Aktualisiert am: 23. Oktober 2024
8 Minuten Lesezeit
Application Performance Monitoring (APM) mit Distributed Tracing
Erfahre, wie Distributed Tracing die Fehlerbehebung bei Problemen mit der Application Performance unterstützt, indem es eine durchgängige Transparenz und eine nahtlose Zusammenarbeit innerhalb deines Unternehmens ermöglicht.


Ausfallzeiten aufgrund von Anwendungsfehlern oder Performance-Problemen können für Unternehmen verheerende finanzielle Folgen haben. Laut Information einer Umfrage der ITIC von 2022 kostet eine Stunde Ausfallzeit Unternehmen schätzungsweise 301.000 $ oder mehr. Diese Probleme sind häufig auf von Menschen vorgenommene Änderungen zurückzuführen, z. B. Code- oder Konfigurationsänderungen.
Um Probleme schnell zu beheben, müssen Entwicklungs- und Betriebsteams Hand in Hand arbeiten, um die Ursache zu finden und das System zügig wiederherzustellen. Häufig nutzen sie jedoch unterschiedliche Tools, um ihre Anwendungen und Infrastruktur zu verwalten und zu überwachen. Das führt zu isolierten Daten, schlechter Kommunikation und einem unvollständigen Überblick – was die Lösung von Vorfällen verzögert.
Nahezu 100 % Uptime: NVIDIA skaliert mit GitLab global – ohne Ausfallzeiten Verteilte Teams bei NVIDIA profitieren mit GitLab Geo von schneller verfügbaren Repositories, häufigeren Upgrades ohne Ausfallzeiten und global-synchronen sowie -sicheren Projekten. Erfahre, wie GitLab Premium hilft, Stabilität, Transparenz und Effizienz zu verbessern. Erfolgsstory lesen
GitLab setzt genau hier an und vereint Softwarebereitstellung und Monitoring auf einer Plattform. Letztes Jahr haben wir Error Tracking in GitLab 16.0 als feste Funktion integriert. Jetzt freuen wir uns, die Beta-Version von Distributed Tracing vorzustellen – der nächste große Schritt zu einem umfassenden Monitoring, das vollständig in die GitLab-DevSecOps-Plattform eingebettet ist.
Eine neue Ära der Effizienz: GitLab Observability
GitLab Observability ermöglicht es Entwicklungs- und Operationsteams, Fehler, Traces, Protokolle und Metriken aus ihren Anwendungen und ihrer Infrastruktur zu visualisieren und zu analysieren. Durch die Integration des Application Performance Monitoring in bestehende Softwarebereitstellungs-Workflows werden Kontextwechsel minimiert und die Produktivität erhöht, sodass die Teams auf einer einheitlichen Plattform fokussiert zusammenarbeiten können.
Darüber hinaus überbrückt GitLab Observability die Kluft zwischen Entwicklung und Betrieb, indem es Einblicke in die Application Performance in der Produktion gewährt. Dies verbessert die Transparenz, den Informationsaustausch und die Kommunikation zwischen den Teams. Folglich können sie Fehler und Leistungsprobleme, die durch neuen Code oder Konfigurationsänderungen entstehen, schneller und effektiver erkennen und beheben und so verhindern, dass diese Probleme zu größeren Vorfällen eskalieren, die sich negativ auf das Geschäft auswirken könnten.
Was ist Distributed Tracing?
Mit Distributed Tracing können Entwickler(innen) die Ursache von Leistungsproblemen bei Anwendungen und in der Architektur verteilter Systeme ermitteln. Ein Trace stellt eine einzelne Benutzeranfrage dar, die verschiedene Dienste und Systeme durchläuft. Die Entwickler(innen) sind in der Lage, den zeitlichen Ablauf der einzelnen Vorgänge und alle auftretenden Fehler zu analysieren.
Jede Protokollierung besteht aus einem oder mehreren Abschnitten, die einzelne Vorgänge oder Arbeitseinheiten darstellen. Spans enthalten Metadaten wie den Namen, Zeitstempel, Status und relevante Tags oder Protokolle. Durch die Untersuchung der Abhängigkeiten zwischen Spans können Entwickler(innen) den Request Flow verstehen, Performance-Engpässe erkennen und Probleme lokalisieren.
Distributed Tracing in Microservices
Distributed Tracing ist besonders wertvoll für Microservices-Strukturen, bei denen eine einzige Anfrage zahlreiche Serviceaufrufe in einem komplexen System nach sich ziehen kann. Tracing bietet Einblick in diese Interaktion und ermöglicht es den Teams, Probleme schnell zu diagnostizieren und zu beheben.
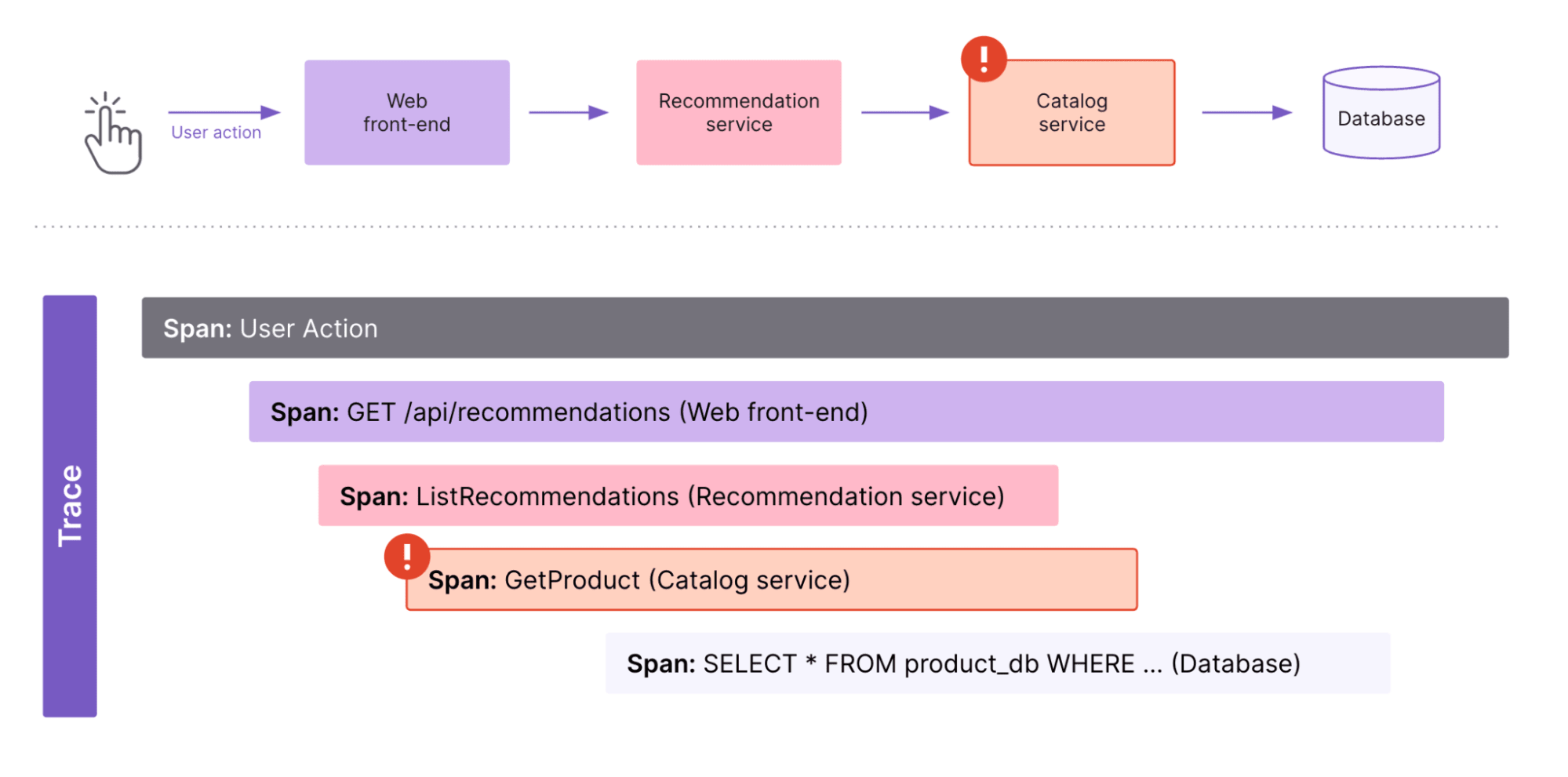
Dieses Beispiel veranschaulicht, wie eine Nutzeranfrage verschiedene Dienste durchläuft, um Produktempfehlungen auf einer E-Commerce-Website abzurufen:
User Action: Dies zeigt die erste Aktion der Nutzer(innen) an, z. B. das Anklicken einer Schaltfläche zur Anforderung von Produktempfehlungen auf einer Produktseite.Web front-end: Das Web-Frontend sendet eine Anfrage an den Empfehlungsdienst, um Produktempfehlungen abzurufen.Recommendation service: Die Anfrage vom Web-Frontend wird vom Recommendation Service (dt. Empfehlungsservice) bearbeitet, der die Anfrage verarbeitet und eine Liste empfohlener Produkte erstellt.Catalog service: Der Recommendation Service ruft den Servicekatalog auf, um Details zu den empfohlenen Produkten abzurufen. Ein Warnsymbol weist auf ein Problem oder eine Verzögerung in dieser Phase hin, z. B. eine zu langsame Rückmeldung oder einen Fehler beim Abrufen von Produktdetails.Database: Der Catalog Service fragt die Datenbank ab, um die aktuellen Produktdaten abzurufen. Dieser Bereich zeigt die SQL-Abfrage in der Datenbank.
Durch die Visualisierung dieses End-to-End-Trace können Entwickler(innen) Leistungsprobleme – hier ein Fehler im Servicekatalog – erkennen und Probleme im gesamten Distributionssystem schnell diagnostizieren und beheben.
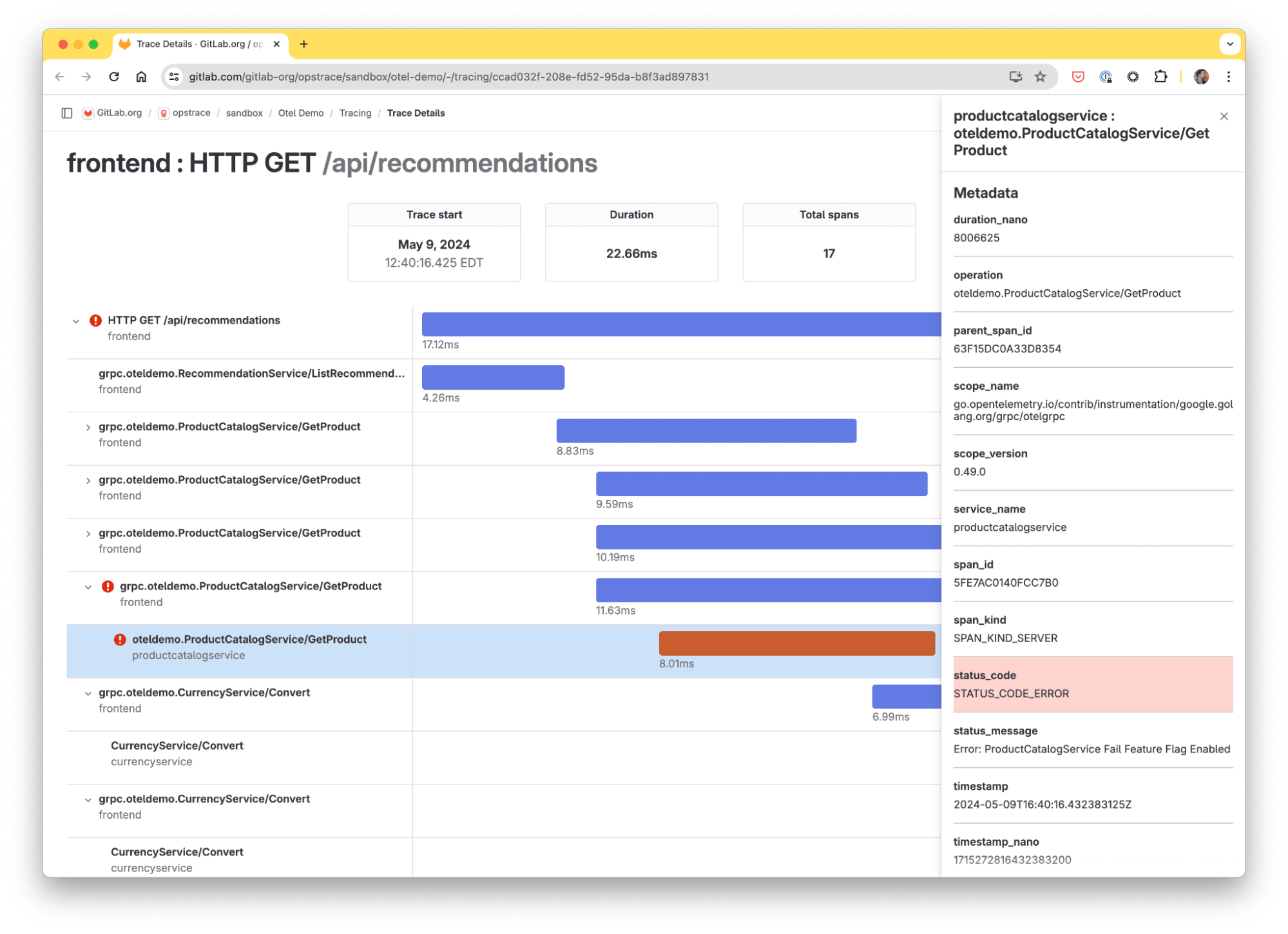
Wie funktioniert Distributed Tracing?
Im Folgenden wird die Funktionsweise von Distributed Tracing Tools erläutert.
Sammeln von Daten aus beliebigen Anwendungen mit OpenTelemetry
Traces und Spans können mit OpenTelemetry gesammelt werden, einem Open-Source-Framework für Beobachtungen, das eine breite Palette von SDKs und Bibliotheken für die wichtigsten Programmiersprachen und Frameworks unterstützt. Dieses Framework bietet einen herstellerneutralen Ansatz für die Erfassung und den Export von Telemetriedaten, sodass Entwickler(innen) nicht an einen bestimmten Anbieter gebunden sind und die Tools auswählen können, die ihren Anforderungen am besten entsprechen.
Das bedeutet, dass du, wenn du bereits OpenTelemetry mit einem anderen Anbieter verwendest, Daten an uns senden kannst, indem du einfach unseren Endpunkt zu deiner Konfigurationsdatei hinzufügst –so kannst du unsere Funktionen ohne Weiteres ausprobieren!
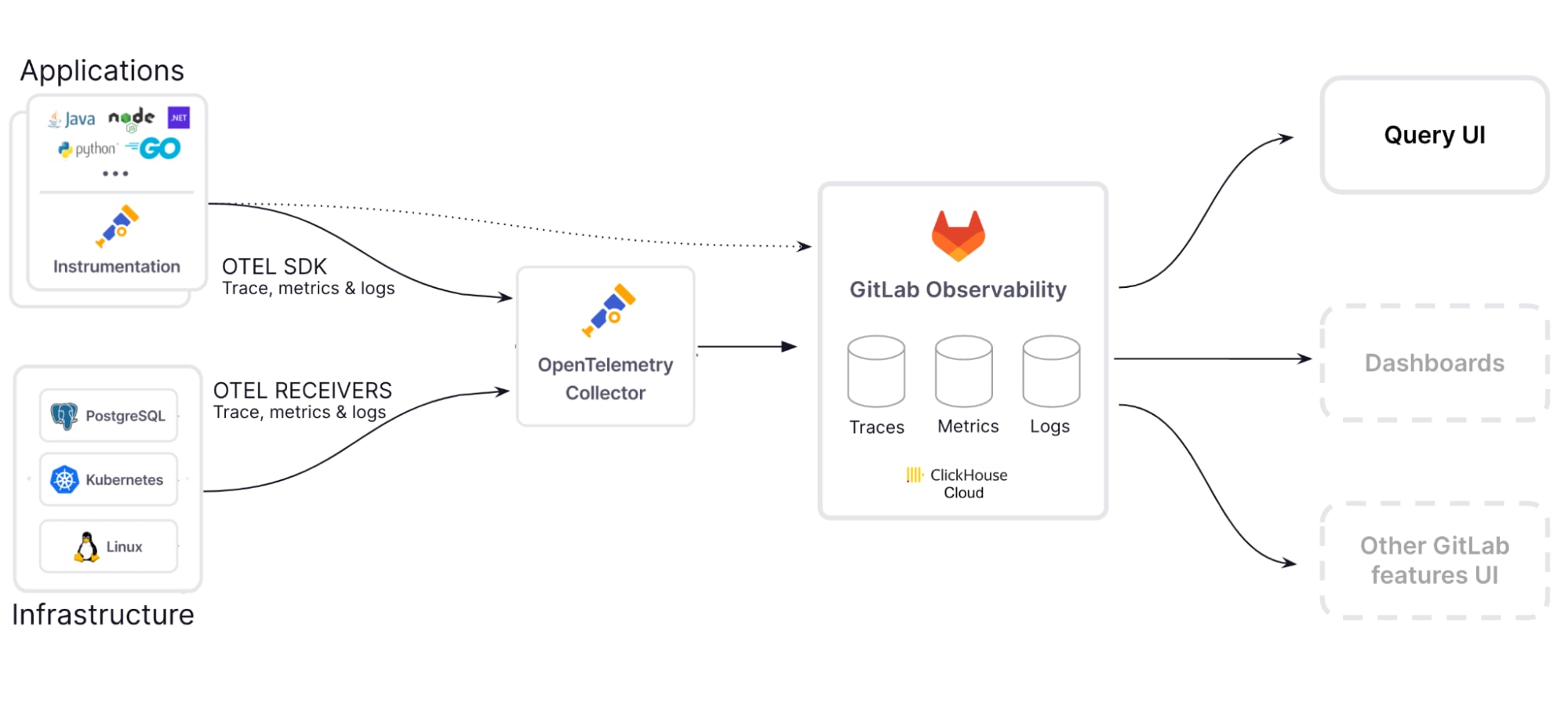
Datenerfassung und -speicherung in großem Umfang mit schnellen Echtzeitabfragen
Beobachtbarkeiterfordert die Speicherung und Abfrage riesiger Datenmengen bei gleichzeitiger Beibehaltung niedriger Latenzzeiten für Echtzeit-Analysen. Um diese Anforderungen zu erfüllen, haben wir eine horizontal skalierbare Langzeitspeicherlösung mit ClickHouse und Kubernetes entwickelt, die auf unserer Übernahme von Opstrace basiert. Diese Open-Source-Plattform gewährleistet eine schnelle Abfrageleistung und Skalierbarkeit auf Unternehmensebene, während gleichzeitig die Kosten minimiert werden.
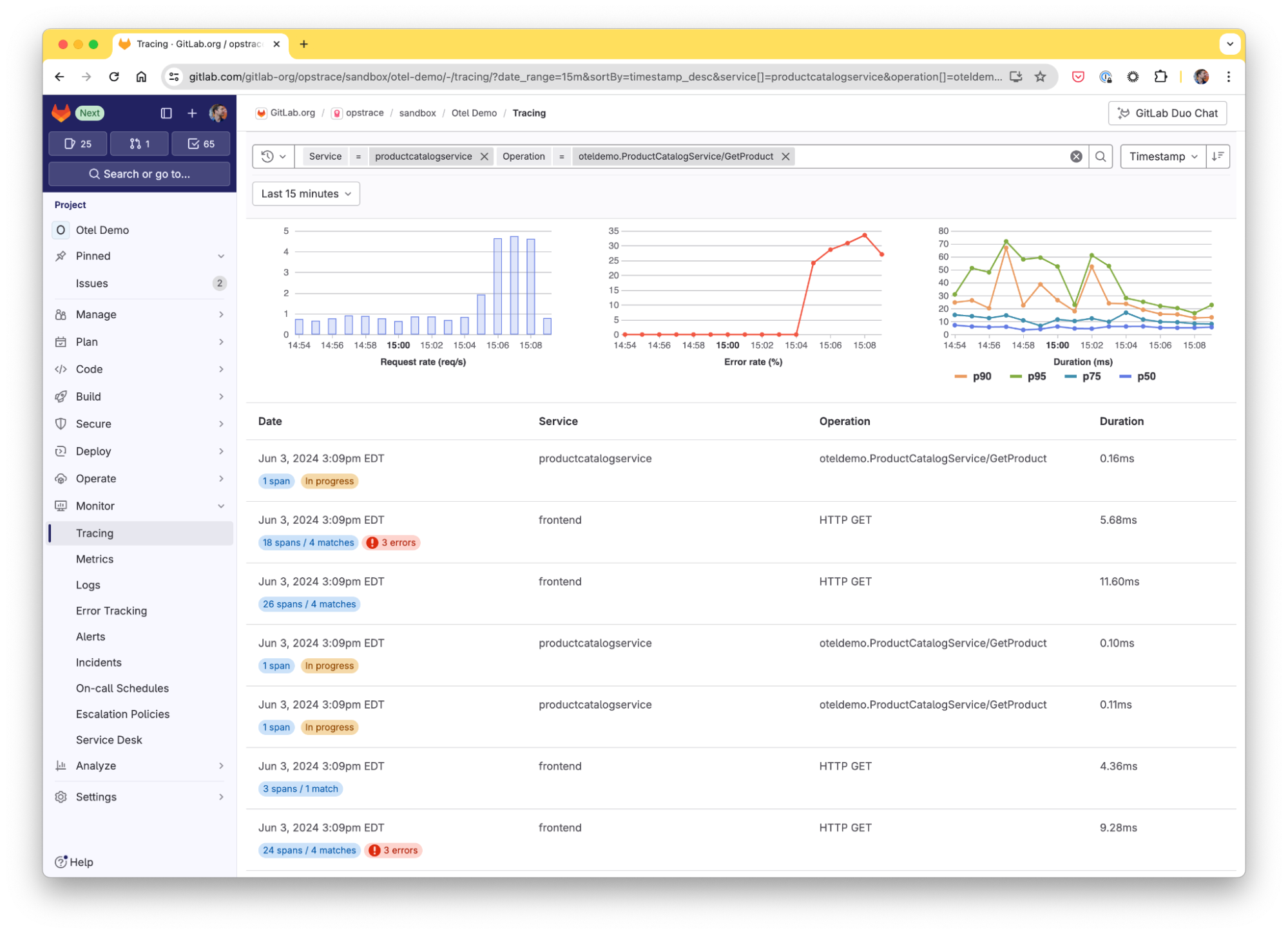
Traces mühelos untersuchen und analysieren
Eine fortschrittliche Benutzeroberfläche auf nativer Ebene ist entscheidend für eine effektive Datenanalyse. Wir haben eine solche Schnittstelle von Grund auf entwickelt. Der Trace Explorer ermöglicht es den Nutzer(innen), Traces zu untersuchen und die Leistung ihrer Anwendung zu verstehen:
- Erweiterte Filterung: Filtere nach Diensten, Vorgangsnamen, Status und Zeitspanne. Die automatische Vervollständigung vereinfacht die Abfrage.
- Fehlerhervorhebung: Fehlerbereiche in den Suchergebnissen werden einfach erkannt.
- RED-Metriken: Visualisiere die Anforderungsrate, die Fehlerrate und die durchschnittliche Dauer in einem Zeitseriendiagramm für jede Suche in Echtzeit.
- Timeline-Ansicht: Einzelne Traces werden als Wasserfalldiagramm dargestellt. So erhältst du einen vollständigen Überblick über eine Anfrage, die über verschiedene Dienste und Vorgänge verteilt ist.
- Historische Daten: Nutzer(innen) können bis zu 30 Tage in die Vergangenheit zurückreichende Daten abfragen.
Wie wir bei GitLab das Distributed Tracing einsetzen
Dogfooding ist ein zentraler Wert und eine wichtige Praxis bei GitLab. Wir haben bereits frühere Versionen von Distributed Tracing für unsere technischen und betrieblichen Anforderungen verwendet. Hier sind ein paar Anwendungsbeispiele aus unseren Teams:
1. Beheben von Fehlern und Leistungsproblemen in GitLab Agent für Kubernetes
Die Environments-Gruppe hat Distributed Tracing verwendet, um Probleme mit dem GitLab Agent für Kubernetes zu beheben, z. B. Zeitüberschreitungen oder hohe Latenzzeiten. Die Ansichten „Trace List“ und „Trace Timeline“ bieten dem Team wertvolle Einsichten, mit denen sie derartige Probleme effizient lösen können. Diese Traces werden in den entsprechenden GitLab Issues geteilt und diskutiert, wo das Team dann gemeinsam an der Lösung arbeitet.
„Die Funktion Distributed Tracing ist von unschätzbarem Wert, wenn es darum geht, festzustellen, wo Latenzprobleme auftreten, sodass wir uns auf die eigentliche Ursache konzentrieren und diese schneller beheben können.“ - Mikhail, GitLab-Ingenieur
2. Optimierung der Dauer der GitLab-Build-Pipeline durch Ermittlung von Leistungsengpässen
Langsame Deployments von GitLab-Quellcode können sich erheblich auf die Produktivität des gesamten Unternehmens sowie auf unsere Rechenleistung auswirken. In unserem Haupt-Repository werden jeden Monat über 100.000 Pipelines ausgeführt. Wenn sich die Zeit für die Ausführung dieser Pipelines nur um eine Minute ändert, können dadurch mehr als 2.000 Stunden Arbeitszeit hinzukommen oder wegfallen. Das sind 87 zusätzliche Tage!
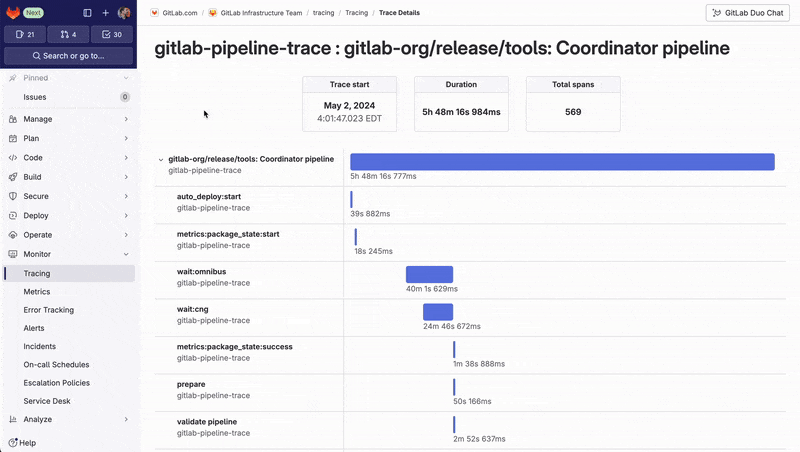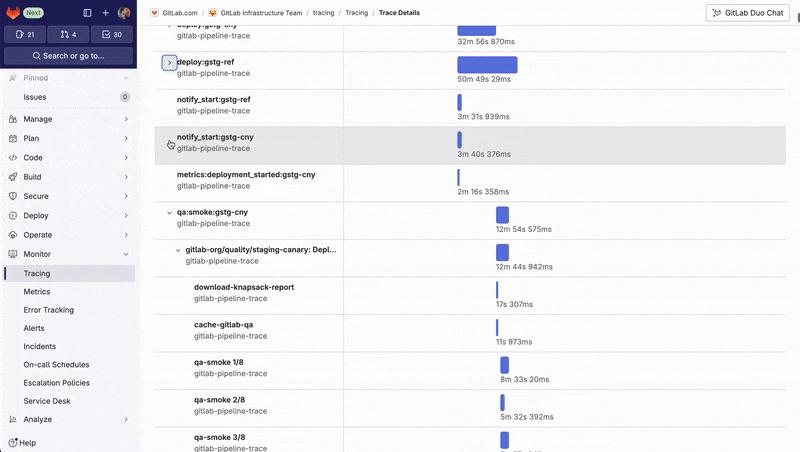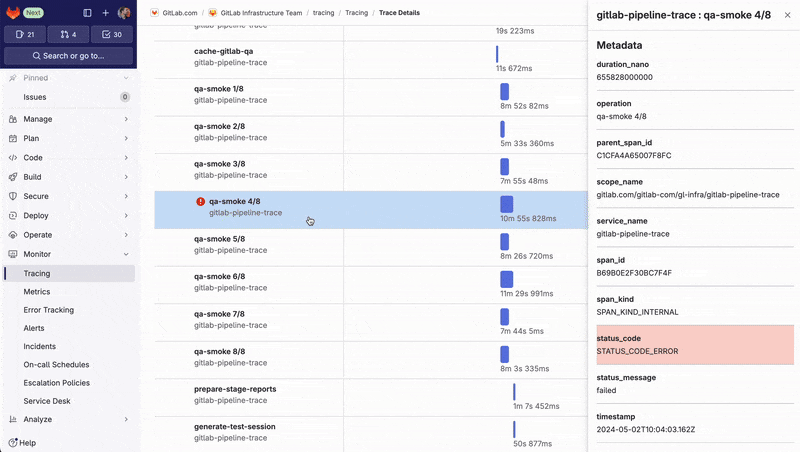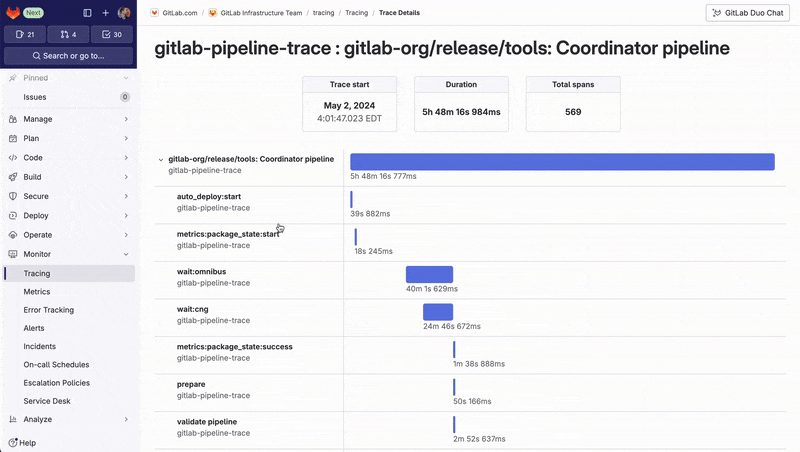
Um die Ausführungszeit von Pipelines zu optimieren, verwenden die Entwicklerteams der GitLab-Plattform ein speziell entwickeltes Tool, das GitLab-Deployment-Pipelines in Traces umwandelt.
Die Ansicht „Trace Timeline“ ermöglicht es den Teams, die detaillierte Ausführung komplexer Pipelines zu visualisieren und festzustellen, welche Aufträge Teil des kritischen Pfads sind und den gesamten Prozess verlangsamen. Durch die Identifizierung dieser Engpässe können sie die Auftragsausführung optimieren, indem sie z. B. dafür sorgen, dass der Auftrag schneller fehlschlägt oder mehr Aufträge parallel ausgeführt werden, um die Gesamteffizienz der Pipeline zu verbessern.
Das Skript ist frei verfügbar, sodass du es für deine eigenen Pipelines anpassen kannst.
„Der Einsatz von Distributed Tracing für unsere Deployment-Pipelines war ein echter Durchbruch. Es hat uns geholfen, Engpässe schnell zu erkennen und zu beseitigen, was unsere Bereitstellungszeiten erheblich verkürzt hat“ - Reuben, GitLab Engineer
Was kommt als Nächstes?
In den nächsten Monaten werden wir unsere Beobachtbarkeits- und Monitoring-Funktionen mit den kommenden Versionen Metrics und Logging weiter ausbauen. Weitere Informationen findest du auf unserer Seite zu GitLabObservability.
Nimm an der privaten Beta teil
Möchtest du Teil dieser aufregenden Entwicklung sein? Melde dich für die private Beta-Version an und probiere unsere Funktionen aus. Mit deinem Beitrag kannst du die Zukunft der Beobachtbarkeit in GitLab mitgestalten und sicherstellen, dass unsere Tools perfekt auf deine Bedürfnisse und Herausforderungen abgestimmt sind.
Feedback erwünscht
Dieser Blogbeitrag hat gefallen oder es gibt Fragen oder Feedback? Ein neues Diskussionsthema im GitLab-Community-Forum erstellen und Eindrücke austauschen.
Feedback teilen