Aktualisiert am: 16. Mai 2025
15 Minuten Lesezeit
Grundlagen der GitLab-CI-Pipeline: Aufgaben sequenziell parallel oder ohne Reihenfolge ausführen
Neu in der Continuous Integration? Erfahre, wie du deine erste CI-Pipeline mit GitLab erstellst.

Nehmen wir an, dass du nichts über kontinuierliche Integration (CI) and why it's needed weißt und darüber, warum sie im Lebenszyklus der Softwareentwicklung benötigt wird.
Inhaltsverzeichnis
- Der erste Test in CI
- Ergebnisse von Builds zum Herunterladen bereitstellen
- Aufträge der Reihe nach ausführen
- Welches Docker Image muss verwendet werden?
- Umgang mit komplexen Szenarien
- Umgang mit fehlender Software/Paketen
- Directed Acyclic Graphs: Schnellere und flexiblere Pipelines
- Wie wertest du deine Pipeline auf?
- Unit-Tests
- Strategien für Integrations- und End-to-End-Tests
- Testumgebung
- Implementierung von Sicherheitsscans in CI-Pipelines
- Zusammenfassung
- Beschreibungen der Keywords Stell dir vor, du arbeitest an einem Projekt, bei dem der gesamte Code aus zwei Textdateien besteht. Dabei ist es sehr wichtig, dass die Verkettung dieser beiden Dateien die Phrase „Hello world" enthält. Wenn das nicht der Fall ist, wird das gesamte Development-Team in diesem Monat nicht bezahlt. Ja, so ernst ist es! Der oder die verantwortliche Softwareentwickler(in) hat ein kleines Skript geschrieben, das jedes Mal ausgeführt wird, wenn wir unseren Code an die Kunden senden wollen. Der Code ist ziemlich komplex:
cat file1.txt file2.txt | grep -q "Hello world"
Das Problem ist, dass das Team aus 10 Entwickler(inne)n besteht. Da bleiben menschliche Fehler nicht aus. Vor einer Woche vergaß einer der Mitarbeiter(innen), das Skript auszuführen, und drei Kund(inn)en erhielten fehlerhafte Builds. Also hast du beschlossen, dieses Problem endgültig zu lösen. Glücklicherweise befindet sich der Code bereits auf GitLab, und du erinnerst dich, dass es eine integrierte CI gibt. Zudem hast du auf einer Konferenz gehört, dass viele Entwickler(innen) eine CI verwenden, um Tests durchzuführen...
12x kürzere Bereitstellungszeit: Dank GitLabs vollständiger Integration lebt Hilti Effizienz. GitLab bringt vollständige Transparenz, eine umfassende Codeverwaltung und umfangreiche Sicherheitsscans mit, um Hilti neue Softwarefähigkeiten zu ermöglichen. Erfahre, wie Hilti seine Softwareentwicklung revolutioniert hat. Erfolgsstory lesen
Der erste Test in CI
Nach ein paar Minuten Suche und Lesen der Dokumentation scheint es, dass wir nur diese zwei Codezeilen benötigen, die wir in einer Datei namens .gitlab-ci.yml finden:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
Wir übertragen die Zeilen, und siehe da– unser Build ist erfolgreich:
 Nun ändern wir in der zweiten Datei "World" zu "Africa" und prüfen, was passiert:
Nun ändern wir in der zweiten Datei "World" zu "Africa" und prüfen, was passiert:
 Der Build schlägt wie erwartet fehl!
Nun haben wir hier automatisierte Tests! GitLab CI führt unser Testskript jedes Mal aus, wenn wir neuen Code in das Quellcode-Repository in der DevOps-Umgebung übertragen.
Hinweis: Im obigen Beispiel gehen wir davon aus, dass file1.txt und file2.txt auf dem Runner-Host vorhanden sind.
Um dieses Beispiel in GitLab auszuführen, verwende den folgenden Code, der zunächst die Dateien erstellt und dann das Skript ausführt.
Der Build schlägt wie erwartet fehl!
Nun haben wir hier automatisierte Tests! GitLab CI führt unser Testskript jedes Mal aus, wenn wir neuen Code in das Quellcode-Repository in der DevOps-Umgebung übertragen.
Hinweis: Im obigen Beispiel gehen wir davon aus, dass file1.txt und file2.txt auf dem Runner-Host vorhanden sind.
Um dieses Beispiel in GitLab auszuführen, verwende den folgenden Code, der zunächst die Dateien erstellt und dann das Skript ausführt.
test:
before_script:
- echo "Hello " > | tr -d "\n" | > file1.txt
- echo "world" > file2.txt
script: cat file1.txt file2.txt | grep -q 'Hello world'
Aus Gründen der Übersichtlichkeit gehen wir davon aus, dass diese Dateien auf dem Host vorhanden sind und werden sie in den folgenden Beispielen nicht erstellen.
Ergebnisse von Builds zum Herunterladen bereitstellen
Die nächste Anforderung besteht darin, den Code zu paketieren, bevor wir ihn an unsere Kunden senden. Lass uns auch diesen Teil des Softwareentwicklungsprozesses automatisieren! Alles, was wir machen müssen, ist, einen weiteren Job für CI zu definieren. Nennen wir den Auftrag mal „Package":
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > package.gz
Nun haben wir zwei Tabs:
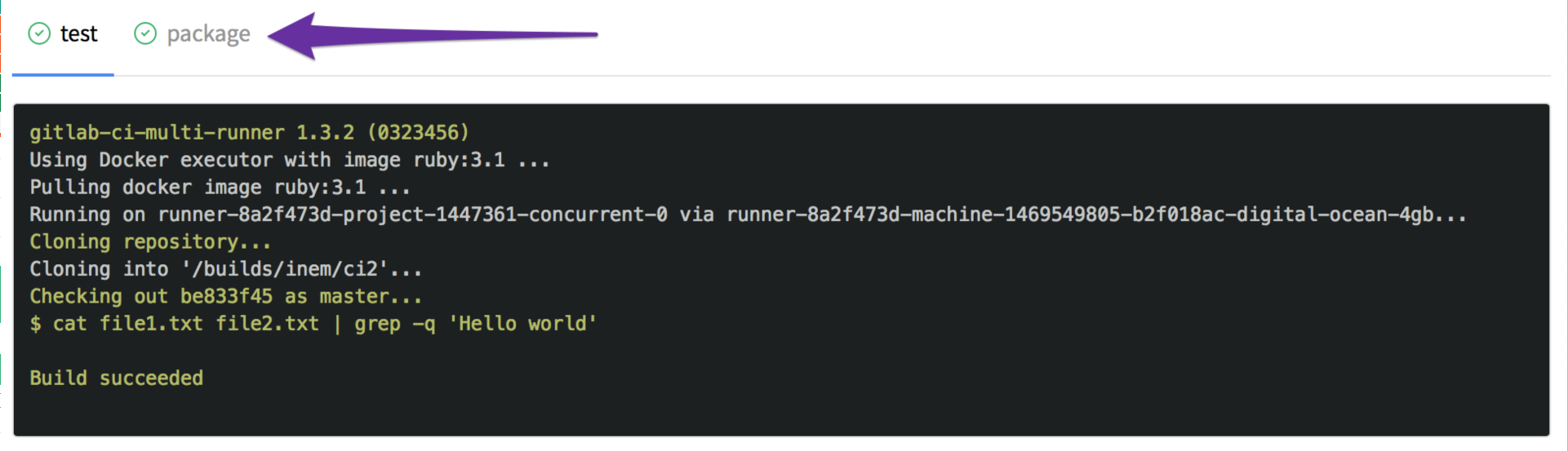 Wir haben jedoch vergessen anzugeben, dass die neue Datei ein Build-Artefakt ist, damit sie heruntergeladen werden kann. Wir können dies beheben, indem wir einen Abschnitt für Artifacts hinzufügen:
Wir haben jedoch vergessen anzugeben, dass die neue Datei ein Build-Artefakt ist, damit sie heruntergeladen werden kann. Wir können dies beheben, indem wir einen Abschnitt für Artifacts hinzufügen:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
Checking... it is there:
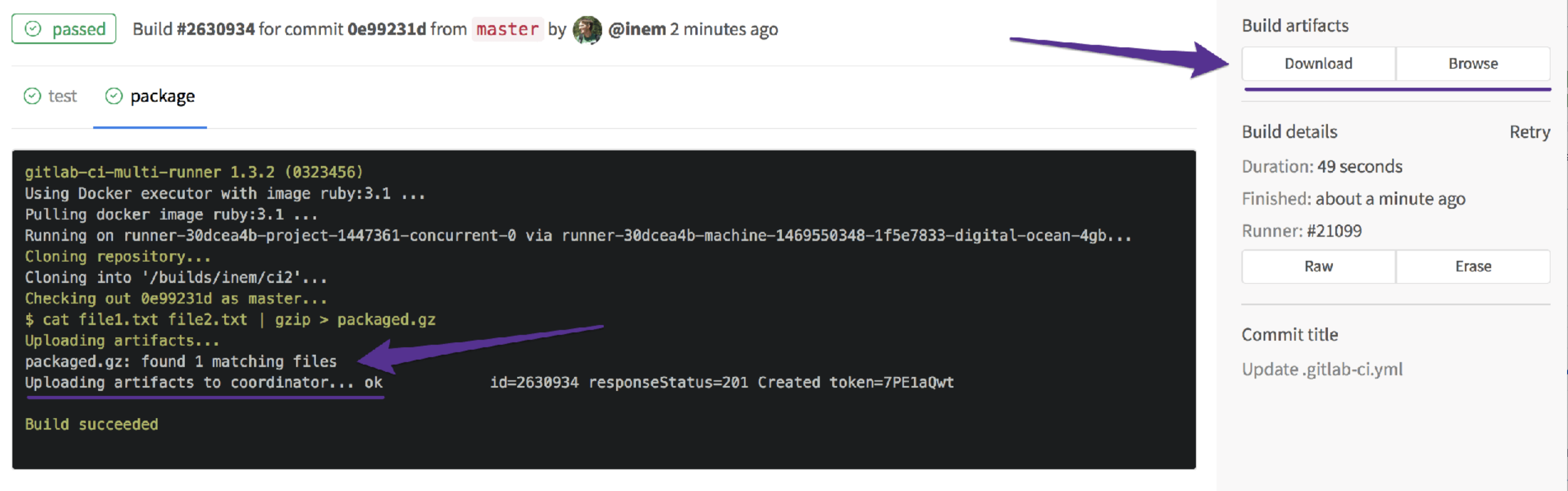 So klappt's. Wir haben jedoch noch ein Problem zu lösen: Die Aufträge laufen parallel, aber wir wollen unsere Anwendung nicht paketieren, wenn unsere Tests fehlschlagen.
So klappt's. Wir haben jedoch noch ein Problem zu lösen: Die Aufträge laufen parallel, aber wir wollen unsere Anwendung nicht paketieren, wenn unsere Tests fehlschlagen.
Aufträge der Reihe nach ausführen
Der Auftrag „Paket" soll nur ausgeführt werden, wenn die Tests erfolgreich sind. Definieren wir die Reihenfolge, indem wir stages angeben:
stages:
- test
- package
test:
stage: test
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
stage: package
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
Das sollte funktionieren! Außerdem haben wir vergessen zu erwähnen, dass die Zusammenstellung (die in unserem Fall durch Verkettung dargestellt wird) eine Weile dauert, sodass wir sie nicht zweimal ausführen wollen. Definieren wir also einen separaten Schritt dafür:
stages:
- compile
- test
- package
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
package:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
Lass uns jetzt auf unsere Artifacts an:
 Wir brauchen diese „Kompilierungsdatei" nicht zum Herunterladen. Deshalb lassen wir unsere temporären Artefakte ablaufen, indem wir expire_in auf „20 Minuten" setzen:
Wir brauchen diese „Kompilierungsdatei" nicht zum Herunterladen. Deshalb lassen wir unsere temporären Artefakte ablaufen, indem wir expire_in auf „20 Minuten" setzen:
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutes
Jetzt sieht unsere Konfiguration ziemlich beeindruckend aus:
- Wir haben drei aufeinanderfolgende Phasen zum Kompilieren, Testen und Paketieren unserer Anwendung.
- Wir übergeben die kompilierte Anwendung an die nächsten Stufen, damit die Kompilierung nicht zweimal ausgeführt werden muss (und somit schneller läuft).
- Wir speichern eine paketierte Version unserer Anwendung in Build-Artefakten für die weitere Verwendung.
Welches Docker Image muss verwendet werden?
Es scheint, dass unsere Builds immer noch langsam sind. Werfen wir einen Blick auf die Protokolle.
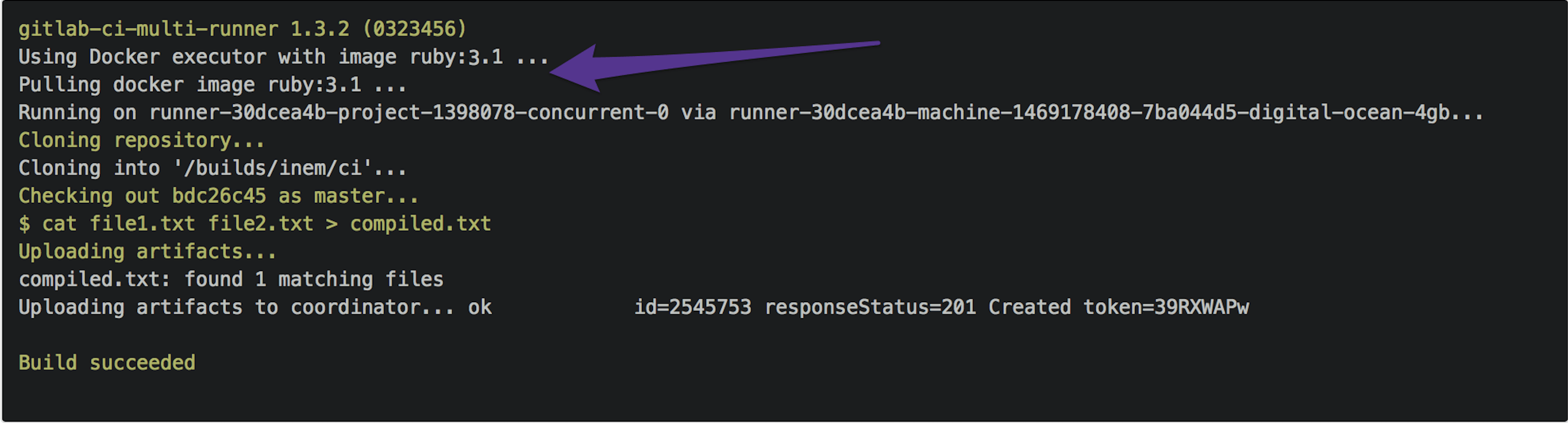 Was ist Ruby 3.1?
GitLab.com verwendet Docker-Images, um unsere Builds auszuführen, und standardmäßig wird das
Was ist Ruby 3.1?
GitLab.com verwendet Docker-Images, um unsere Builds auszuführen, und standardmäßig wird das ruby:3.1-Image verwendet. Dieses Image enthält natürlich viele Pakete, die wir nicht brauchen. Nach einer Minute des Googlens finden wir heraus, dass es ein Image namens alpine gibt, das ein fast leeres Linux-Image ist.
Wir geben also explizit an, dass wir dieses Image verwenden wollen, indem wir image: alpineto.gitlab-ci.yml`.
Wir haben so drei Minuten gespart:
 Es sieht so aus, als gäbe es viele öffentliche Images:
Es sieht so aus, als gäbe es viele öffentliche Images:
- mysql
- Python
- Java
- php Wir können also einfach eines für unseren Technologie-Stack nehmen. Es ist sinnvoll, ein Image anzugeben, das keine zusätzliche Software enthält, da dies die Downloadzeit verringert.
Umgang mit komplexen Szenarien
Nehmen wir nun aber an, wir haben neue Kund(inn)en, die möchten, dass wir unsere Anwendung in ein .iso-Image statt in ein .gz-Image packen. ISO-Images können mit dem Befehl mkisofs erstellt werden. Da CI die ganze Arbeit erledigt, können wir einfach einen weiteren Job hinzufügen. Darauf basierend sollte unsere Konfiguration so aussehen:
image: alpine
stages:
- compile
- test
- package
# ... "compile" and "test" jobs are skipped here for the sake of compactness
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
script:
- mkisofs -o ./packaged.iso ./compiled.txt
artifacts:
paths:
- packaged.iso
Beachte, dass die Auftragsnamen nicht unbedingt gleich sein sollten. Wären sie identisch, wäre es nicht möglich, die Aufträge innerhalb derselben Phase des Softwareentwicklungsprozesses parallel laufen zu lassen. Sollte es daher doch mal vorkommen, kannst du das getrost als Zufall betrachten.
Wie dem auch sei, zurück zu unserem Job, da läuft es nicht recht rund – der Build schlägt fehl:

mkisofs ist nicht im alpine Image mit dabei, also müssenw ir es erstmal installieren.
Umgang mit fehlender Software/Paketen
Laut der Alpine Linux website ist mkisofs Teil der Pakete xorriso und cdrkit. Dies sind die Befehle, die wir ausführen müssen, um ein Paket zu installieren:
echo "ipv6" >> /etc/modules # enable networking
apk update # update packages list
apk add xorriso # install package
Für CI sind dies die gleichen Befehle wie für alle anderen. Die vollständige Liste der Befehle, die wir dem Skriptabschnitt übergeben müssen, sollte wie folgt aussehen:
script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
- mkisofs -o ./packaged.iso ./compiled.txt
Um es jedoch semantisch korrekt zu machen, sollten wir die Befehle, die sich auf die Paketinstallation beziehen, in before_script unterbringen. Beachte, dass, wenn du before_script auf der obersten Ebene einer Konfiguration verwendest, die Befehle vor allen Aufträgen ausgeführt werden. In unserem Fall wollen wir nur, dass sie vor einem bestimmten Auftrag ausgeführt werden.
Directed Acyclic Graphs: Schnellere und flexiblere Pipelines
Wir haben die Stufen so definiert, dass die Paketaufgaben nur ausgeführt werden, wenn die Tests bestanden wurden. Was aber, wenn wir die Phasenabfolge ein wenig aufbrechen und einige Aufträge früher ausführen wollen, auch wenn sie in einer späteren Phase definiert sind? In einigen Fällen kann die herkömmliche Phasenabfolge die Gesamtausführungszeit der Pipeline verlangsamen. Stell dir vor, dass unsere Testphase einige umfangreichere Tests enthält, deren Ausführung viel Zeit in Anspruch nimmt und diese Tests nicht unbedingt mit den Paketaufgaben zusammenhängen. In diesem Fall wäre es effizienter, wenn die Paketaufgaben nicht auf den Abschluss dieser Tests warten müssten, bevor sie beginnen können. An dieser Stelle kommen Directed Acyclic Graphs (DAG) ins Spiel: Um die Phasenreihenfolge für bestimmte Aufträge zu unterbrechen, kannst du Abhängigkeiten von Aufgaben definieren, die die reguläre Phasenreihenfolge übergehen. GitLab verfügt über ein spezielles Keyword „needs", das Abhängigkeiten zwischen Aufträgen schafft und es ermöglicht, Aufträge früher auszuführen, sobald ihre abhängigen Aufträge abgeschlossen sind. Im folgenden Beispiel werden die Paketaufgaben ausgeführt, sobald der Testjob abgeschlossen ist. Wenn also in Zukunft jemand weitere Tests in der Testphase hinzufügt, beginnen die Paketjobs zu laufen, bevor die neuen Testjobs abgeschlossen sind
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
needs: ["test"]
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
before_script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
script:
- mkisofs -o ./packaged.iso ./compiled.txt
needs: ["test"]
artifacts:
paths:
- packaged.iso
Unsere finale Version von: .gitlab-ci.yml:
image: alpine
stages:
- compile
- test
- package
compile:
stage: compile
before_script:
- echo "Hello " | tr -d "\n" > file1.txt
- echo "world" > file2.txt
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutes
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
needs: ["test"]
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
before_script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
script:
- mkisofs -o ./packaged.iso ./compiled.txt
needs: ["test"]
artifacts:
paths:
- packaged.iso
Wir haben gerade eine Pipeline erstellt! Wir haben drei sequenzielle Stufen, die Aufträge pack-gz und pack-iso innerhalb der package-Stufe laufen parallel:

Wie wertest du deine Pipeline auf?
So kannst du deine Pipeline aufwerten.
Automatisierte Tests in CI-Pipelines einbinden
Eine wichtige Regel der DevOps-Strategie für die Softwareentwicklung besteht darin, wirklich großartige Anwendungen mit erstaunlicher Benutzererfahrung zu entwickeln. Fügen wir also einige Tests in unsere CI-Pipeline ein, um Fehler frühzeitig im gesamten Prozess zu erkennen. Auf diese Weise können wir Probleme beheben, bevor sie zu groß werden und bevor wir an einem neuen Projekt weiterarbeiten. GitLab macht uns das Leben leichter, indem es fertige Vorlagen für verschiedene Tests anbietet. Alles, was wir tun müssen, ist, diese Vorlagen in unsere CI-Konfiguration aufzunehmen. In diesem Beispiel schließen wir auch Accessibility-Tests ein:
stages:
- accessibility
variables:
a11y_urls: "https://about.gitlab.com https://www.example.com"
include:
- template: "Verify/Accessibility.gitlab-ci.yml"
Passe die Variable a11y_urls an, um die URLs der Webseiten aufzulisten, die mit Pa11y und der Codequalität getestet werden sollen.
include:
- template: Jobs/Code-Quality.gitlab-ci.yml
Mit GitLab kannst du den Testbericht direkt im Widget-Bereich der Zusammenführungsanforderung sehen. Wenn du die Codeüberprüfung, den Pipelinestatus und die Testergebnisse an einem Ort hast, wird alles reibungsloser und effizienter.
