
Last June, we had to face the facts: Our SaaS infrastructure for GitLab.com was not ready for mission-critical workloads, error rates were just too high, and availability was too low. To address these challenges, we decided to migrate from Azure to Google Cloud Platform (GCP) and document the journey publicly, end to end. A lot has happened since we first talked about moving to GCP, and we’re excited to share the results.
At Google Cloud Next '19, GitLab Staff Engineer Andrew Newdigate presented our migration experience and the steps we took to make it happen. Migrations seldom go as planned but we hope that others can learn from the process. Check out the video to learn more about our journey from Azure to GCP, and find some of our key takeaways below.
There were several reasons why we decided on the Google Cloud Platform. One top priority was that we wanted GitLab.com to be suitable for mission-critical workloads, and GCP offered the performance and consistency we needed. A second reason is that we believe Kubernetes is the future, especially with so much development geared toward cloud native. Another priority was price. For all of these reasons and more, Google was the clear choice as a partner going forward.
Our company values are important to us and we apply them to all aspects of our work and our migration from Azure to GCP is no exception.
Three core values guided this project:
Efficiency
At GitLab, we love boring solutions. The goal of the project was really simple: Move GitLab.com to GCP. We wanted to find the least complex and most straightforward solution to achieve this goal.
Iteration
We focus on shipping the minimum viable change and work in steps. When we practice iteration, we get feedback faster, we’re able to course-correct, and we reduce cycle times.
Transparency
We work publicly by default, which is why we made this project accessible to everyone and documented our progress along the way.
How we did it
Looking for the simplest solution, we considered whether we could just stop the whole site: Copy all the data from Azure to GCP, switch the DNS over to point to GCP, and then start everything up again. The problem was that we had too much data to do this within a reasonable time frame. Once we shut down the site, we'd need to copy all the data between two cloud providers, and once the copy was complete, we'd need to verify all the data (about half a petabyte) and make sure it was correct. This plan meant that GitLab.com could be down for several days, and considering that thousands and thousands of people rely on GitLab on a daily basis, this wouldn’t work.
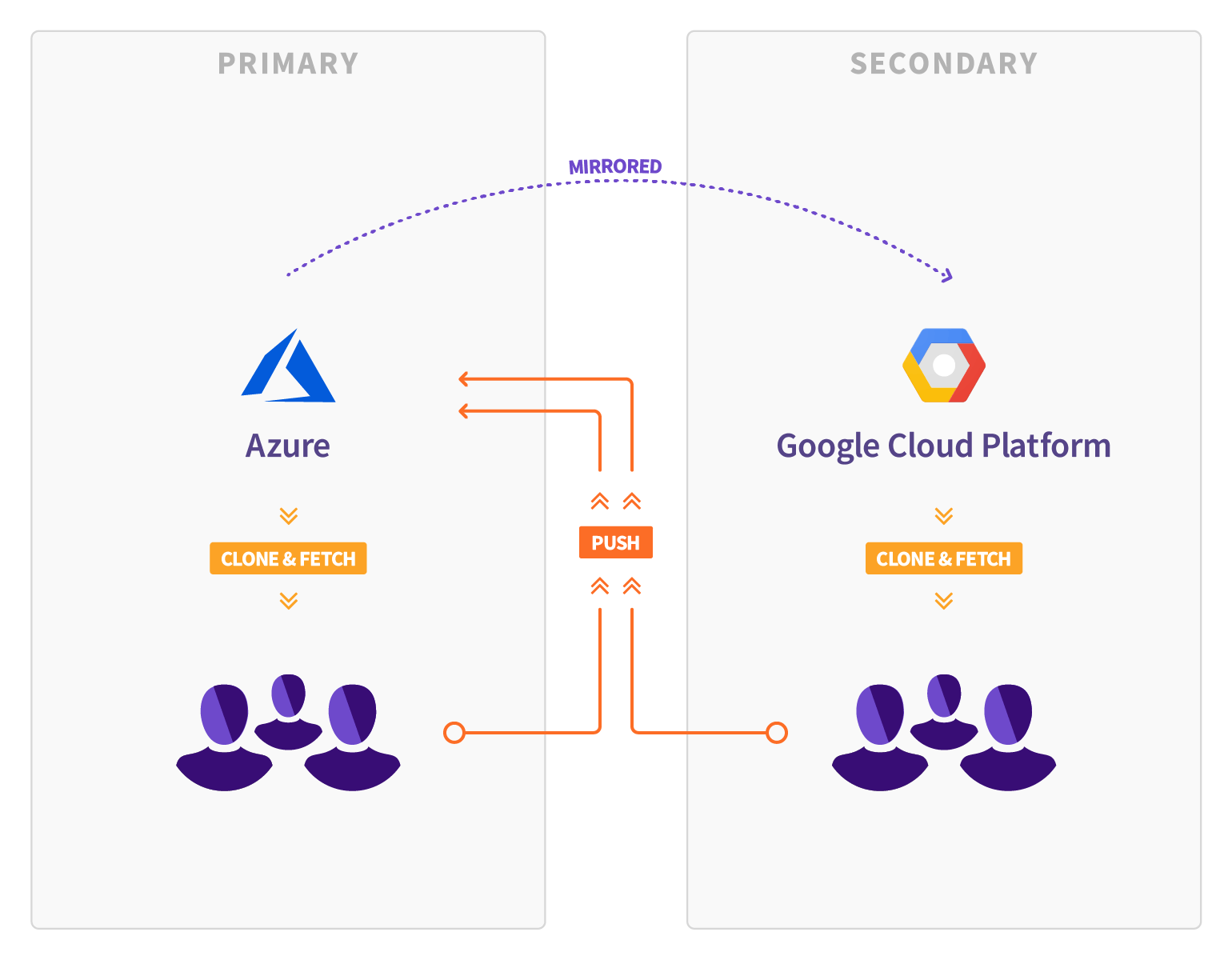
We went back to the drawing board. We were working on another feature called Geo which allows for full, read-only mirrors of GitLab instances. Besides browsing the GitLab UI, Geo instances can be used for cloning and fetching projects as well as for a planned failover to migrate GitLab instances.
We hoped that by taking advantage of the replication capabilities we were building for Geo, we could migrate the entire GitLab.com site to a secondary instance in GCP. The process might have taken weeks or months, but thankfully the site would be available throughout the synchronization process. Once all the data was synchronized to GCP, we could verify it and make sure it was correct. Finally, we could just promote the GCP environment and make it our new primary.
This new plan had many advantages over the first one. Obviously, GitLab.com would be up during the synchronization and we would only have a short period of downtime, maybe an hour or two, rather than weeks. We could do full QA, load testing, and verify all data before the failover.
"If it could work for us on GitLab.com, it would pretty much work for any other customer who wanted to use Geo. We could be confident in that." - Andrew Newdigate, Infrastructure Architect at GitLab

We were also working on another major project to install and run GitLab on Kubernetes. Much like Omnibus is a package installer for installing GitLab outside a Kubernetes environment, GitLab’s helm charts install GitLab inside a Kubernetes environment. The plan evolved to use helm charts to install GitLab in GCP while still using Geo for replication.
It became apparent there were problems with this approach as we went along:
- The changes we needed to make to the application to allow it to become fully cloud native were extensive and required major work.
- The timeframes of the GCP migration and cloud native projects wouldn’t allow us to carry them out simultaneously.
We ultimately decided it would be better to postpone the move to Kubernetes until after migration to GCP.
We went to the next iteration and decided to use Omnibus to provision the new environment. We also migrated all file artifacts, including CI Artifacts, Traces (CI log files), file attachments, LFS objects and other file uploads to Google Cloud Storage (GCS), moving about 200TB of data off our Azure-based file servers into GCS. Doing this reduced the risk and the scale of the Geo migration.
The steps for the migration were now fairly straightforward:
- Set up a Geo secondary in GCP.
- Provision the new environment with Omnibus.
- Replicate all the data from GitLab.com in Azure to GCP.
- Test the new environment and verify all the data is correct.
- Failover to the GCP environment and promote it to primary.
There was only one major unknown left in this plan: The actual failover operation itself.
Unfortunately, Geo didn’t support a failover operation, and nobody knew exactly how to do it. It was essential that we executed this perfectly, so we used our value of iteration to get it right.

- We set up the failover procedure as an issue template in the GitLab migration issue tracker with each step as a checklist item.
- Every time we practiced, we created a new issue from the template and followed the checklist step by step.
- After each failover, we would review and consider how we could improve the process.
- We would submit these changes as merge requests to the issue template.
The merge requests were thoroughly reviewed before being approved by the team and through this very tight, iterative feedback loop, the checklist grew to cover every possible scenario we experienced. In the beginning, things almost never went according to plan, but with each iteration, we got better. In the end, there were over 140 changes in that document before we felt confident enough to move forward with the failover. We let Google know and an amazing team was assembled to help us. The failover went smoothly and we didn't experience any major problems.
Results
Going back to the goals of the project: Did we make GitLab.com suitable for mission-critical workloads? Firstly, let's consider availability on GitLab.com.
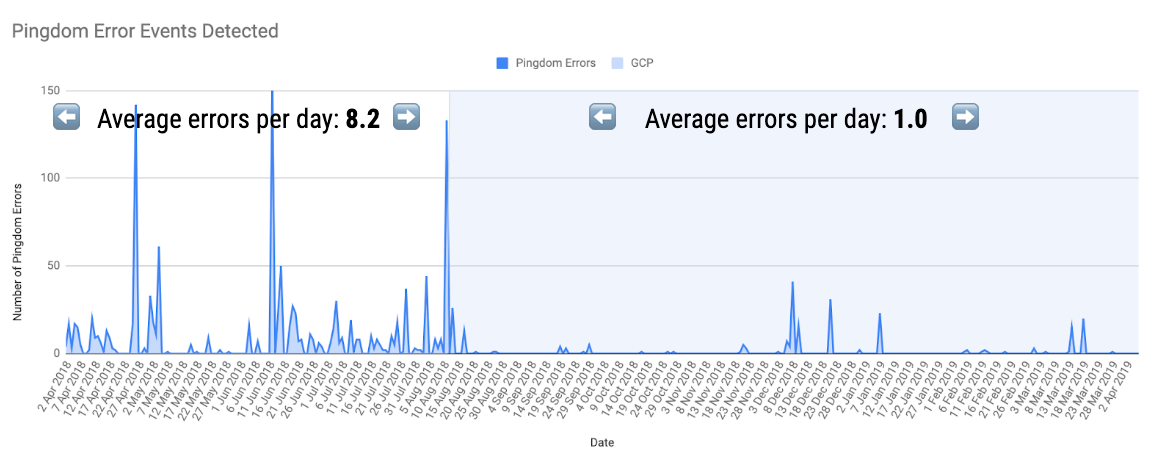
This Pingdom graph shows the number of errors we saw per day, first in Azure and then in GCP. The average for the pre-migration period was 8.2 errors per day, while post-migration it’s down to just one error a day.
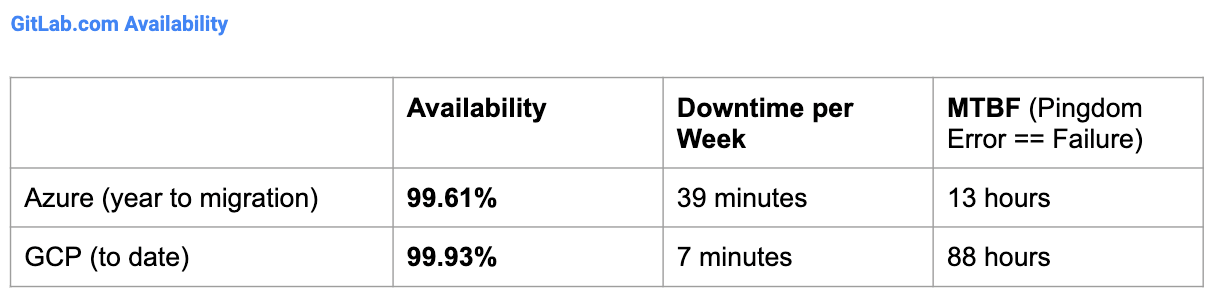
Leading up to the migration, our availability was 99.61 percent. In our October update we were at 99.88 percent. As of April 2019, we've improved to 99.93 percent and are on track to reach our target of 99.95 percent availability.
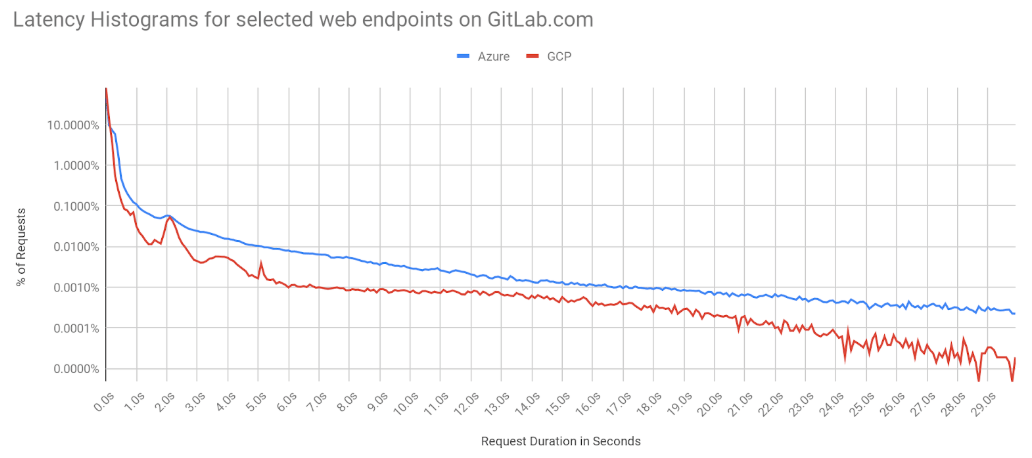
This latency histogram compares the site performance of GitLab.com before and after moving to GCP. We took data for one week before the migration and one week after the migration. The GCP line shows us that the latencies in GCP drop off quicker, which means GitLab.com is not only faster, it’s more predictable, with fewer outlier values taking an unacceptably long time.
GitLab users have also noticed the increased stability, which is an encouraging sign that we've taken steps in the right direction.
It's important to note that these improvements can't be attributed to the migration alone – we explore some other contributing factors in our October update.
What we learned
- Having this amount of visibility into a large-scale migration project is pretty unusual, but it gave us an opportunity to put our values to the test. By opening our documentation to the world, we can collaborate and help others on their own migration journey.
- Working by our values gave us the ability to get the quick feedback we needed. Even though we weren’t able to use GitLab on Kubernetes during the migration, we course-corrected and came up with the right solutions.
- We were able to see exactly how Google developers work and got an up-close look into how one of the fastest-moving companies in the world actually manages its DevOps lifecycle. This knowledge will have a long-term impact on GitLab and how we support these organizations in the future.
If you would like to learn more about how we migrated to GCP, feel free to take a look at the issue tracker and our project documentation.


