
The scientific process and the DevOps lifecycle. At first glance, it’s hard to imagine a connection. Yet, if you look at how some of GitLab’s customers and community members are marrying the two, it makes perfect sense.
Take, for example, the European Space Agency (ESA), which uses GitLab extensively for a variety of purposes, including version control, enabling collaboration, increasing security, and coordinating the intellectual resources of its 22 member states. ESA has more than 140 groups and 1,500 projects stored on its GitLab instance. In the first year of using the DevOps Platform, ESA ran more than 60,000 pipeline jobs, allowing the organization to deploy code faster and to simplify its toolchain. The projects range from mission control systems, onboard software for spacecraft, image processing, and monitoring tools for lLabs. The ESA IT Department also uses GitLab to host its code tools and configurations infrastructure. Since adopting GitLab, ESA has enjoyed a culture of collaboration that is increasing around the organization.
As you can see with the ESA example, the connection between research and DevOps is powerful. Let’s examine why this combination works so well.
The scientific process moves through stages: asking a question, conducting background research, constructing a hypothesis, testing your hypothesis by doing an experiment, analyzing data, and reporting results. This process is very often iterative as new information is discovered throughout. It also is very collaborative as researchers work together to formulate hypotheses, gather data, and analyze the data. Many artifacts are generated throughout the process, including data, analysis scripts, results, and research papers. Often, software itself is built to run equipment, labs, or process data.
DevOps, the set of practices and tools that combines software development and information technology operations, also moves through stages. These stages include manage, plan, create, verify, and release. DevOps is also very iterative and collaborative and many different types of artifacts are generated along the way.

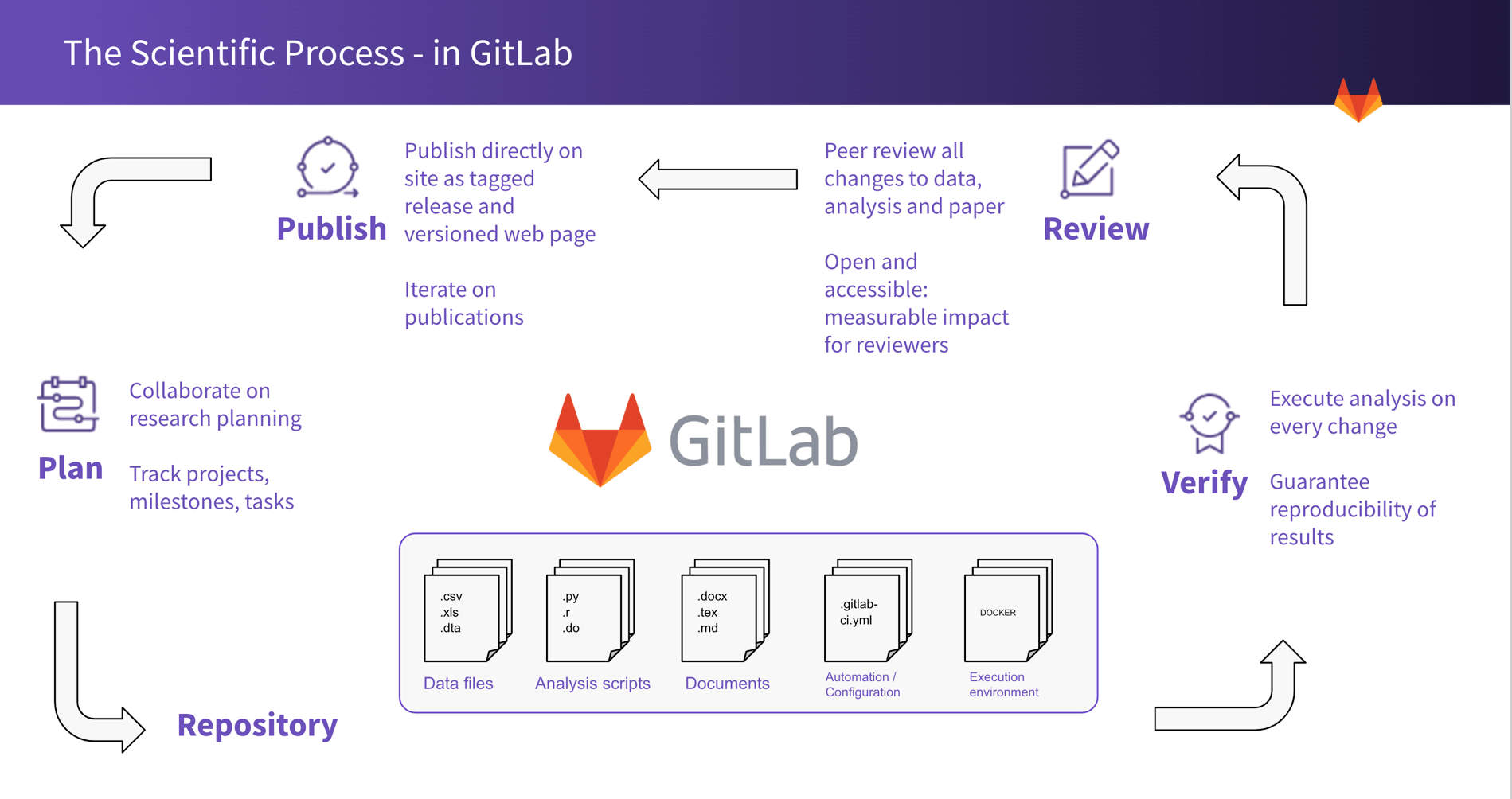
How the scientific process and the DevOps lifecycle align
We aren’t the only ones who noticed the similarities! As researchers were looking for tools to help them organize their plans, data, scripts, and results in a way that allowed them to work collaboratively and efficiently, they started using source control management. Storing their artifacts in a central repository had immediate benefits for collaboration. It was a natural progression from there expanding across the DevOps lifecycle. As the shift happened and scientists began using the DevOps lifecycle for the scientific process, the results were transformational. Shifting the approach of science to follow the DevOps lifecycle resulted in increased transparency, collaboration, reproducibility, speed to results, and data integrity.
In this transformation, the first stages of the scientific method – observing and hypothesizing – equate to the DevOps plan stage. Hypotheses and research tasks can be managed and documented in issue tracking systems. Issues define what work needs to be done and progress can be tracked with milestones and labels. No information is lost in separate email threads or local documents. Assigning issues to users, along with approver and reviewer features, can make the research process highly efficient among collaborators, graduate students, and mentors.
Data collected during the testing stage is stored in a central repository where source control management (SCM) keeps them safe and accessible. Git technology allows all changes to be controlled, tagged, versioned with branches, and peer-reviewed through merge requests. Analysis scripts are also stored in source code management as well and run using continuous integration(CI), a.k.a. the verify stage. Containerization is used to replicate computing environments and ensure reproducible results.
The role of documentation
DevOps platforms are able to transform the scientific research process because the whole research lifecycle can be documented with a single source of truth in a repository, open, shared, and accessed. Where, currently, only final results are reviewed and published in the form of papers, leaving the rest of the process mostly opaque to reviewers and the public, the DevOps workflow allows access to and collaboration on all stages of the scientific lifecycle. As this one repository hosts all stages of the scientific process, metrics can be generated on all contributions. Researchers around the world can use the same containers, environment, and analysis on their own data ensuring reproducible science.
Breaking down research silos
Most research today is happening sequentially, with locally optimized research groups working in silos. We often see duplication of work, incomplete documentation of results, and intransparent data and analysis. The DevOps transformation is shifting science to concurrent science where researchers are working collaboratively, with full transparency for reviewers.
Examples of the Research-DevOps alliance
Let’s take a look at some examples, in addition to ESA mentioned at the outset. Researchers at MathWorks use DevOps tools workflows to perform requirements-based testing on an automotive lane-following system with Model-Based Design, as mentioned in this article “Continuous Integration for Verification of Simulink Models”.
Data and code are stored in an SCM and then are forked to a testing branch. CI pipelines are used to run various experiements and tests on the code. When a test-case failure is detected in a GitLab CI pipeline, the researchers create an Issue to track and discuss the bugfix. The bug is reproduced locally in MATLAB, the issue is fixed, and the tests are run locally. The changes are reviewed on the testing branch. These changes can be committed to the testing branch where the verify, test, and build process is repeated. Researchers then create a merge equest to send the changes of the test branch into the master branch and close the corresponding Issue.
According to the authors, “CI is gaining in popularity and becoming an integral part of Model-Based Design”. The benefits of using CI cited by the researchers include: repeatability, quality assurance, reduced development time, improved collaboration, and audit-ready code.
The Square Kilometre Array Organisation (SKAO) is leading the design of the globally distributed radio telescope SKA, using GitLab SCM and CI for scientific collaboration, development efficiency, and transparency. According to Lead Software Architect Marco Bartolini, “The large success is having been able to onboard code and software projects from many different organizations and with very different tools and technology into one single platform, easily. It was not a pain, and now we got it all under control. So that's brilliant.”
The sky is the limit for how DevOps is transforming the scientific research process – perhaps it could transform yours. Vist GitLab for Education Program to learn more and watch our “GitLab for Scientific Research” video below.
Cover image by Hans Reiners on Unsplash


