Date de la publication : 23 juillet 2025
Lecture : 20 min
Recherche exacte de code : trouvez rapidement du code dans vos dépôts
Découvrez comment trouver des correspondances exactes, utiliser des motifs regex et afficher des résultats contextuels dans des codes sources de plusieurs téraoctets.


Imaginez pouvoir cibler n'importe quelle ligne de code parmi 48 To de dépôts en quelques millisecondes. Ceci est désormais possible avec la fonctionnalité de recherche exacte de code de GitLab qui fournit une précision extrême, une prise en charge avancée des expressions régulières (regex) et des résultats contextuels sur plusieurs lignes. En présence de dépôts de code volumineux, cette fonctionnalité facilite considérablement le travail des équipes.
Pourquoi la recherche de code traditionnelle est-elle problématique ?
Toute personne travaillant avec du code connaît la frustration de devoir chercher du code dans plusieurs dépôts. Qu'il s'agisse de déboguer un problème, d'examiner des fichiers de configuration, de rechercher des vulnérabilités, de mettre à jour une documentation ou de vérifier la mise en œuvre d'un projet, vous savez exactement ce que vous cherchez, mais les outils de recherche traditionnels vous font régulièrement défaut. Ces outils renvoient trop souvent des dizaines de faux positifs, manquent cruellement de contexte pour comprendre les résultats obtenus et sont de plus en plus lents à mesure que le code source s’étoffe. Par conséquent, vous perdez un temps précieux à chercher une aiguille dans une botte de foin au lieu de compiler, de sécuriser ou d'améliorer votre logiciel. La fonctionnalité de recherche de code de GitLab était jusqu'ici prise en charge par Elasticsearch ou OpenSearch. Bien qu'excellents pour rechercher des tickets, des merge requests, des commentaires et d'autres données contenant du langage naturel, ces outils n'ont tout simplement pas été spécifiquement conçus pour le code. Après avoir évalué de nombreuses options, nous avons développé une meilleure solution.
Qu'est-ce que la recherche exacte de code ?
La recherche exacte de code de GitLab est actuellement en phase de test bêta et optimisée par Zoekt (prononcé « zookt », qui signifie « recherche » en néerlandais). Zoekt est un moteur de recherche de code open source initialement développé par Google et aujourd'hui maintenu par Sourcegraph. Conçu spécifiquement pour une recherche de code à la fois rapide et précise à grande échelle, nous l'avons enrichi avec des intégrations propres à GitLab, des améliorations avancées et une intégration facilitée du système d'autorisations. Cette fonctionnalité révolutionne la manière dont vous recherchez et comprenez le code grâce aux trois éléments clés : 1. Un mode de recherche par correspondance exacte Lorsque vous basculez en mode de recherche par correspondance exacte, le moteur de recherche ne renvoie que les résultats qui correspondent exactement à votre requête, éliminant ainsi les faux positifs. Cette précision est inestimable dans les cas de figure suivants :
- Vous recherchez des messages d'erreur spécifiques.
- Vous recherchez des signatures de fonctions précises.
- Vous recherchez des instances de noms de variables spécifiques. 2. Un mode de recherche par expression régulière Pour les recherches complexes, ce mode vous permet de créer des motifs de recherche sophistiqués :
- Trouvez des fonctions selon des motifs de nommage spécifiques.
- Déterminez l’emplacement des variables qui correspondent à certains critères précis.
- Identifiez les failles de sécurité potentielles à l'aide de la correspondance de motifs.
3. Des correspondances sur plusieurs lignes
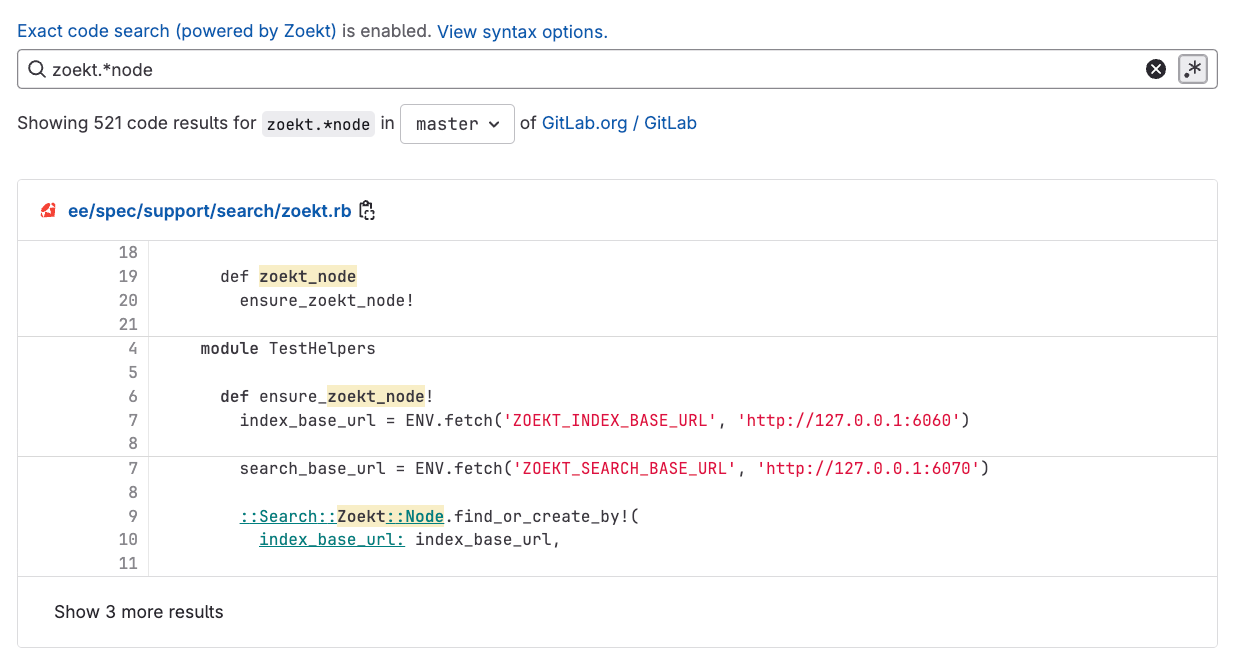 En plus de la ligne contenant le code recherché, vous avez accès au contexte environnant qui est indispensable pour bien comprendre le code. Vous n'avez donc plus besoin d'accéder aux fichiers dans le seul but d'obtenir un contexte plus clair, ce qui accélère considérablement votre workflow.
En plus de la ligne contenant le code recherché, vous avez accès au contexte environnant qui est indispensable pour bien comprendre le code. Vous n'avez donc plus besoin d'accéder aux fichiers dans le seul but d'obtenir un contexte plus clair, ce qui accélère considérablement votre workflow.
Des fonctionnalités aux workflows : cas d'utilisation et impact associé
Examinons maintenant comment ces nouvelles capacités se traduisent dans le quotidien des équipes de développement :
Débogage en quelques secondes
Voici un exemple de workflow tel qu'il pouvait être envisagé avant que la recherche exacte de code ne soit disponible : vous deviez copier un message d'erreur, lancer une recherche, parcourir une longue liste de correspondances partielles dans les commentaires, la documentation et les fragments de code, cliquer sur plusieurs fichiers... avant de trouver enfin la ligne de code que vous recherchiez. Avec la recherche exacte de code, le processus est le suivant :
- Vous copiez le message d'erreur exact.
- Vous le collez dans la fonctionnalité de recherche exacte de code en activant le mode de recherche par correspondance exacte.
- Vous trouvez instantanément l'emplacement précis où l'erreur est présente, avec le contexte environnant nécessaire à sa compréhension. Impact : vous réduisez ainsi le temps de débogage de plusieurs minutes à quelques secondes, sans frustration ni faux positifs.
Exploration rapide de codes sources inconnus
Voici un exemple de workflow tel qu'il pouvait être envisagé avant que la recherche exacte de code ne soit disponible : vous deviez parcourir les répertoires, deviner l'emplacement probable des fichiers, ouvrir des dizaines de fichiers et élaborer peu à peu une compréhension globale du code source. Avec la recherche exacte de code, le processus est le suivant :
- Vous recherchez directement les méthodes ou classes principales avec le mode de recherche par correspondance exacte.
- Vous examinez plusieurs correspondances de lignes pour comprendre les détails de leur mise en œuvre.
- Vous utilisez le mode de recherche par expression régulière pour identifier des motifs similaires dans l'ensemble du code source. Impact : vous bénéficiez d'une vision claire de l'architecture du code en quelques minutes plutôt qu'en quelques heures, ce qui accélère considérablement l'intégration de nouveaux membres au sein de l'équipe ainsi que la collaboration transversale.
Refactorisation sécurisée
Voici un exemple de workflow tel qu'il pouvait être envisagé avant que la recherche exacte de code ne soit disponible : vous deviez localiser toutes les occurrences d'une méthode, mais certaines passaient inaperçues, et vous introduisiez des bogues en raison d'une refactorisation incomplète. Avec la recherche exacte de code, le processus est le suivant :
-
Vous utilisez le mode de recherche par correspondance exacte pour identifier toutes les occurrences de méthodes ou de variables.
-
Vous examinez le contexte pour comprendre les motifs d'utilisation.
-
Vous planifiez votre refactorisation avec des informations complètes sur son impact.
Impact : vous éliminez les bogues liés aux « occurrences manquées » qui entravent souvent les efforts de refactorisation, vous améliorez la qualité du code et vous réduisez les ajustements nécessaires.
Audit de sécurité optimisé
Les équipes de sécurité peuvent :
- Créer des motifs regex ciblant les portions de code présentant des vulnérabilités connues
- Effectuer une recherche dans tous les dépôts d'un espace de nommage
- Identifier rapidement les failles de sécurité potentielles avec un contexte facilitant l'évaluation des risques Impact : vous transformez vos audits de sécurité, souvent manuels et sujets aux erreurs, en revues systématiques et exhaustives.
Informations recoupées entre plusieurs dépôts
Vos équipes peuvent effectuer une recherche dans l'ensemble de votre espace de nommage ou de votre instance pour :
- Identifier des implémentations similaires dans différents projets
- Identifier des opportunités de création de bibliothèques partagées ou de standardisation du code Impact : vous éliminez les silos entre les projets et identifiez les opportunités de réutilisation et de standardisation du code.
Zoekt : rapidité et précision au service du code
Avant de détailler nos réalisations à grande échelle, explorons ce qui distingue Zoekt des moteurs de recherche traditionnels, et pourquoi il peut trouver des correspondances exactes aussi rapidement.
Trigrammes positionnels : le secret d'une correspondance exacte ultra-rapide
La rapidité de Zoekt provient de son utilisation de trigrammes positionnels, une technique qui indexe chaque séquence de trois caractères en conservant leur position exacte dans les fichiers. Cette approche résout l'un des plus grands défis que les équipes de développement rencontrent avec la recherche de code basée sur Elasticsearch : les faux positifs.
Voici le principe :
Les moteurs de recherche plein texte traditionnels comme Elasticsearch segmentent le code en mots isolés et perdent ainsi les informations de position. Par exemple, lorsque vous recherchez getUserId(), ils peuvent renvoyer des résultats contenant les fragments user, get et Id dispersés dans un même fichier, ce qui génère des faux positifs, source de frustration pour les utilisateurs de GitLab.
Les trigrammes positionnels de Zoekt, quant à eux, conservent les séquences de caractères exactes ainsi que leurs positions dans le code. Ainsi, lorsque vous recherchez getUserId(), Zoekt cible précisément les trigrammes exacts, comme get, etU, tUs, Use, ser, erI, rId, Id(", "d(), dans cette séquence précise et à ces positions exactes. Cette approche garantit que seules les correspondances exactes sont renvoyées.
Ainsi, des recherches qui renvoyaient auparavant des centaines de faux positifs ne renvoient désormais plus que les correspondances exactes souhaitées. Cette fonctionnalité était l'une des plus demandées pour une bonne raison : les équipes de développement perdaient beaucoup trop de temps à passer au crible les faux positifs.
Performances des expressions régulières à grande échelle
Zoekt excelle dans la recherche de correspondances exactes, mais est également optimisé pour les recherches d'expressions régulières. Grâce à des algorithmes sophistiqués, il convertit les motifs regex en requêtes trigrammes efficaces lorsque cela est possible, garantissant ainsi une rapidité constante, même pour les recherches de motifs complexes portant sur plusieurs téraoctets de code.
Une fonctionnalité adaptée aux entreprises
La recherche exacte de code est puissante et conçue pour gérer de très grands volumes de code tout en offrant des temps de réponse remarquables. Il ne s'agit pas du simple ajout d'une nouvelle fonctionnalité à l'interface utilisateur, mais d'une architecture backend entièrement repensée.
Gestion de plusieurs téraoctets de code en toute simplicité
Rien que sur GitLab.com, notre infrastructure de recherche exacte de code indexe et interroge plus de 48 To de données de code, tout en offrant des temps de réponse ultra-rapides. Cette volumétrie couvre des millions de dépôts répartis dans des milliers d'espaces de nommage, tous consultables en seulement quelques millisecondes, soit plus de code que l'ensemble des projets du noyau Linux, d'Android et de Chromium combinés. Et pourtant, la recherche exacte de code peut trouver une ligne spécifique dans l'ensemble du code source en quelques millisecondes seulement.
Architecture de nœuds à enregistrement automatique
Parmi nos améliorations techniques, voici quelques innovations clés :
- Enregistrement automatique des nœuds : les nœuds Zoekt s'enregistrent automatiquement auprès de GitLab.
- Attribution dynamique des partitions : le système attribue automatiquement les espaces de nommage entre les nœuds.
- Surveillance de l'état : les nœuds qui ne s'enregistrent pas sont automatiquement signalés comme hors ligne. Cette architecture à configuration automatique simplifie considérablement la montée en charge. Lorsque la capacité doit être augmentée, les administrateurs peuvent tout simplement ajouter de nouveaux nœuds, sans aucune reconfiguration complexe.
Système distribué avec répartition de charge intelligente
En arrière-plan, la recherche exacte de code repose sur un système distribué comprenant les composants clés suivants :
- Nœuds de recherche spécialisés : serveurs dédiés pour gérer l'indexation et la recherche
- Partitionnement intelligent : le code est réparti entre les nœuds en fonction des espaces de nommage
- Équilibrage automatique de la charge : le système répartit intelligemment le travail en fonction des capacités disponibles
- Haute disponibilité : plusieurs réplicas assurent la continuité du service même en cas de défaillance d'un nœud Remarque : la haute disponibilité fait partie intégrante de l'architecture, mais n'est pas encore entièrement déployée. Consultez le ticket 514736 pour vous tenir au courant des futures mises à jour.
Intégration sans accroc de la sécurité
La recherche exacte de code s'intègre automatiquement au système d'autorisation de GitLab :
- Les résultats de recherche sont filtrés en fonction des droits d'accès de chaque utilisateur.
- Seul le code des projets auxquels l'utilisateur a accès est affiché.
- La sécurité est intégrée à l'architecture de base, et non ajoutée ultérieurement.
Performances optimisées
- Indexation performante : les dépôts volumineux sont indexés en quelques dizaines de secondes.
- Exécution rapide des requêtes : la plupart des recherches renvoient des résultats en moins d'une seconde.
- Résultats en streaming : la nouvelle recherche fédérée basée sur gRPC diffuse les résultats au fur et à mesure de leur découverte.
- Arrêt anticipé : dès qu'un nombre suffisant de résultats a été collecté, le système interrompt la recherche.
De la bibliothèque au système distribué : notre réponse aux défis d'ingénierie
Bien que Zoekt soit très performant pour indexer et rechercher du code localement, son architecture de base était conçue à l'origine comme une bibliothèque minimale, destinée à la gestion des fichiers d'index .zoekt, et non comme une base de données distribuée ou un service capable de fonctionner à l'échelle d'une entreprise.
Voici les principaux défis techniques que nous avons dû surmonter pour l'adapter pleinement à l'écosystème GitLab.
Défi 1 : création d'une couche d'orchestration
Le problème : Zoekt a été conçu pour fonctionner avec des fichiers d'index locaux, et non pour être distribué sur plusieurs nœuds desservant de nombreux utilisateurs simultanés. Notre solution : nous avons développé une couche d'orchestration complète qui :
- crée et gère des modèles de base de données pour suivre les nœuds, les index, les dépôts et les tâches.
- met en œuvre une architecture de nœuds à enregistrement automatique (inspirée du fonctionnement de GitLab Runner).
- gère l'attribution automatique des partitions et l'équilibrage de la charge entre les nœuds.
- fournit une communication bidirectionnelle de l'API entre les nœuds GitLab Rails et Zoekt.
Défi 2 : mise à l'échelle du stockage et de l'indexation
Le problème : comment gérer efficacement des téraoctets de données d'indexation répartis sur plusieurs nœuds tout en garantissant des mises à jour rapides ? Notre solution : nous avons déployé les fonctionnalités suivantes :
- Partitionnement intelligent : les espaces de nommage sont répartis entre les nœuds en tenant compte de leur capacité et de leur charge.
- Réplication indépendante : chaque nœud est indexé indépendamment à partir de Gitaly (notre service de stockage Git), évitant ainsi toute synchronisation complexe.
- Gestion avancée des filigranes : un système sophistiqué d'allocation de stockage empêche les nœuds de manquer d'espace.
- Architecture binaire unifiée : un seul binaire
gitlab-zoektpeut fonctionner à la fois en mode indexeur et en mode serveur web.
Défi 3 : intégration des autorisations
Le problème : Zoekt n'avait aucune notion du système d'autorisation complexe de GitLab. Les utilisateurs ne doivent voir que les résultats des projets auxquels ils ont accès. Notre solution : nous avons intégré un filtrage des autorisations natif directement dans le flux de recherche :
- Les requêtes de recherche incluent le contexte des autorisations de l'utilisateur.
- Les résultats sont filtrés pour n’inclure que les éléments auxquels l'utilisateur peut accéder, même dans le cas où les autorisations évoluent avant la fin de l'indexation.
Défi 4 : simplification opérationnelle
Le problème : gérer un système de recherche distribué ne devrait pas nécessiter une équipe dédiée. Notre solution :
- Mise à l'échelle automatique : l'ajout de capacité est aussi simple que le déploiement de nœuds supplémentaires. Ces derniers s'enregistrent automatiquement et gèrent immédiatement la charge de travail.
- Auto-réparation : les nœuds qui ne s'enregistrent pas sont automatiquement signalés comme hors ligne, avec redistribution automatique de leurs tâches.
- Partitionnement sans configuration : le système détermine automatiquement les affectations de partitions optimales.
Déploiement progressif : réduire les risques à grande échelle
Le déploiement d'un tout nouveau backend de recherche auprès de millions d'utilisateurs a nécessité une planification minutieuse. Voici comment nous avons limité l'impact sur les clients tout en garantissant la fiabilité :
Phase 1 : tests contrôlés (groupe gitlab-org)
Nous avons commencé par activer la recherche exacte de code uniquement pour le groupe gitlab-org, constitué de nos propres dépôts internes.
Cette étape nous a permis de :
- Tester le système avec des charges de travail réelles en production
- Identifier et corriger les goulots d'étranglement liés aux performances
- Rationaliser le processus de déploiement
- Tirer des enseignements concrets sur les workflows grâce aux retours d'utilisateurs
Phase 2 : validation et optimisation des performances
Avant d'étendre la fonctionnalité, nous nous sommes assurés que le système pouvait gérer la charge à l'échelle de GitLab.com. Pour cela, nous avons dû :
- Mettre en œuvre une surveillance et une gestion des alertes complètes
- Valider la gestion du stockage basée sur la croissance réelle des données en production
Phase 3 : expansion progressive auprès des clients
Nous avons progressivement ouvert l'accès à la recherche exacte de code aux clients désireux de l'essayer, afin de :
- Collecter leurs retours sur les performances et l'expérience utilisateur
- Affiner l'interface utilisateur de recherche en fonction des workflows réels des utilisateurs
- Optimiser les performances d'indexation (par exemple, les grands dépôts comme
gitlab-org/gitlabsont désormais indexés en environ 10 secondes) - Ajuster l'architecture en fonction des leçons tirées des premiers essais
- Augmenter massivement le débit d'indexation et améliorer le cycle de vie des transitions d'état
Phase 4 : déploiement à grande échelle
Aujourd'hui, plus de 99 % des groupes disposant des licences Premium et Ultimate sur GitLab.com ont accès à la recherche exacte de code. Les utilisateurs peuvent :
- Basculer facilement entre les modes de recherche par expression régulière et par correspondance exacte
- Tirer parti des avantages sans modifier la configuration
- Revenir à l'ancienne méthode de recherche si nécessaire (bien que peu d'entre eux optent pour cette possibilité) Ce déploiement progressif a permis d'éviter toute interruption de service, baisse de performances ou perte de fonctionnalités pendant la transition. Les premiers retours sont très positifs, car les utilisateurs constatent que leurs résultats de recherche sont plus pertinents et qu'ils les obtiennent beaucoup plus rapidement.
Vous souhaitez en savoir plus sur l'architecture et la mise en œuvre de la recherche exacte de code ? Consultez notre document de conception complet, qui offre une description technique détaillée de ce système de recherche distribué.
Premiers pas : comment lancer une recherche exacte de code ?
La prise en main de la recherche exacte de code est simple, car cette fonctionnalité est déjà activée par défaut pour les groupes Premium et Ultimate sur GitLab.com (accessibles aujourd'hui à plus de 99 % des groupes éligibles).
Guide de démarrage rapide
- Accédez à la recherche avancée depuis votre projet ou groupe GitLab.
- Saisissez votre terme de recherche dans l'onglet Code.
- Basculez entre les modes de recherche par correspondance exacte et par expression régulière.
- Utilisez des filtres pour affiner votre recherche.
Syntaxe de recherche de base
Que vous utilisiez le mode de recherche par correspondance exacte ou par expression régulière, vous pouvez affiner votre recherche avec divers modificateurs :
| Exemple de requête | Fonction | | ------------------ | ---------------------------------------------------------------------- | | file:js | Recherche uniquement dans les fichiers dont le nom contient « js » | | foo -bar | Recherche « foo », mais exclut les résultats contenant « bar » | | lang:ruby | Recherche uniquement dans les fichiers Ruby | | sym:process | Recherche « process » dans les symboles (méthodes, classes, variables) |
Conseil : pour optimiser votre recherche, commencez par une requête précise, puis élargissez-la si besoin. L'utilisation des filtres
file:etlang:augmente considérablement la pertinence des résultats.
Techniques de recherche avancées
Combinez plusieurs filtres pour gagner en précision :
is_expected file:rb -file:spec
Cette requête recherche « is_expected » dans les fichiers Ruby dont le nom ne contient pas « spec ». Tirez parti des expressions régulières pour obtenir des motifs puissants :
token.*=.*[\"']
Consultez cette recherche effectuée dans le dépôt GitLab Zoekt. Elle permet de trouver des mots de passe codés en dur qui, s'ils ne sont pas détectés, peuvent constituer un risque de sécurité. Pour approfondir la syntaxe, consultez la documentation dédiée à la recherche exacte de code.
Disponibilité et déploiement
Disponibilité actuelle
La recherche exacte de code est actuellement disponible en version bêta pour les utilisateurs de GitLab.com disposant de licences Premium et Ultimate :
- Elle est accessible à plus de 99 % des groupes éligibles sous licence.
- La recherche dans l'interface utilisateur utilise automatiquement Zoekt lorsqu'il est disponible ; la recherche exacte de code via l'API de recherche est activée par le biais d'un feature flag.
Options de déploiement pour les instances Self-Managed
Pour les instances Self-Managed, nous proposons plusieurs méthodes de déploiement :
- Kubernetes/Helm : notre méthode la mieux prise en charge, basée sur notre Helm Chart
gitlab-zoekt. - Autres méthodes : nous travaillons actuellement sur la simplification du déploiement via Omnibus et d'autres options d'installation. Les exigences en configuration système varient selon la taille de votre code source, mais l'architecture est conçue pour s'adapter horizontalement et/ou verticalement à mesure que vos besoins évoluent.
Prochaines étapes
Bien que la recherche exacte de code soit déjà performante, nous l'améliorons continuellement avec :
- Des optimisations à grande échelle pour gérer des instances comptant des centaines de milliers de dépôts
- Des options de déploiement renforcées pour les instances Self-Managed, y compris la prise en charge simplifiée d'Omnibus
- Une prise en charge complète de la haute disponibilité avec basculement automatique et équilibrage de la charge Restez à l'écoute pour suivre les prochaines mises à jour lorsque nous passerons de la version bêta à la disponibilité générale.
Transformez votre façon de rechercher des lignes de code
Avec la recherche exacte de code, GitLab repense en profondeur la manière dont le code est exploré, en fournissant des correspondances exactes, une prise en charge avancée des expressions régulières et des résultats contextuels. Cette nouvelle fonctionnalité résout les aspects les plus frustrants de la recherche de code :
- Ne perdez plus votre temps avec des résultats non pertinents.
- Ne ratez plus aucune correspondance importante.
- N'ouvrez plus plusieurs fichiers juste pour comprendre le contexte de base.
- Ne subissez plus de problèmes de performances à mesure que la taille de vos dépôts de code augmente. L'impact s'étend même bien au-delà, à la productivité globale des équipes :
- Vos équipes collaborent plus efficacement avec un référencement clair du code.
- Le partage des connaissances s'accélère avec la détection facile des motifs.
- L'intégration des nouveaux membres d'équipe s'accélère avec une compréhension rapide du code source.
- La sécurité est renforcée avec un audit efficace des motifs.
- Une réduction de la dette technique devient réellement envisageable. La recherche exacte de code est plus qu'une simple fonctionnalité : elle vous permet de mieux comprendre et de gérer le code. Alors, arrêtez de chercher et commencez à trouver ! Nous serions ravis de connaître votre avis. Partagez vos expériences, vos questions ou vos commentaires sur la recherche exacte de code dans notre ticket dédié aux retours d'expérience. Vos retours nous aident à hiérarchiser nos priorités d'améliorations et à enrichir nos futures fonctionnalités.