
20年以上前に新しいプログラミング言語を学び始めたとき、私たちは6枚のCD-ROMからインストールしたVisual Studio 6のMSDNライブラリにアクセスしていました。ペンと紙でアルゴリズムを記録し、設計パターンの本を読み漁り、MSDNで正しい型を調べていましたが、こうした作業に時間がかかることが多々ありました。しかし、リモートコラボレーションや人工知能(AI)の時代が到来し、プログラミング言語の学び方は根本的に変わりました。今ではリモート開発環境をすばやく立ち上げて画面を共有し、グループでのプログラミングセッションを行えるようになりました。GitLab Duoのコード提案を使用すれば、AIというインテリジェントなパートナーにいつでも頼ることができます。コード提案機能は、ユーザーのプログラミングのスタイルと経験に基づいて学習します。この機能は、インプットとコンテキストさえあれば、最も効率的な提案を提供してくれるのです。
このチュートリアルでは、入門編のブログ記事(英語)からさらに一歩踏み込み、シンプルなフィードリーダーアプリケーションの設計と作成に取り組みます。
- 準備
- コード提案
- Rustの学習の継続
- 「Hello, Reader!」アプリ
- プロジェクトの初期化
- RSSフィードURLの定義
- モジュール
- main() 関数によるモジュール関数の呼び出し
- クレート
- feed-rs:XMLフィードの解析
- ランタイム設定:プログラム引数
- ユーザー入力のエラーハンドリング
- 永続性とデータ保存
- 最適化
- 非同期実行
- スレッドの生成
- 関数スコープ、スレッド、クロージャ
- フィードのXMLの解析およびオブジェクト型への変換
- 汎用的なフィードデータ型のマッピング
- Option::unwrap()によるエラーハンドリング
- ベンチマーク
- 逐次実行と並列実行のベンチマークの比較
- Rustのキャッシュを使用したCI/CD
- 次のステップ
- 非同期学習の演習
- フィードバックの共有
準備
ソースコードを参照する前に、VS CodeとRustの開発環境をセットアップしてください。
コード提案
実際に提案機能を検証する前に、まずはこの機能の使い方を理解しましょう。GitLab Duoのコード提案は、特定のキーボードショートカットを必要とせず、キーを入力するだけで使用できます。たとえば、コード提案を受け入れるには、Tab キーを押します。また、新しく作成したコードの方が、既存のコードをリファクタリングしたものよりもエラー発生率が低くなる点も覚えておきましょう。AIは非決定的であるため、一度削除したコード提案は再び同じ形で提示されない可能性があります。コード提案は現在ベータ版であり、GitLabは、同機能が生成するコンテンツの全体的な精度向上に取り組んでいます。
ヒント:コード提案の最新リリースでは、複数行の指示文に対応しています。ニーズに合わせて指示文を調整することで、よりよい提案を得ることができます。
// Create a function that iterates over the source array
// and fetches the data using HTTP from the RSS feed items.
// Store the results in a new hash map.
// Print the hash map to the terminal.
VS Code拡張機能のオーバーレイは、提案を提示する際に表示されます。提案された行を受け入れるには Tab キーを使用し、一単語だけ受け入れるには Cmd + 右カーソル キーを使用します。さらに、三点リーダーメニューからツールバーを常に表示するオプションを選択することも可能です。

Rustの学習の継続
では、引き続きRustについて学んでいきましょう。Rustはコード提案でサポートされている言語のひとつです。Rust by Example(英語)では、初心者に最適なチュートリアルが提供されており、公式のRust Book(英語)を確認しながら進めると効果的です。どちらのリソースもこのブログの執筆の際に参考にしています。
「Hello, Reader!」アプリ
アプリケーションの作成やRustの学習には、さまざまなアプローチがあります。その中には、既存のRustライブラリ、いわゆる Crates を利用するものがあり、このブログ記事の後半でも使用します。たとえば、画像を処理して、その結果をファイルに書き込むコマンドラインアプリを作成することができます。また、昔ながらの迷路をクリアしたり、数独を解いたりするアプリケーションを作成するのも楽しいでしょうし、ゲーム開発を行うこともできます。たとえば、Hands-on Rust(英語)というガイドブックでは、ダンジョンクローラー(迷宮探検)ゲームを作りながら、Rustを体系的に学習できるコースを提供しています。筆者の同僚であるFatima Sarah Khalidは、AIを活用してC++でDragon Realmの制作(英語)を始めたそうです。ぜひそちらもご覧ください。
ここで、実際の問題を解決するのに役立つ実用的なユースケースをひとつご紹介します。それは、異なるソースから重要な情報をRSSフィードに集約するというものです。RSSフィードには、セキュリティリリース、ブログ記事、およびソーシャルディスカッションフォーラム(Hacker Newsなど)の最新情報が含まれます。アップデートに含まれる特定のキーワードやバージョンを絞り込んで検索したいと考えることがよくあります。こうしたニーズを基に、アプリケーションの要件をリスト化できます。具体的には、次のような要件です。
- HTTPウェブサイト、REST API、RSSフィードなどの異なるソースからデータをフェッチ(取得)する(最初の段階ではRSSフィードを使用)。
- データを解析する。
- データをユーザーに提示する、またはディスクに書き込む。
- パフォーマンスを最適化する。
このブログ記事の学習ステップを完了すると、以下のサンプルアプリケーションの出力が得られます。

アプリケーションはモジュール化されている必要があり、また、将来的にデータ型やフィルター、アクションをトリガーするフックを追加できる基盤も整えておく必要があります。
プロジェクトの初期化
リマインダー:cargo init をプロジェクトのルートディレクトリで実行すると、 main () エントリポイントを含んだファイル構造が作成されます。これを踏まえ、次のステップでは、Rustのモジュールの作成と使用方法を学びます。
learn-rust-ai-app-reader という名前のディレクトリを新規作成し、そのディレクトリに移動したら、cargo init を実行します。このコマンドは、暗黙的に git init を実行し、新しいGitリポジトリをローカルで初期化します。残りのステップでは、Gitリモートリポジトリのパスを設定していきます。たとえば、https://gitlab.com/gitlab-de/use-cases/ai/learn-with-ai/learn-rust-ai-app-reader のように設定します(ご自身のネームスペースに合わせてパスを置き換えてください)。Gitリポジトリをプッシュすると、GitLabで新しいプロジェクトが自動的に作成されます。
mkdir learn-rust-ai-app-reader
cd learn-rust-ai-app-reader
cargo init
git remote add origin https://gitlab.com/gitlab-de/use-cases/ai/learn-with-ai/learn-rust-ai-app-reader.git
git push --set-upstream origin main
新しく作成されたディレクトリからVS Codeを開きます。code コマンドラインインターフェース(CLI)によって、macOS上で新しいVS Codeのウィンドウが起動します。
code .
RSSフィードURLの定義
新しいHashMapを追加して、src/main.rs ファイル内の main() 関数にRSSフィードのURLを保存します。複数行の指示コメントを入力することで、GitLab Duoのコード提案に対し、HashMap オブジェクトを作成して、Hacker NewsやTechCrunchのデフォルト値で初期化するよう指示できます。注:提案に含まれるURLが正しいことを確認してください。
fn main() {##$_0A$## // Define RSS feed URLs in the variable rss_feeds##$_0A$## // Use a HashMap##$_0A$## // Add Hacker News and TechCrunch##$_0A$## // Ensure to use String as type##$_0A$####$_0A$##}
コードコメントでは以下の点を指示しています。
- 変数名
rss_feeds HashMapタイプ-
- 初期のseedキー/バリューペア
- String 型(
to_string ()呼び出しで確認可能)
考えられるコードの例は次の通りです。
use std::collections::HashMap;
fn main() {##$_0A$## // Define RSS feed URLs in the variable rss_feeds##$_0A$## // Use a HashMap##$_0A$## // Add Hacker News and TechCrunch##$_0A$## // Ensure to use String as type##$_0A$## let rss_feeds = HashMap::from([##$_0A$## ("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),##$_0A$## ("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),##$_0A$## ]);##$_0A$####$_0A$##}

VS Codeで新しいターミナルを開き(cmd + shift + p で terminal を検索)、cargo build を実行して変更をビルドします。エラーメッセージが表示され、use std::collections::HashMap; のインポートを追加するよう指示されます。
次のステップでは、RSSフィードのURLを使用して操作を行います。以前のブログ記事(英語)では、コードを関数に分割する方法を解説しました。今回は、リーダーアプリケーションのコードをよりモジュール化して整理し、Rustのモジュールを使用します。
モジュール
モジュールは、 コードの整理に役立ちます。また、関数をモジュールのスコープ内に隠し、main()スコープからのアクセスを制限することも可能です。リーダーアプリケーションでは、RSSフィードのコンテンツを取得し、XMLレスポンスを解析したいため、main() からは、get_feeds() 関数のみにアクセスできるようにし、それ以外の機能はモジュール内のみで使用できるように制限します。
src/ ディレクトリに feed_reader.rs という名前の新しいファイルを作成します。コード提案に、feed_reader という名前の公開モジュールと、String HashMapをインプットとして受け取る get_feeds() という公開関数を作成するよう指示します。重要:Rustのモジュール構造に従って、ファイル名とモジュール名を同じにする必要があります。

コード提案に入力変数名と型を指定すると、必要な std::collections::HashMap モジュールが自動的にインポートされます。ヒント:最適な結果を得られるよう、コメントを使って変数の型を調整してみましょう。また、Rustでは関数のパラメータをオブジェクト参照として渡すのがベストプラクティスとされています。以下に例を示します。
// Create public module feed_reader
// Define get_feeds() function which takes rss_feeds as String HashMap reference as input
pub mod feed_reader {##$_0A$## use std::collections::HashMap;##$_0A$####$_0A$## pub fn get_feeds(rss_feeds: &HashMap<String, String>) {##$_0A$## // Do something with the RSS feeds##$_0A$## }##$_0A$##}
関数内では、コード提案に以下の手順を指示します。
// Iterate over the RSS feed URLs(RSSフィードURLを反復処理する)// Fetch URL content(URLコンテンツを取得する)// Parse XML body(XMLの本文を解析する)// Print the result(結果を出力する)




次のコードが提案されます。
// Create public module feed_reader
// Define get_feeds() function which takes rss_feeds as String HashMap reference as input
pub mod feed_reader {##$_0A$## use std::collections::HashMap;##$_0A$####$_0A$## pub fn get_feeds(rss_feeds: &HashMap<String, String>) {##$_0A$## // Iterate over the RSS feed URLs##$_0A$## for (name, url) in rss_feeds {##$_0A$## println!("{}: {}", name, url);##$_0A$####$_0A$## // Fetch URL content##$_0A$## let body = reqwest::blocking::get(url).unwrap().text().unwrap();##$_0A$####$_0A$## // Parse XML body##$_0A$## let parsed_body = roxmltree::Document::parse(&body).unwrap();##$_0A$####$_0A$## // Print the result##$_0A$## println!("{:#?}", parsed_body);##$_0A$## }##$_0A$## }##$_0A$##}
ここで新しいキーワード unwrap()が登場します。Rustは null 値をサポートしておらず、すべての値に対して Option 型を使用します。たとえば、Text や String といった特定のラップされた型を使用することが確定している場合、unwrap() メソッドを呼び出してその値を取得できます。ただし、値が None の場合、unwrap() メソッドはパニックを起こします。
注意:コード提案は、// Fetch URL content のコメント指示に従って、reqwest::blocking::get 関数を参照します。reqwestというクレーと名は意図的なものであり、タイポではありません。非同期リクエストとブロッキングリクエストの処理に役立つ、優れた利便性と高レベルのHTTPクライアントの機能を提供します。
XMLの本文の解析は難しく、異なる結果が得られることがあります。また、スキーマはRSSフィードURLごとに異なる可能性があります。まずは get_feeds() 関数を呼び出し、その後でコードの改善に取り組みましょう。
main() 関数によるモジュール関数の呼び出し
現在、main() 関数は get_feeds() 関数を認識していないため、まずそのモジュールをインポートする必要があります。他のプログラミング言語では include や import といったキーワードを目にすることがありますが、Rustのモジュールシステムは異なります。
モジュールはパスディレクトリに整理されます。今回の例では、両方のソースファイルが同じディレクトリレベルに存在しています。feed_reader.rs はクレートとして解釈され、その中に feed_reader というモジュールがあり、そのモジュールが get_feeds() 関数を定義しています。
src/
main.rs
feed_reader.rs
feed_reader.rs ファイルの get_feeds() 関数にアクセスするためには、まず main.rs のスコープにモジュールパスを取り込み、その後フルパスで関数を呼び出します。
mod feed_reader;
fn main() {
feed_reader::feed_reader::get_feeds(&rss_feeds);
あるいは、use キーワードを使って関数のフルパスをインポートし、その後短い関数名で呼び出すこともできます。
mod feed_reader;
use feed_reader::feed_reader::get_feeds;
fn main() {
get_feeds(&rss_feeds);
ヒント:Rustのモジュールシステムを視覚的によりよく理解するために、Rustモジュールシステムについてわかりやすく説明したブログ記事(英語)をお読みください。
fn main() {
// ...
// Print feed_reader get_feeds() output
println!("{}", feed_reader::get_feeds(&rss_feeds));
use std::collections::HashMap;
mod feed_reader;
// Alternative: Import full function path
//use feed_reader::feed_reader::get_feeds;
fn main() {##$_0A$## // Define RSS feed URLs in the variable rss_feeds##$_0A$## // Use a HashMap##$_0A$## // Add Hacker News and TechCrunch##$_0A$## // Ensure to use String as type##$_0A$## let rss_feeds = HashMap::from([##$_0A$## ("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),##$_0A$## ("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),##$_0A$## ]);##$_0A$####$_0A$## // Call get_feeds() from feed_reader module##$_0A$## feed_reader::feed_reader::get_feeds(&rss_feeds);##$_0A$## // Alternative: Imported full path, use short path here.##$_0A$## //get_feeds(&rss_feeds);##$_0A$##}
ターミナルで cargo build を再実行しコードをビルドします。
cargo build
以下は、HTTPリクエストやXML解析に関する一般的なコードを参照した際に発生する可能性のあるビルドエラーの例です。
- エラー:
could not find blocking in reqwest解決策:Config.tomlファイルでreqwestクレートのblocking機能を有効にします(reqwest = { version = "0.11.20", features = ["blocking"] }) - エラー:
failed to resolve: use of undeclared crate or module reqwest解決策:reqwestクレートを追加します - エラー:
failed to resolve: use of undeclared crate or module roxmltree解決策:roxmltreeクレートを追加します
vim Config.toml
reqwest = { version = "0.11.20", features = ["blocking"] }
cargo add reqwest
cargo add roxmltree
ヒント:エラーメッセージの文字列を Rust <error message> としてブラウザで検索し、欠落しているクレートが利用可能であるかどうか確認しましょう。通常、検索結果に「crates.io」が表示され、そこから不足している依存関係を追加できます。
ビルドが成功したら、cargo run でコードを実行し、Hacker NewsのRSSフィードの出力を確認します。

XML本文を人間が読める形式に解析するにはどうすればいいでしょうか?次のセクションでは、既存の解決策とRustのクレートがどのように機能するかを説明します。
クレート
RSSフィードは共通のプロトコルと仕様に基づいており、XMLを解析して下位のオブジェクト構造を理解するのは、例えば車輪のように、すでに存在しているものを再び深く掘り下げて再発明するかのようです。。こういったタスクに対するおすすめのアプローチは、過去に同じ問題に直面した人がいないか、また、その問題を解決するためのコードがすでに作られていないかを調べることです。
Rustでの再利用可能なライブラリコードは Cratesと呼ばれる単位で整理され、パッケージで提供されます。これらはcrates.ioのパッケージレジストリで利用可能です。これらの依存関係をプロジェクトに追加するには、Config.toml ファイルの [dependencies] セクションを編集するか、cargo add <name> コマンドを使用します。
リーダーアプリケーションでは、feed-rs クレートを使用したいため、新しいターミナルを開き、次のコマンドを実行してください。
cargo add feed-rs

feed-rs:XMLフィードの解析
src/feed_reader.rs に移動し、XML本文を解析する部分に対して修正を加えます。コード提案は、feed-rs クレートの parser::parse 関数をどのように呼び出すか理解していますが、ひとつだけ特別な点があります。feed-rs は文字列をrawバイトとして入力し、自らエンコーディングを判断します。ただし、コメントに指示を追加することで、期待の結果を得ることは可能です。
// Parse XML body with feed_rs parser, input in bytes
let parsed_body = feed_rs::parser::parse(body.as_bytes()).unwrap();

feed-rs を使用するメリットは即座に可視化できるものでなく、cargo run で出力を確認するとその効果が明らかになります。すべてのキーと値がそれぞれのRustオブジェクト型にマッピングされ、さらに高度な処理に利用できるようになります。

ランタイム設定:プログラム引数
ここまで、コンパイル時にバイナリに埋め込まれ、ハードコードされたRSSフィードの値を使用してプログラムを実行してきました。次のステップでは、実行時にRSSフィードを設定できるようにします。
Rustでは、標準miscライブラリにプログラム引数を処理するための機能が用意されています。プログラム引数を解析することで、高度なプログラム引数パーサー(たとえばclapクレート)を使用したり、プログラムパラメータを構成ファイルやフォーマット(TOMLやYAML)に移したりするよりも、簡単かつ効率的に学習を進めることができます。実際にいくつかの方法を試した結果、学習効果を最大限に高めるには、この方法が最適であると判断しましたが、唯一の方法ではありません。他の方法でRSSフィードの設定を試してみる価値もあります。
単純な解決策としては、コマンドパラメータを "name,url" の文字列ペアとして渡してから、, で分割して名前とURLの値を抽出します。コード提案に、これらの操作を実行して新しい値で rss_feeds ハッシュマップを拡張するようコメントで指示します。変数が変更可能でない可能性があるため、let rss_feeds を let mut rss_feeds に変更する必要がある点にご注意ください。
src/main.rs に移動し、rss_feeds 変数の後に次のコードを main() 関数の追加します。まずはコメントでプログラム引数を定義し、提案されたコードスニペットを確認します。
// Program args, format "name,url"
// Split value by , into name, url and add to rss_feeds

コード全体の例は次のようになります。
fn main() {##$_0A$## // Define RSS feed URLs in the variable rss_feeds##$_0A$## // Use a HashMap##$_0A$## // Add Hacker News and TechCrunch##$_0A$## // Ensure to use String as type##$_0A$## let mut rss_feeds = HashMap::from([##$_0A$## ("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),##$_0A$## ("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),##$_0A$## ]);##$_0A$####$_0A$## // Program args, format "name,url"##$_0A$## // Split value by , into name, url and add to rss_feeds##$_0A$## for arg in std::env::args().skip(1) {##$_0A$## let mut split = arg.split(",");##$_0A$## let name = split.next().unwrap();##$_0A$## let url = split.next().unwrap();##$_0A$## rss_feeds.insert(name.to_string(), url.to_string());##$_0A$## }##$_0A$####$_0A$## // Call get_feeds() from feed_reader module##$_0A$## feed_reader::feed_reader::get_feeds(&rss_feeds);##$_0A$## // Alternative: Imported full path, use short path here.##$_0A$## //get_feeds(&rss_feeds);##$_0A$##}
プログラムの引数を cargo run コマンドに直接渡すことができます。その際は引数の前に --をつけます。 すべての引数をダブルクォートで囲み、名前の後にカンマを付けてRSSフィードのURLを引数として渡します。引数は空白で区切ります。
cargo build
cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"

ユーザー入力のエラーハンドリング
提供されたユーザー入力がプログラムで想定される内容と異なる場合、エラーを発生させ、呼び出し元がプログラム引数を修正できるようにする必要があります。たとえば、不正なURL形式が渡された場合、それをランタイムエラーとして処理する必要があります。コード提案に対し、URLが無効な場合はエラーをスローするようコメントで指示します。
// Ensure that URL contains a valid format, otherwise throw an error
ひとつの解決策として、url 変数が http:// または https:// で始まっているかを確認し、そうでなければ panic! マクロを使ってエラーをスローする方法があります。コード全体の例は次のようになります。
// Program args, format "name,url"
// Split value by , into name, url and add to rss_feeds
for arg in std::env::args().skip(1) {
let mut split = arg.split(",");
let name = split.next().unwrap();
let url = split.next().unwrap();
// Ensure that URL contains a valid format, otherwise throw an error
if !url.starts_with("http://") && !url.starts_with("https://") {
panic!("Invalid URL format: {}", url);
}
rss_feeds.insert(name.to_string(), url.to_string());
}
任意のURL文字列から : を削除してエラーハンドリングをテストします。RUST_BACKTRACE=full 環境変数を追加すると、panic() 呼び出しが発生した際に詳細な出力を取得できます。
RUST_BACKTRACE=full cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https//www.cncf.io/feed/"

永続性とデータ保存
フィードデータを保存する単純な解決策は、解析されたデータを新しいファイルに書き出すことです。コード提案に、RSSフィードの名前と現在のISO日付を含むパターンでファイルを保存するよう指示します。
// Parse XML body with feed_rs parser, input in bytes
let parsed_body = feed_rs::parser::parse(body.as_bytes()).unwrap();
// Print the result
println!("{:#?}", parsed_body);
// Dump the parsed body to a file, as name-current-iso-date.xml
let now = chrono::offset::Local::now();
let filename = format!("{}-{}.xml", name, now.format("%Y-%m-%d"));
let mut file = std::fs::File::create(filename).unwrap();
file.write_all(body.as_bytes()).unwrap();
この処理の一例として、chronoクレートを使用する方法があります。cargo add chrono を実行して追加し、その後 cargo build と cargo run を再度実行します。
ファイルは cargo run が実行されたディレクトリに保存されます。バイナリを target/debug/ ディレクトリで直接実行している場合、すべてのファイルはそのディレクトリにダンプされます。

最適化
rss_feeds 変数内のエントリは逐次実行されています。もし100件以上のURLがリストに設定されている場合、データの取得と処理にはかなりの時間がかかるでしょう。複数のフェッチリクエストを並行して実行できたらどうでしょうか?
非同期実行
Rustでは、スレッドを使用した非同期実行が可能です。
最も簡単な解決策は、各RSSフィードURLごとにスレッドを生成することです。最適化戦略については後のセクションで説明します。並行実行を開始する前に、 time コマンドの前にcargo run をつけて、逐次実行コードの実行時間を測定しましょう。
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.21s user 0.08s system 10% cpu 2.898 total
なお、この演習では、手動のコーディング作業が多くなる場合があります。並列実行の影響をより効果的に比較するには、逐次実行の動作状態を新しいGitコミットとブランチ sequential-exec に保存してください。
git commit -avm "Sequential execution working"
git checkout -b sequential-exec
git push -u origin sequential-exec
git checkout main
スレッドの生成
src/feed_reader.rs を開き、get_feeds() 関数をリファクタリングします。まず、現在の状態をGitコミットで保存し、その後、関数のスコープ内の内容を削除します。次に、コード提案への指示と以下のコードコメントを入力します。
// Store threads in vector:スレッドのハンドルをベクターに格納し、関数呼び出しの最後にスレッドが終了するまで待機できるようにします。// Loop over rss_feeds and spawn threads:すべてのRSSフィードを反復処理するためのコードを作成し、新しいスレッドを作成します。
thread モジュールと time モジュールを扱うには、次の use 文を追加します。
use std::thread;
use std::time::Duration;
その後、forループを閉じるまでコードを書き進めます。コード提案は、自動的にスレッドハンドルを threads ベクター変数に追加し、関数の最後でスレッドを結合(join)するよう提案します。
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Store threads in vector
let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();
// Loop over rss_feeds and spawn threads
for (name, url) in rss_feeds {
let thread_name = name.clone();
let thread_url = url.clone();
let thread = thread::spawn(move || {
});
threads.push(thread);
}
// Join threads
for thread in threads {
thread.join().unwrap();
}
}
次に、thread クレートを追加し、もう一度コードをビルドし実行します。
cargo add thread
cargo build
cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
この段階では、データの処理や出力は行われていません。次のステップに移る前に、ここで新たに導入されたキーワードについて解説します。
関数スコープ、スレッド、クロージャ
提案されるコードには新しいキーワードやデザインパターンが含まれることもあるため、これらについて理解しておくことが重要になります。スレッドハンドルは thread::JoinHandle という型で、スレッドが終わるのを待機するために使用します(join()メソッドを使います)。
thread::spawn() は新しいスレッドを生成し、このスレッド内では、関数オブジェクトを渡すことができます。この場合、クロージャ式が無名関数として渡されます。また、クロージャ入力は || 構文を使用して渡されますが、この際にはmove クロージャが関数スコープの変数をスレッドスコープに移動します。これにより、どの変数を新しい関数やクロージャスコープに渡すかを手動で指定する必要がなくなります。
ただし、これには制限があります。rss_feeds は参照 & で、get_feeds() 関数の呼び出し元からパラメータとして渡されています。この変数は関数スコープ内でのみ有効です。このエラーを引き起こすには、次のコードスニペットを使用します。
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {##$_0A$####$_0A$## // Store threads in vector##$_0A$## let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();##$_0A$####$_0A$## // Loop over rss_feeds and spawn threads##$_0A$## for (key, value) in rss_feeds {##$_0A$## let thread = thread::spawn(move || {##$_0A$## println!("{}", key);##$_0A$## });##$_0A$## }##$_0A$##}

key 変数は関数スコープ内で作成されていますが、rss_feeds 変数を参照しているため、スレッドスコープに移動することはできません。関数パラメータ rss_feeds のハッシュマップからアクセスされる値は、clone() を使ってローカルコピーを作成する必要があります。

pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Store threads in vector
let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();
// Loop over rss_feeds and spawn threads
for (name, url) in rss_feeds {
let thread_name = name.clone();
let thread_url = url.clone();
let thread = thread::spawn(move || {
// Use thread_name and thread_url as values, see next chapter for instructions.
フィードのXMLの解析およびオブジェクト型への変換
次のステップは、スレッド内のクロージャでRSSフィードの解析手順を繰り返すことです。コード提案の指示とともに以下のコードコメントを追加します。
// Parse XML body with feed_rs parser, input in bytes:コード提案に対し、RSSフィードのURLコンテンツを取得し、feed_rsクレートの関数で解析したいという要望を伝えます。// Check feed_type attribute feed_rs::model::FeedType::RSS2 or Atom and print its name:feed_type属性をfeed_rs::model::FeedTypeと照合してフィードの種類を抽出します。この場合、コード提案に対して、照合の対象とする正確なEnum値を指示する必要があります。
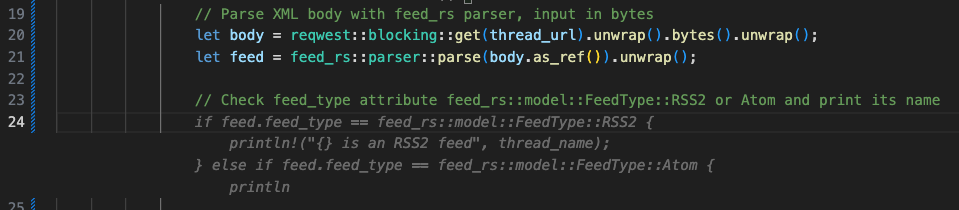
// Parse XML body with feed_rs parser, input in bytes
let body = reqwest::blocking::get(thread_url).unwrap().bytes().unwrap();
let feed = feed_rs::parser::parse(body.as_ref()).unwrap();
// Check feed_type attribute feed_rs::model::FeedType::RSS2 or Atom and print its name
if feed.feed_type == feed_rs::model::FeedType::RSS2 {
println!("{} is an RSS2 feed", thread_name);
} else if feed.feed_type == feed_rs::model::FeedType::Atom {
println!("{} is an Atom feed", thread_name);
}
プログラムをもう一度ビルドして実行し、出力を確認します。
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
CNCF is an RSS2 feed
TechCrunch is an RSS2 feed
GitLab Blog is an Atom feed
Hacker News is an RSS2 feed
フィードURLをブラウザで開くか、以前にダウンロードしたファイルを調べて、この出力を確認します。
Hacker News はRSS 2.0をサポートしており、channel(title,link,description,item(title,link,pubDate,comments)) の構造を持っています。TechCrunchとCNCFブログは同様の構造をしています。
<rss version="2.0"><channel><title>Hacker News</title><link>https://news.ycombinator.com/</link><description>Links for the intellectually curious, ranked by readers.</description><item><title>Writing a debugger from scratch: Breakpoints</title><link>https://www.timdbg.com/posts/writing-a-debugger-from-scratch-part-5/</link><pubDate>Wed, 27 Sep 2023 06:31:25 +0000</pubDate><comments>https://news.ycombinator.com/item?id=37670938</comments><description><![CDATA[<a href="https://news.ycombinator.com/item?id=37670938">Comments</a>]]></description></item><item>
GitLabブログにはAtomフィード形式が使用されています。RSSに類似していますが異なる解析ロジックが必要です。
<?xml version='1.0' encoding='utf-8' ?>
<feed xmlns='http://www.w3.org/2005/Atom'>
<!-- / Get release posts -->
<!-- / Get blog posts -->
<title>GitLab</title>
<id>https://about.gitlab.com/blog</id>
<link href='https://about.gitlab.com/blog/' />
<updated>2023-09-26T00:00:00+00:00</updated>
<author>
<name>The GitLab Team</name>
</author>
<entry>
<title>Atlassian Server ending: Goodbye disjointed toolchain, hello DevSecOps platform</title>
<link href='https://about.gitlab.com/blog/2023/09/26/atlassian-server-ending-move-to-a-single-devsecops-platform/' rel='alternate' />
<id>https://about.gitlab.com/blog/2023/09/26/atlassian-server-ending-move-to-a-single-devsecops-platform/</id>
<published>2023-09-26T00:00:00+00:00</published>
<updated>2023-09-26T00:00:00+00:00</updated>
<author>
<name>Dave Steer, Justin Farris</name>
</author>
汎用的なフィードデータ型のマッピング
roxmltree::Document::parse を使用する場合、XMLノードツリーとその特定のタグ名を理解する必要があります。幸い、feed_rs::model::Feed はRSSとAtomフィードの統合モデルを提供しているため、引き続き feed_rs クレートを使用して進めましょう。
- Atom:Feed->Feed、Entry->Entry
- RSS:Channel->Feed、Item->Entry
上記のマッピングに加えて、必要な属性を抽出し、それらのデータ型をマッピングする必要があります。feed_rs::modelのドキュメントを開き、構造体やそのフィールド、実装について理解しながら進めることをお勧めします。これは、feed_rs の実装に特有の型変換エラーやコンパイルエラーが発生するのを防ぐためです。
Feed 構造体は title を提供しますが、その型は Option<Text> で、値が設定されているか、何もないかのいずれかです。Entry 構造体は以下の情報を提供します。
title:Option<Text>型で、TextにはcontentフィールドがString型として含まれています。published:Option<DateTime<Utc>>型で、DateTimeはformat()メソッドを持ちます。summary:Option<Text>型で、TextにはcontentフィールドがString型として含まれています。links:Vec<Link>型で、Link項目のベクターです。href属性が生のURL文字列を提供します。
1から4に従って、フィードエントリから必要なデータを抽出します。繰り返しますが、すべての Option 型には unwrap() を呼び出す必要があります。このため、コード提案に対してより直接的な指示が求められます。
// https://docs.rs/feed-rs/latest/feed_rs/model/struct.Feed.html
// https://docs.rs/feed-rs/latest/feed_rs/model/struct.Entry.html
// Loop over all entries, and print
// title.unwrap().content
// published.unwrap().format
// summary.unwrap().content
// links href as joined string
for entry in feed.entries {
println!("Title: {}", entry.title.unwrap().content);
println!("Published: {}", entry.published.unwrap().format("%Y-%m-%d %H:%M:%S"));
println!("Summary: {}", entry.summary.unwrap().content);
println!("Links: {:?}", entry.links.iter().map(|link| link.href.clone()).collect::<Vec<String>>().join(", "));
println!();
}

Option::unwrap()によるエラーハンドリング
プログラムを再ビルドして実行した後、複数行の指示を引き続き処理します。補足:unwrap() は空の値に遭遇すると panic! マクロを呼び出し、プログラムを強制終了させます。これは、フィードデータ内に summary のようなフィールドが設定されていない場合に発生します。
GitLab Blog is an Atom feed
Title: How the Colmena project uses GitLab to support citizen journalists
Published: 2023-09-27 00:00:00
thread '<unnamed>' panicked at 'called `Option::unwrap()` on a `None` value', src/feed_reader.rs:40:59
解決策のひとつとして、std::Option::unwrap_or_else を使用し、デフォルト値として空の文字列を設定することが挙げられます。この構文には、空の Text 構造体のインスタンスを返すクロージャが必要です。
問題を解決する上で、正しい初期化方法を見つけるために試行錯誤を重ねました。単に空の文字列を渡すだけではカスタム型ではうまく機能しませんでした。以下に、筆者が試したすべてのアプローチとリサーチの過程をまとめました。
// Problem: The `summary` attribute is not always initialized. unwrap() will panic! then.
// Requires use mime; and use feed_rs::model::Text;
/*
// 1st attempt: Use unwrap() to extraxt Text from Option<Text> type.
println!("Summary: {}", entry.summary.unwrap().content);
// 2nd attempt. Learned about unwrap_or_else, passing an empty string.
println!("Summary: {}", entry.summary.unwrap_or_else(|| "").content);
// 3rd attempt. summary is of the Text type, pass a new struct instantiation.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{}).content);
// 4th attempt. Struct instantiation requires 3 field values.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{"", "", ""}).content);
// 5th attempt. Struct instantation with public fields requires key: value syntax
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: "", src: "", content: ""}).content);
// 6th attempt. Reviewed expected Text types in https://docs.rs/feed-rs/latest/feed_rs/model/struct.Text.html and created Mime and String objects
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: String::new(), content: String::new()}).content);
// 7th attempt: String and Option<String> cannot be casted automagically. Compiler suggested using `Option::Some()`.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(), content: String::new()}).content);
*/
// xth attempt: Solution. Option::Some() requires a new String object.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(String::new()), content: String::new()}).content);
このアプローチは、コードが複雑で読みにくく、さらにコード提案の支援がなかったため、手動でコーディングする必要があり、満足のいくものではありませんでした。一旦立ち止まり、アプローチを見直しました。Option が none の場合にunwrap() はエラーをスローするのであれば、そのエラーを処理する簡単な方法があるのではと考え、コード提案に新しいコメントで質問しました。
// xth attempt: Solution. Option::Some() requires a new String object.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(String::new()), content: String::new()}).content);
// Alternatively, use Option.is_none()
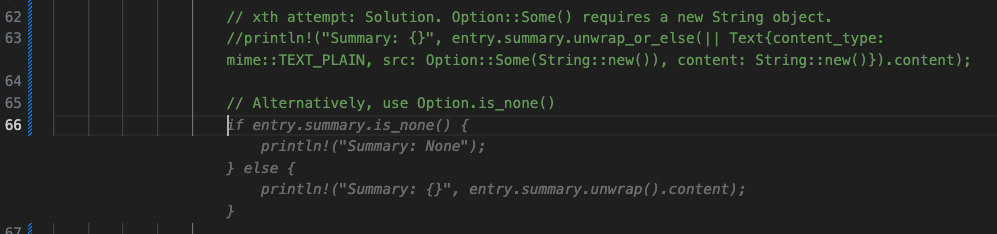
結果として、読みやすさが向上し、unwrap() による無駄なCPUサイクルが減りました。複雑な問題を解決することから単純な解決策を使用することまでの学習過程を大幅に短縮できました。まさにウィンウィンです。
忘れないうちに、XMLデータをディスクに保存する指示を再度追加して、リーダーアプリを完成させましょう。
// Dump the parsed body to a file, as name-current-iso-date.xml
let file_name = format!("{}-{}.xml", thread_name, chrono::Local::now().format("%Y-%m-%d-%H-%M-%S"));
let mut file = std::fs::File::create(file_name).unwrap();
file.write_all(body.as_ref()).unwrap();
プログラムをビルドして実行し、出力を確認します。
cargo build
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
ベンチマーク
逐次実行と並列実行のベンチマークの比較
それぞれ5つのサンプルを作成して、実行時間のベンチマークを比較します。
- 逐次実行
- 並列実行
# Sequential
git checkout sequential-exec
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.21s user 0.08s system 10% cpu 2.898 total
0.21s user 0.08s system 11% cpu 2.585 total
0.21s user 0.09s system 10% cpu 2.946 total
0.19s user 0.08s system 10% cpu 2.714 total
0.20s user 0.10s system 10% cpu 2.808 total
# Parallel
git checkout parallel-exec
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.19s user 0.08s system 17% cpu 1.515 total
0.18s user 0.08s system 16% cpu 1.561 total
0.18s user 0.07s system 17% cpu 1.414 total
0.19s user 0.08s system 18% cpu 1.447 total
0.17s user 0.08s system 16% cpu 1.453 total
4つのRSSフィードスレッドを並列実行した場合、CPU使用率は増加しましたが、逐次実行に比べて全体の実行時間はほぼ半減しました。この点を踏まえて、Rustの学習を続け、コードと機能を最適化していきます。
なお、ここではCargoを使ってデバッグビルドを実行しており、最適化されたリリースビルドはまだ実行していません。また、並列実行にはいくつか注意点があります。一部のHTTPエンドポイントはレート制限を設けており、並列処理がこの制限に引っかかりやすくなる可能性があります。
複数のスレッドを並列実行するシステムも過負荷になる可能性があります。これは、カーネル内でのコンテキストスイッチ(スレッド間の切り替え)を通じて各スレッドにリソースを割り当てる必要があるためです。1つのスレッドが計算リソースを使用している間、他のスレッドは待機状態になります。スレッドが多すぎると、システム全体が遅くなり、処理がスピードアップするどころか逆に遅くなることもあります。解決策としては、呼び出し元がキューにタスクを追加し、定義された数のワーカースレッドが非同期実行のためにタスクを処理するワークキューなどの設計パターンがあります。
Rustでは、スレッド間のデータ同期を行うチャンネルを利用することもできます。競合状態を防ぐために、セーフロックを提供するミューテックスも利用可能です。
Rustのキャッシュを使用したCI/CD
以下のCI/CD構成を .gitlab-ci.yml ファイルに追加します。この run-latest ジョブは cargo run をRSSフィードURLの例とともに呼び出し、実行時間を継続的に計測します。
stages:
- build
- test
- run
default:
image: rust:latest
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- .cargo/bin
- .cargo/registry/index
- .cargo/registry/cache
- target/debug/deps
- target/debug/build
policy: pull-push
# Cargo data needs to be in the project directory for being cached.
variables:
CARGO_HOME: ${CI_PROJECT_DIR}/.cargo
build-latest:
stage: build
script:
- cargo build --verbose
test-latest:
stage: build
script:
- cargo test --verbose
run-latest:
stage: run
script:
- time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"

次のステップ
このブログ記事の執筆は、筆者自身が高度なRustプログラミング技術を学びつつ、コード提案を使って最適な学習過程を見出すという点で難しいものでした。コード提案は、単なる定型的なコードだけでなく、ローカルコンテキストを理解し、記述されたコードが多いほどアルゴリズムの目的や範囲をよりよく把握した迅速なコード生成にも大いに役立ちます。このブログ記事を読むことで、全てではないにしろ、いくつかの課題や解決策についてご理解いただけたかと思います。
RSSフィードの解析は、外部HTTPリクエストや並列最適化を伴うデータ構造が関わるため、ハードルが高めです。経験豊富なRustユーザーであれば、なぜstd::rssクレートを使わなかったのか? と疑問に思うかもしれません。その理由は、std::rssは高度な非同期実行に最適化されており、このブログ記事でご説明したさまざまなRustの機能を示したり説明したりすることができないためです。ぜひ、非同期の演習として、rss クレートを使ってコードを書き直してみてください。
非同期学習のエクササイズ
このブログ記事で学んだ内容は、永続的なデータ保存やデータ表示に関する理解を今後も深めていく上で基礎となります。引き続きRustを学びながら、リーダーアプリを最適化していくためのアイデアをいくつかご紹介します。
- データ保存:sqliteなどのデータベースを使用し、RSSフィードの更新履歴を追跡する。
- 通知:子プロセスを生成して、Telegramなどに通知を送る機能を追加する。
- 機能:リーダータイプを拡張して、REST APIをサポートする。
- 構成:RSSフィードやAPIなどの構成ファイルのサポートを追加する。
- 効率性:フィルタリングやサブスクライブしたタグのサポートを追加する。
- デプロイ:Webサーバーを使用して、Prometheusメトリクスを収集してKubernetesにデプロイする。
今後のブログ記事では、これらのアイデアのいくつかを取り上げ、その実装方法について説明します。既存のRSSフィードの実装を詳しく調べ、どのように既存のコードをリファクタリングしてRustのライブラリ(crates)を活用できるか学びましょう。
フィードバックの共有
GitLab Duoのコード提案をご使用になった方は、ぜひご意見をフィードバックイシューにお寄せください。
監修:佐々木 直晴 @naosasaki
(GitLab合同会社 ソリューションアーキテクト本部 シニアソリューションアーキテクト)




