term vision and health of
the Git project. And because a very important part of our product depends on the Git project to remain healthy, we want to continue investing into the Git project like this.
For us, this means that it was high time to improve our own workflows in the context of the Git project. Naturally, we were already using GitLab CI as part of the process instead of the GitHub Workflows support that existed in
the Git project. But we were using a .gitlab-ci.yml definition that was not part of the upstream repository and instead maintained outside the Git project.
While this worked reasonably well, there were two significant downsides:
- Test coverage was significantly lower than that of the GitHub Workflows definition. Notably, we did not test on macOS, had no static analysis, and didn't test with non-default settings. This often led to failures in the GitHub Workflows pipeline that we could have detected earlier if we had better CI integration.
- Other potential contributors to Git who may already be using GitLab on a daily basis didn't have easy access to a GitLab CI pipeline.
Therefore, we decided to upstream a new GitLab CI definition that integrates with the preexisting CI infrastructure that the Git project already had. Because we reuse a lot of pre-existing infrastructure, this ensures that both GitLab CI and GitHub Workflows run tests mostly in the same way.
Another benefit of GitLab CI support is that, for the first time, we now also exercise an architecture other than x86_64 or i686: the macOS runners we provide at GitLab.com use an Apple M1, which is based on the arm64 architecture.
This change was contributed by Patrick Steinhardt.
More to come
This blog post gives just a glimpse into what has happened in the Git project, which lies at the heart of source code management at GitLab. Stay tuned for more insights into future contributions and the reftable backend in particular!


