
is now in public beta!
Published on: October 1, 2018
6 min read
GitLab's product vision for 2019 and beyond
Watch Head of Product, Mark Pundsack, present our product vision.

We recently went live to discuss the news of our Series D funding and what the future holds for GitLab. You can watch GitLab's Head of Product, Mark Pundsack, present our vision with some previews of what's in the works below:
Watch the recording
View the slides
Summary of our product vision
Our strategy is to double down on what's working: while we already cover the entire DevOps lifecycle, we want to increase depth in some of our existing features, transitioning from minimum viable change to minimum loveable feature.
I thought @Jobvo had me at "Minimal Viable Change". But then @MarkPundsack comes out with "Minimal Lovable Product" and I'm awestruck #GitLabLive
— Brendan O'Leary 👨🏻💻 (@olearycrew) September 20, 2018
We're also going to continue to increase our breadth, building out new capabilities across the entire DevOps lifecycle.
And finally, because we believe everyone can contribute, we're going to add more roles to the scope of product, including executives, designers, product managers, and essentially anyone who is involved in software development and delivery. Our goal is to get everyone working concurrently in a single product, with nine best-in-class categories.
Coming up...
We're working on building out 26 new capabilities, but because you don't have all day, below are three examples to give you a taste of what's in the works.
Obligatory disclaimer: These are mock-ups and the features may turn out looking a little different, or may not ship at all
Executive flow: Value Stream Management
At its heart, Value Stream Management is about understanding your teams' work and their workflow on the way to delivering value to customers. The way we're approaching it is to extend something development teams are already using to track their work, namely issue boards, and bring it into the bigger picture by having a board that covers the entire workflow necessary to get ideas into production.
Because GitLab already covers that entire scope, we can automate it too. We know when a feature is scheduled. We know when you push your first commit. We know when code review starts. We know when you deploy your code to production. So we can move the cards to the right spots automatically, so not only can you track your progress and communicate it to your team, you can track it all automatically and more accurately. Neat, huh?
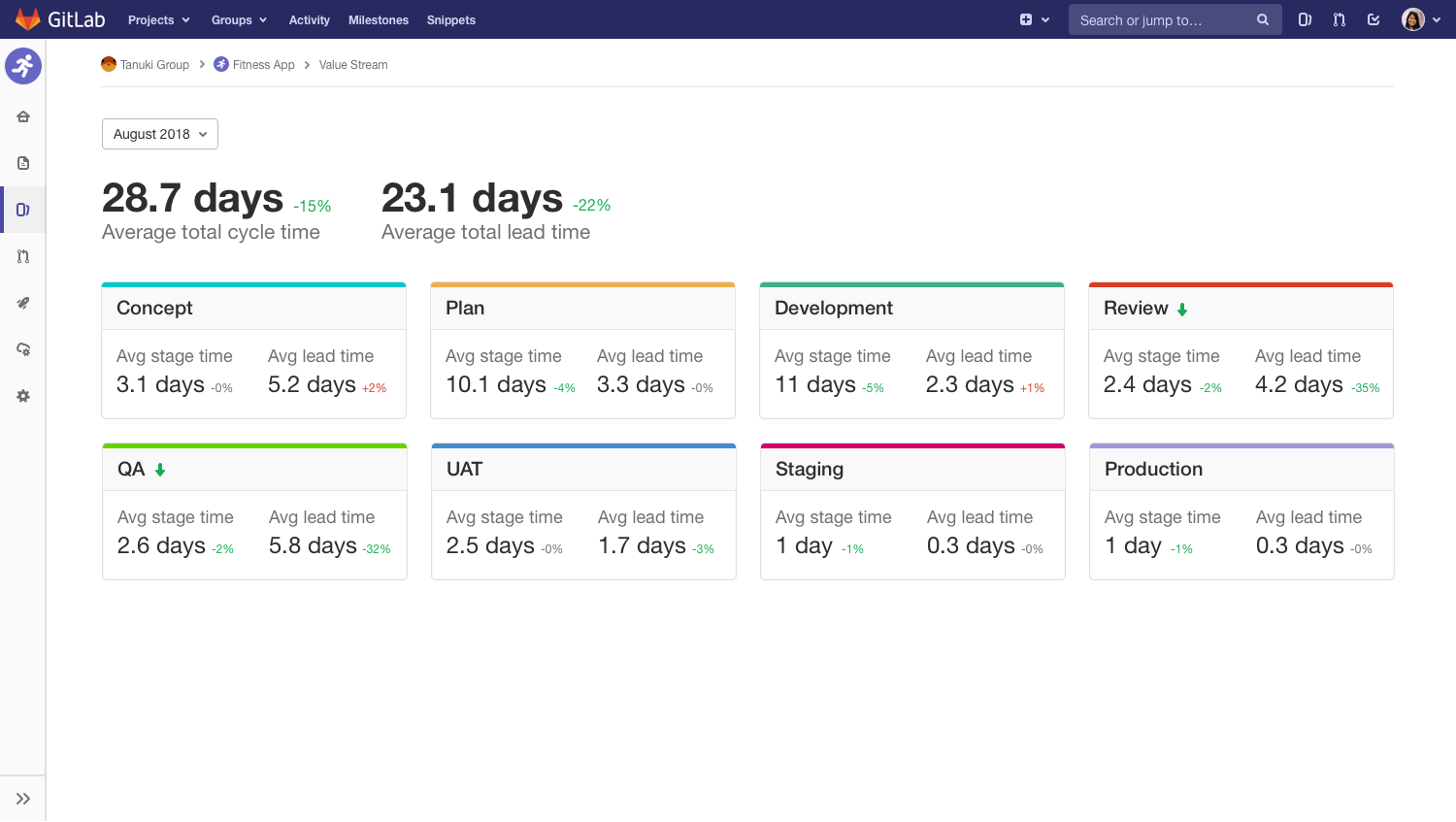
The above mock-up demonstrates a situation where someone was able to dive into the time spent on various areas, and see that the time spent waiting for someone to even start QA was really high, and they managed to shave off a few days just by rearranging some internal processes. The same goes for the code review cycle.
Ops flow: Incident management
This is an operations flow based on a new product capability: incident management. We monitor your production apps and detect an anomaly, alert you, and then open an incident. Then in one place you can see: what triggered the alert, who's involved in responding, quick links to the Slack conversation, Zoom call, and where to update your public status page. There's also a timeline of all activity. Because this is part of the same application that developers are using, it’s not just operations people using this tool, so when you’re working together on problems, you’re looking at the same data, and GitLab knows not only what metrics are alerting, but what code was recently deployed that might have caused it, and who was behind that code. When the incident is resolved, you can easily follow up with your users with a postmortem, pulling in all the relevant data and timeline of events. Of course, with all that data comes great power for analytics, to help the team learn from the incidents and improve.
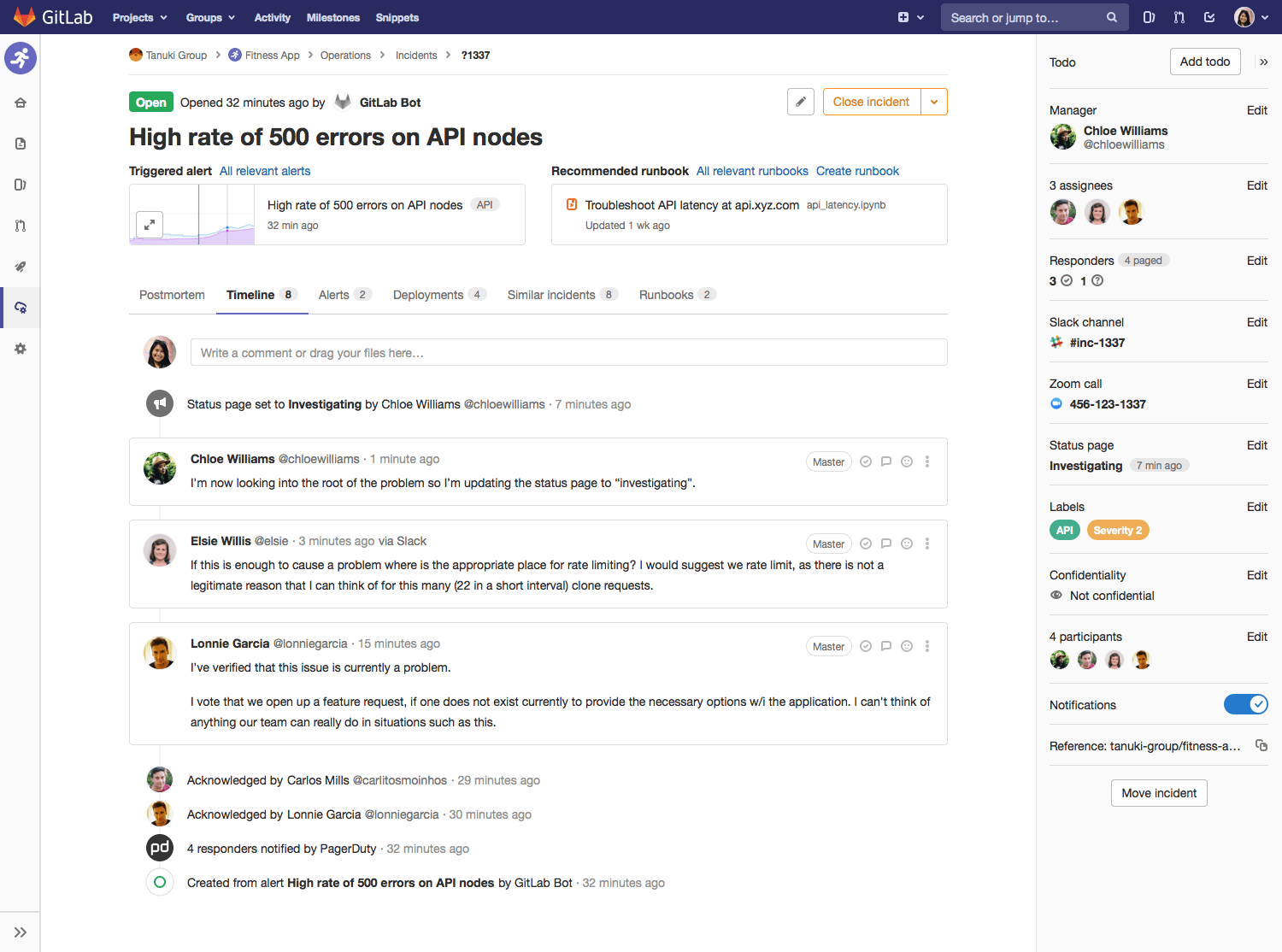 Mock-up showing an Incident open with timeline view, including Slack messages and Status page updates
Mock-up showing an Incident open with timeline view, including Slack messages and Status page updates
Security flow: Auto remediate
A common security task is watching for new vulnerabilities in your project’s dependencies. If a module you depend on has a vulnerability, there’s usually a patch update to go along with it. When that patch is released, you then need to test your software again with that patch, to make sure everything still works before you deploy it. That’s a pain!
Instead of making anyone do all that repetitive, but necessary security work, we want to automate it all away. In our vision, a bot detects that a dependency has a new version, and instead of alerting someone, automatically creates a merge request that bumps the version number for you, and runs the test suite to make sure that everything still works. The CI pipeline passes, and confirms that the security vulnerability is now gone, so the bot automatically merges the changes. If all goes well, your security and development teams just get an email in the morning saying that all the projects with that dependency were automatically fixed.
By why leave a known, security vulnerability live any longer than it needs to?
To bring it full circle, after merging, the CI/CD pipeline starts incrementally
deploying to production. If the production error rate jumps, we automatically
stop the incremental rollout, and go ahead and roll back to the last-known good
version immediately. The bot detects this and automatically reverts the merge
request so we can leave master in a good state. This, we can finally alert the
teams about, so instead of having to test 20 projects manually, they can focus
on the few that can’t be automated.
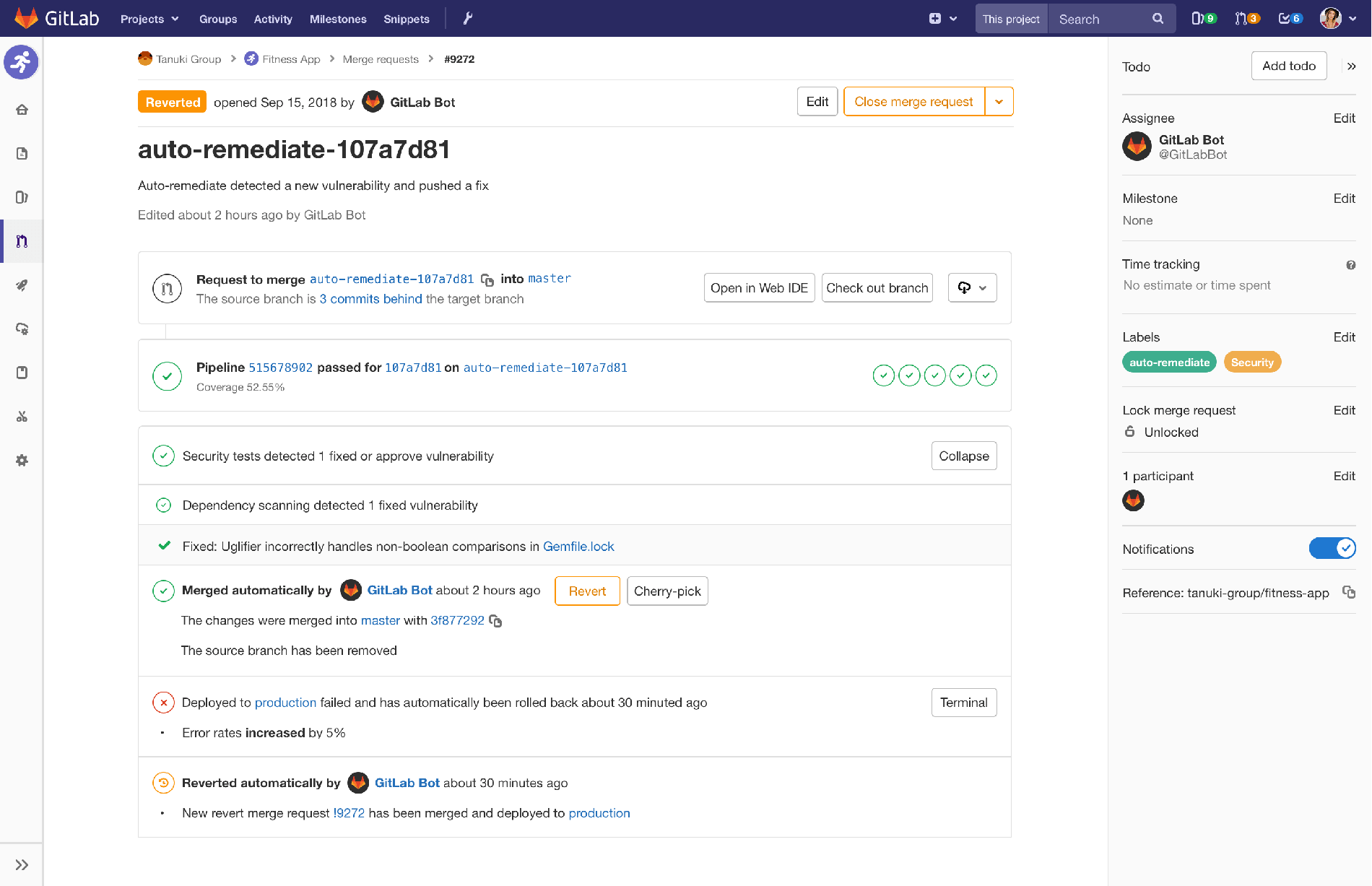 Mock-up showing a merge request reverted automatically following detection of production errors
Mock-up showing a merge request reverted automatically following detection of production errors
As always, our plans are in draft and we welcome your feedback and input!
We want to hear from you
Enjoyed reading this blog post or have questions or feedback? Share your thoughts by creating a new topic in the GitLab community forum.
Share your feedback