
Downtime is expensive and the cost is growing. Software reliability is as important as the product itself – it doesn't matter what your product can do if your customers can't reliably access it. GitLab's Incident Management is built-in to our DevOps Platform and empowers teams with adaptable practices and a streamlined workflow for triage and resolving incidents. We offer tools that provide access to observability resources, such as metrics, logs, errors, runbooks, and traces, that foster easy collaboration across response teams, and that support continuous improvement via post-incident reviews and system recommendations. Here's a look at how it all works.
The costs of being down
Downtime can cost companies hundreds of thousands of dollars in a single hour. Avoiding downtime is critical for organizations. Companies need to invest time, establish processes and culture around managing outages, and have processes to resolve them quickly. The larger an organization becomes, the more distributed their systems. This distribution leads to longer response times and more money lost. Investing in the right tools and fostering a culture of autonomy, feedback, quality, and automation leads to more time spent innovating and building software. If done well, teams will spend less time reacting to outages and racing to restore services. The tools your DevOps teams use to respond during incidents also have a huge effect on MTTR (Mean Time To Resolve, also known as Mean Time To Repair).
What is an incident?
Incidents are anomalous conditions that result in — or may lead to — service degradation or outages. Those outages can impact employee productivity, and decrease customer satisfaction and trust. These events require human intervention to avert disruptions or restore service to operational status. Incidents are always given attention and resolved.
What is Incident Management?
Incident Management is a process which is focused on restoring services as quickly as possible and proactively addressing early vulnerabilities and warnings, all while keeping employees productive and customers happy.
Meet GitLab Incident Management
GitLab Incident Management aims to decrease the overhead of managing incidents so response teams can spend more time actually resolving problems. We accelerate problem resolution through efficient knowledge sharing in the same tool they already use to collaborate on development. Enabling teams to quickly gather resources in one central, aggregated view gives the team a single source of truth and shortens the MTTR.
GitLab’s built-in Incident management solution provides tools for the triage, response, and remediation of incidents. It enables developers to easily triage and view the alerts and incidents generated by their application. By surfacing alerts and incidents where the code is being developed, problems can be resolved more efficiently.
Why Incident Management within GitLab?
GitLab is a DevOps Platform, delivered as a single application. As such, we believe there are additional benefits for DevOps users to manage incidents within GitLab.
-
Co-location of code, CI/CD, monitoring tools, and incidents reduces context switching and enables GitLab to correlate what would be disparate events or processes within one single control pane.
-
The same interface for development collaboration and incident response streamlines the process. The developers who are on-call can use the same interface they already use every day; this prevents the incident responders from having to use a tool they are unfamiliar with and thus hampering their ability to respond to the incident.
How to manage incidents in the GitLab DevOps Platform
Create an incident manually or automatically
You can create incidents manually or enable GitLab to create incidents automatically whenever an alert is triggered. If you use PagerDuty for incidents, you can set up a webhook with PagerDuty to automatically create a GitLab incident for each PagerDuty incident.
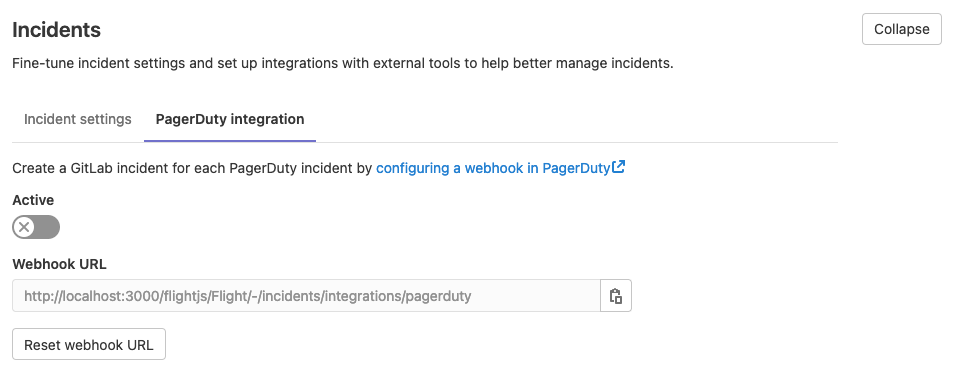
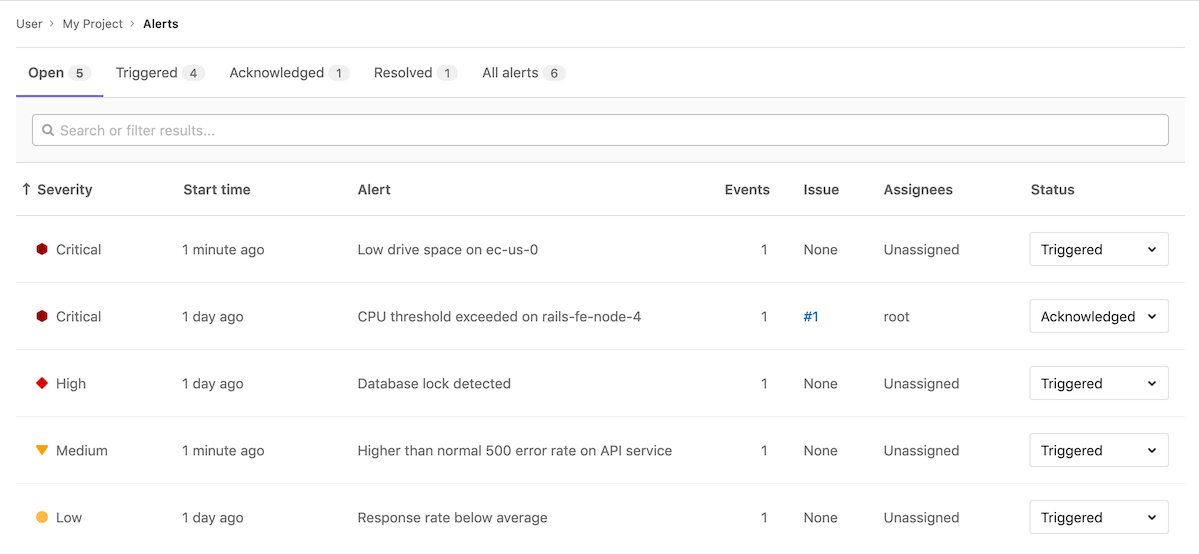
Alert Management
Alerts are a critical entity in incident management workflow. They represent a notable event that might indicate a service outage or disruption. GitLab can accept alerts from any source via a webhook receiver. GitLab provides a list view for triage and detail view for deeper investigation of what happened.
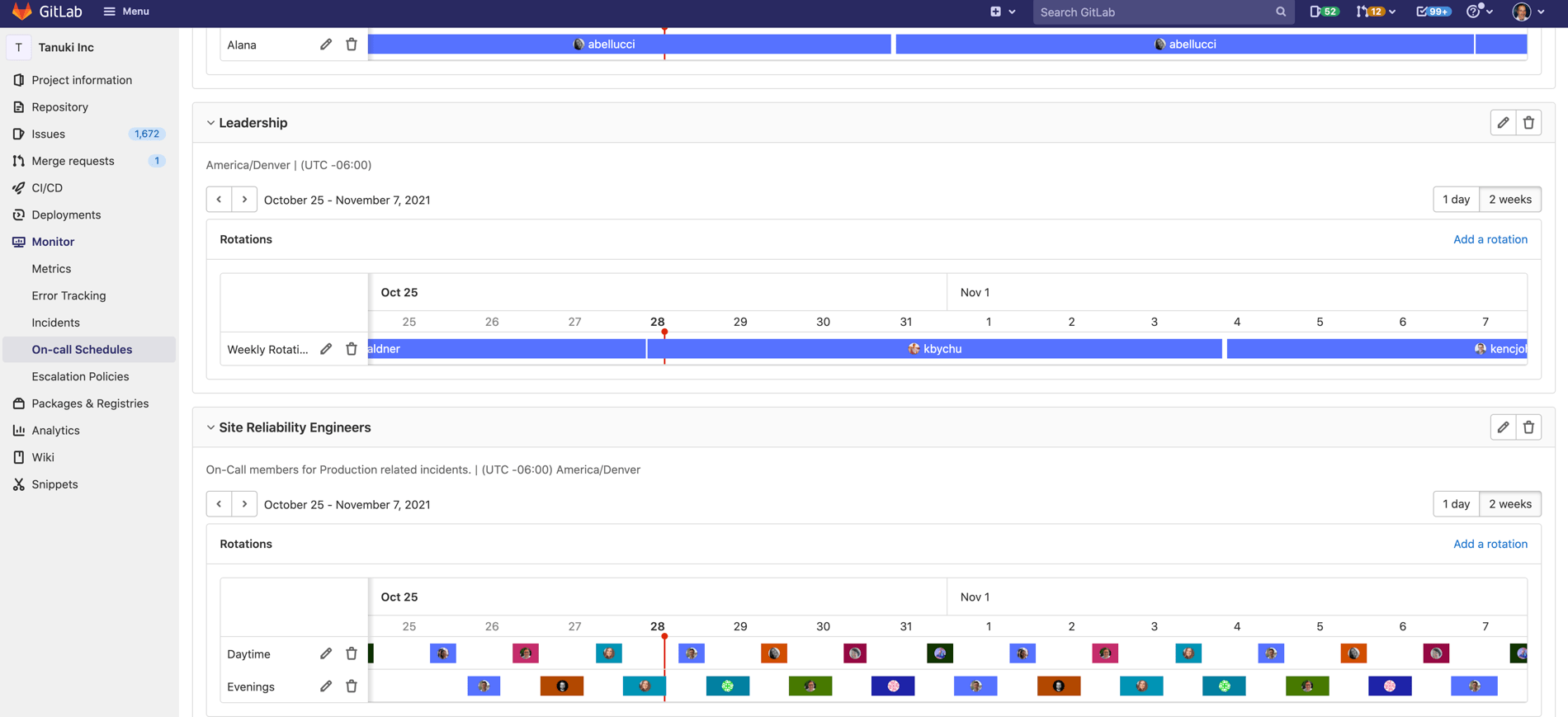
On-Call Schedules
To maintain the availability of your software services you need to schedule on-call teams. On-call schedule management is being used to create schedules for responders to rotate on-call responsibilities. Within each schedule you can add team members to rotations that last hours, weeks or days depending on your team's needs. Some teams need to be on-call just during business hours, while others have someone on-call 24/7, 365; every team is different.
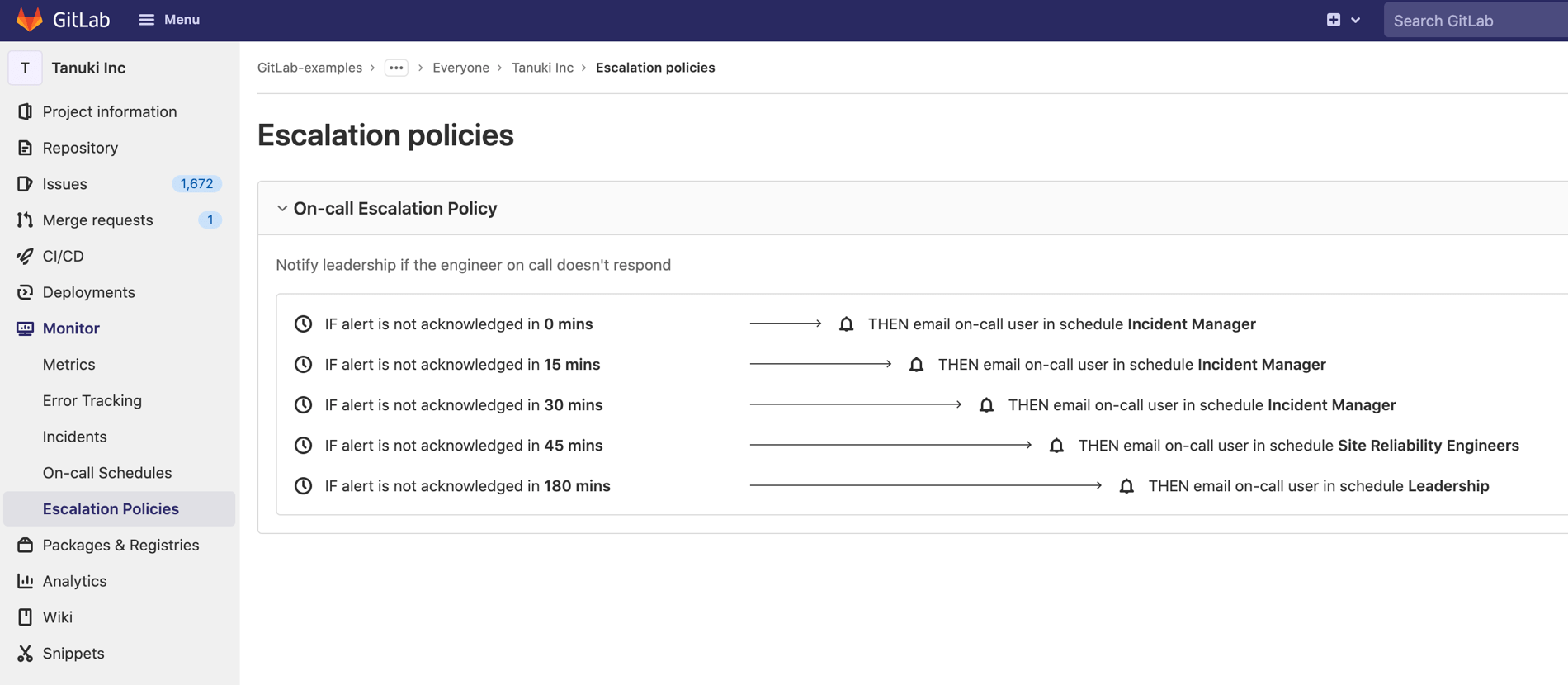
Escalation Policies
Escalation Policies determine when users on-call get notified and what happens if they don’t respond. They are the if/then logic that use on-call schedules to make sure teams never miss an incident. You can create an escalation policy in the GitLab project where you manage on-call schedules.
Paging and Notifications
When there is a new alert or incident, it is important for a responder to be notified immediately so they can triage and respond to the problem. GitLab Incident Management supports email notifications, with plans to add Slack notifications, SMS, and phone calls.


