
Update Jul 19, 2018: The latest info can be found in the GCP migration update blog post.
Improving the performance and reliability of GitLab.com has been a top priority for us. On this front we've made some incremental gains while we've been planning for a large change with the potential to net significant results: moving from Azure to Google Cloud Platform (GCP).
We believe Kubernetes is the future. It's a technology that makes reliability at massive scale possible. This is why earlier this year we shipped native integration with Google Kubernetes Engine (GKE) to give GitLab users a simple way to use Kubernetes. Similarly, we've chosen GCP as our cloud provider because of our desire to run GitLab on Kubernetes. Google invented Kubernetes, and GKE has the most robust and mature Kubernetes support. Migrating to GCP is the next step in our plan to make GitLab.com ready for your mission-critical workloads.
Once the migration has taken place, we’ll continue to focus on bumping up the stability and scalability of GitLab.com, by moving our worker fleet across to Kubernetes using GKE. This move will leverage our Cloud Native charts, which with GitLab 11.0 are now in beta.
How we’re preparing for the migration
Geo
One GitLab feature we are utilizing for the GCP migration is our Geo product. Geo allows for full, read-only mirrors of GitLab instances. Besides browsing the GitLab UI, Geo instances can be used for cloning and fetching projects, allowing geographically distributed teams to collaborate more efficiently.
Not only does that allow for disaster recovery in case of an unplanned outage, Geo can also be used for a planned failover to migrate GitLab instances.
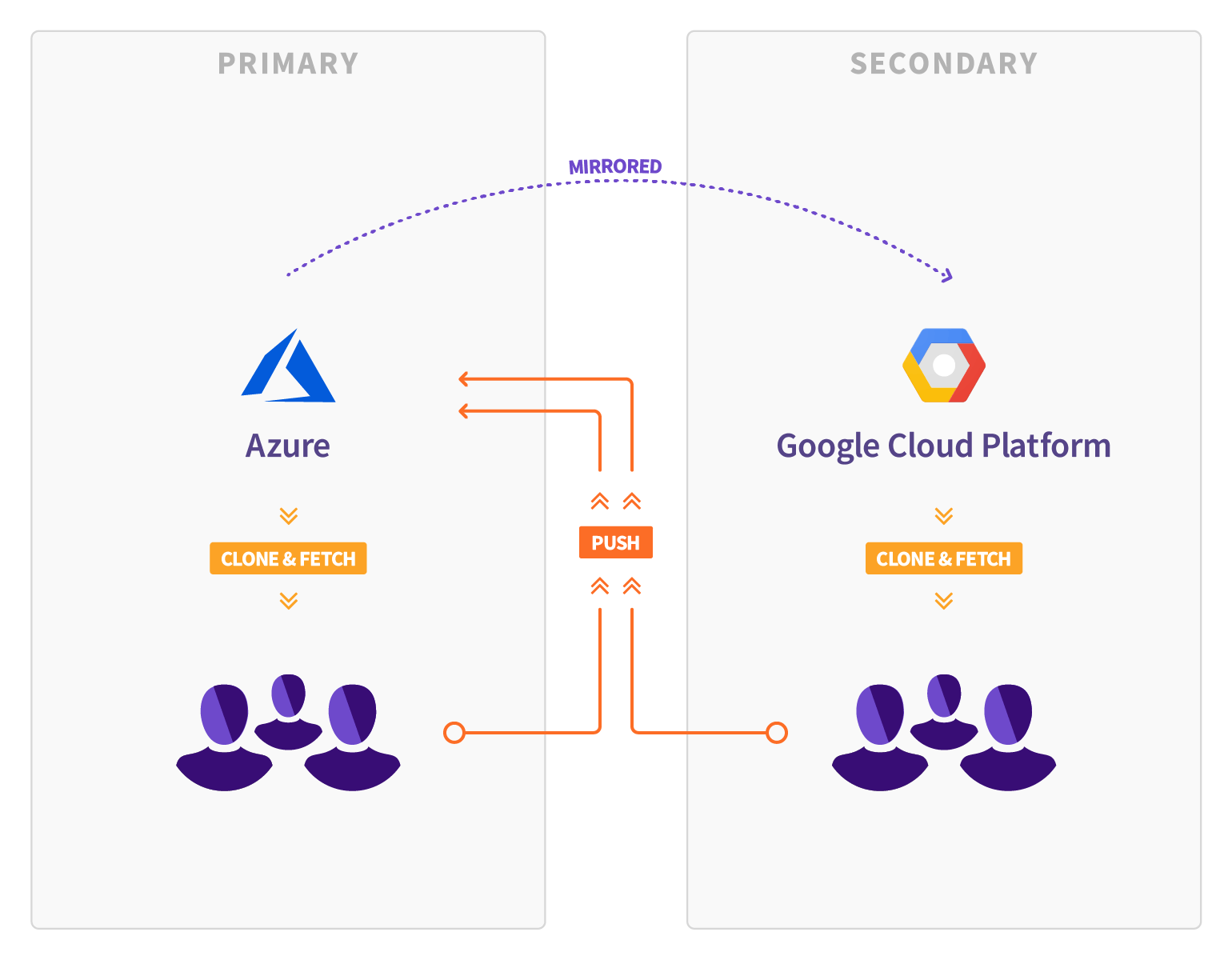
Following our mantra of dogfooding everything of our product, we are using Geo to move GitLab.com from Microsoft Azure to Google Cloud Platform. Geo is working well and scales because it's been used by many customers reliably since going GA. We believe Geo will perform well during the migration and plan this event as another proof point for its value.
Read more about Disaster Recovery with Geo in our Documentation.
The Geo transfer
For the past few months, we have maintained a Geo secondary site of GitLab.com, called gprd.gitlab.com, running on Google Cloud Platform. This secondary keeps an up-to-date synchronized copy of about 200TB of Git data and 2TB of relational data in PostgreSQL. Originally we also replicated Git LFS, File Uploads and other files, but this has since been migrated to Google Cloud Storage object storage, in a parallel effort.
For logistical reasons, we selected GCP's us-east1 site in the US state of South Carolina. Our current Azure datacenter is in US East 2, located in Virginia. This is a round-trip distance of 800km, or 3 light-milliseconds. In reality, this translates into a 30ms ping time between the two sites.
Because of the huge amount of data we need to synchronize between Azure and GCP, we were initially concerned about this additional latency and the risk it might have on our Geo transfer. However, after our initial testing, we realized that network latency and bandwidth were not bottlenecks in the transfer.
Object storage
In parallel to the Geo transfer, we are also migrating all file artifacts, including CI Artifacts, Traces (CI log files), file attachments, LFS objects and other file uploads to Google Cloud Storage (GCS), Google's managed object storage implementation. This has involved moving about 200TB of data off our Azure-based file servers into GCS.
Until recently, GitLab.com stored these files on NFS servers, with NFS volumes mounted onto each web and API worker in the fleet. NFS is a single-point-of-failure and can be difficult to scale. Switching to GCS allows us to leverage its built-in redundancy and multi-region capabilities. This in turn will help to improve our own availability and remove single-points-of-failure from our stack. The object storage effort is part of our longer-term strategy of lifting GitLab.com infrastructure off NFS. The Gitaly project, a Git RPC service for GitLab, is part of the same initiative. This effort to migrate GitLab.com off NFS is also a prerequisite for our plans to move GitLab.com over to Kubernetes.
How we're working to ensure a smooth failover
Once or twice a week, several teams, including Geo, Production, and Quality, get together to jump onto a video call and conduct a rehearsal of the failover in our staging environment.
Like the production event, the rehearsal takes place from Azure across to GCP. We timebox this event, and carefully monitor how long each phase takes, looking to cut time off wherever possible. The failover currently takes two hours, including quality assurance of the failover environment.
This involves four steps:
- A preflight checklist,
- The main failover procedure,
- The test plan to verify that everything is working, and
- The failback procedure, used to undo the changes so that the staging environment is ready for the next failover rehearsal.
Since these documents are stored as issue templates on GitLab, we can use them to create issues on each successive failover attempt.
As we run through each rehearsal, new bugs, edge-cases and issues are discovered. We track these issues in the GitLab Migration tracker. Any changes to the failover procedure are then made as merge requests into the issue templates.
This process allows us to iterate rapidly on the failover procedure, improving the failover documentation and helping the team build confidence in the procedure.
When will the migration take place?
Our absolute top priority for the failover is to ensure that we protect the integrity of our users' data. We will only conduct the failover once we are completely satisfied that all serious issues have been ironed out, that there is no risk of data loss, and that our new environment on Google Cloud Platform is ready for production workloads.
The failover is currently scheduled for Saturday, July 28, 2018. We will follow this post up shortly with further information on the event and will provide plenty of advance notice.
Read the most recent update on GitLabs journey from Azure to GCP here!


