
is now in public beta!
Published on: October 12, 2023
29 min read
Learn advanced Rust programming with a little help from AI
Use this guided tutorial, along with AI-powered GitLab Duo Code Suggestions, to continue learning advanced Rust programming.


When I started learning a new programming language more than 20 years ago, we had access to the Visual Studio 6 MSDN library, installed from 6 CD-ROMs. Algorithms with pen and paper, design pattern books, and MSDN queries to figure out the correct type were often time-consuming. Learning a new programming language changed fundamentally in the era of remote collaboration and artificial intelligence (AI). Now you can spin up a remote development workspace, share your screen, and engage in a group programming session. With the help of GitLab Duo Code Suggestions, you always have an intelligent partner at your fingertips. Code Suggestions can learn from your programming style and experience. They only need input and context to provide you with the most efficient suggestions.
In this tutorial, we build on the getting started blog post and design and create a simple feed reader application.
- Preparations
- Continue learning Rust
- Modules
- Crates
- Runtime configuration: Program arguments
- Persistence and data storage
- Optimization
- Parse feed XML into objects
- Benchmarks
- What is next
Preparations
Before diving into the source code, make sure to set up VS Code and your development environment with Rust.
Code Suggestions
Familiarize yourself with suggestions before actually verifying the suggestions. GitLab Duo Code Suggestions are provided as you type, so you do not need use specific keyboard shortcuts. To accept a code suggestion, press the tab key. Also note that writing new code works more reliably than refactoring existing code. AI is non-deterministic, which means that the same suggestion may not be repeated after deleting the code suggestion. While Code Suggestions is in Beta, we are working on improving the accuracy of generated content overall. Please review the known limitations, as this could affect your learning experience.
Tip: The latest release of Code Suggestions supports multi-line instructions. You can refine the specifications to your needs to get better suggestions.
// Create a function that iterates over the source array
// and fetches the data using HTTP from the RSS feed items.
// Store the results in a new hash map.
// Print the hash map to the terminal.
The VS Code extension overlay is shown when offering a suggestion. You can use the tab key to accept the suggested line(s), or cmd cursor right to accept one word. Additionally, the three dots menu allows you to always show the toolbar.

Continue learning Rust
Now, let us continue learning Rust, which is one of the supported languages in Code Suggestions. Rust by Example provides an excellent tutorial for beginners, together with the official Rust book. Both resources are referenced throughout this blog post.
Hello, Reader App
There are many ways to create an application and learn Rust. Some of them involve using existing Rust libraries - so-called Crates. We will use them a bit further into the blog post. For example, you could create a command-line app that processes images and writes the result to a file. Solving a classic maze or writing a Sudoku solver can also be a fun challenge. Game development is another option. The book Hands-on Rust provides a thorough learning path by creating a dungeon crawler game. My colleague Fatima Sarah Khalid started the Dragon Realm in C++ with a little help from AI -- check it out, too.
Here is a real use case that helps solve an actual problem: Collecting important information from different sources into RSS feeds for (security) releases, blog posts, and social discussion forums like Hacker News. Often, we want to filter for specific keywords or versions mentioned in the updates. These requirements allow us to formulate a requirements list for our application:
- Fetch data from different sources (HTTP websites, REST API, RSS feeds). RSS feeds in the first iteration.
- Parse the data.
- Present the data to the user, or write it to disk.
- Optimize performance.
The following example application output will be available after the learning steps in this blog post:

The application should be modular and build the foundation to add more data types, filters, and hooks to trigger actions at a later point.
Initialize project
Reminder: cargo init in the project root creates the file structure, including the main() entrypoint. Therefore, we will learn how to create and use Rust modules in the next step.
Create a new directory called learn-rust-ai-app-reader, change into it and run cargo init. This command implicitly runs git init to initialize a new Git repository locally. The remaining step is to configure the Git remote repository path, for example, https://gitlab.com/gitlab-de/use-cases/ai/learn-with-ai/learn-rust-ai-app-reader. Please adjust the path for your namespace. Pushing the Git repository automatically creates a new private project in GitLab.
mkdir learn-rust-ai-app-reader
cd learn-rust-ai-app-reader
cargo init
git remote add origin https://gitlab.com/gitlab-de/use-cases/ai/learn-with-ai/learn-rust-ai-app-reader.git
git push --set-upstream origin main
Open VS Code from the newly created directory. The code CLI will spawn a new VS Code window on macOS.
code .
Define RSS feed URLs
Add a new hashmap to store the RSS feed URLs inside the src/main.rs file in the main() function. You can instruct GitLab Duo Code Suggestions with a multi-line comment to create a HashMap object, and initialize it with default values for Hacker News, and TechCrunch. Note: Verify that the URLs are correct when you get suggestions.
fn main() {
// Define RSS feed URLs in the variable rss_feeds
// Use a HashMap
// Add Hacker News and TechCrunch
// Ensure to use String as type
}
Note that the code comment provides instructions for:
- The variable name
rss_feeds. - The
HashMaptype. - Initial seed key/value pairs.
- String as type (can be seen with
to_string()calls).
One possible suggested path can be as follows:
use std::collections::HashMap;
fn main() {
// Define RSS feed URLs in the variable rss_feeds
// Use a HashMap
// Add Hacker News and TechCrunch
// Ensure to use String as type
let rss_feeds = HashMap::from([
("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),
("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),
]);
}

Open a new terminal in VS Code (cmd shift p - search for terminal), and run cargo build to build the changes. The error message instructs you to add the use std::collections::HashMap; import.
The next step is to do something with the RSS feed URLs. The previous blog post taught us to split code into functions. We want to organize the code more modularly for our reader application, and use Rust modules.
Modules
Modules help with organizing code. They can also be used to hide functions into the module scope, limiting access to them from the main() scope. In our reader application, we want to fetch the RSS feed content, and parse the XML response. The main() caller should only be able to access the get_feeds() function, while other functionality is only available in the module.
Create a new file feed_reader.rs in the src/ directory. Instruct Code Suggestions to create a public module named feed_reader, and a public function get_feeds() with a String HashMap as input. Important: The file and module names need to be the same, following the Rust module structure.

Instructing Code Suggestions with the input variable name and type will also import the required std::collections::HashMap module. Tip: Experiment with the comments, and refine the variable types to land the best results. Passing function parameters as object references is considered best practice in Rust, for example.
// Create public module feed_reader
// Define get_feeds() function which takes rss_feeds as String HashMap reference as input
pub mod feed_reader {
use std::collections::HashMap;
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Do something with the RSS feeds
}
}
Inside the function, continue to instruct Code Suggestions with the following steps:
// Iterate over the RSS feed URLs// Fetch URL content// Parse XML body// Print the result




The following code can be suggested:
// Create public module feed_reader
// Define get_feeds() function which takes rss_feeds as String HashMap reference as input
pub mod feed_reader {
use std::collections::HashMap;
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Iterate over the RSS feed URLs
for (name, url) in rss_feeds {
println!("{}: {}", name, url);
// Fetch URL content
let body = reqwest::blocking::get(url).unwrap().text().unwrap();
// Parse XML body
let parsed_body = roxmltree::Document::parse(&body).unwrap();
// Print the result
println!("{:#?}", parsed_body);
}
}
}
You see a new keyword here: unwrap(). Rust does not support null values, and uses the Option type for any value. If you are certain to use a specific wrapped type, for example, Text or String, you can call the unwrap() method to get the value. The unwrap() method will panic if the value is None.
Note Code Suggestions referred to the reqwest::blocking::get function for the // Fetch URL content comment instruction. The reqwest crate name is intentional and not a typo. It provides a convenient, higher-level HTTP client for async and blocking requests.
Parsing the XML body is tricky - you might get different results, and the schema is not the same for every RSS feed URL. Let us try to call the get_feeds() function, and then work on improving the code.
Call the module function in main()
The main() function does not know about the get_feeds() function yet, so we need to import its module. In other programming languages, you might have seen the keywords include or import. The Rust module system is different.
Modules are organized in path directories. In our example, both source files exist on the same directory level. feed_reader.rs is interpreted as crate, containing one module called feed_reader, which defines the function get_feeds().
src/
main.rs
feed_reader.rs
In order to access get_feeds() from the feed_reader.rs file, we need to bring module path into the main.rs scope first, and then call the full function path.
mod feed_reader;
fn main() {
feed_reader::feed_reader::get_feeds(&rss_feeds);
Alternatively, we can import the full function path with the use keyword, and later use the short function name.
mod feed_reader;
use feed_reader::feed_reader::get_feeds;
fn main() {
get_feeds(&rss_feeds);
Tip: I highly recommend reading the Clear explanation of the Rust module system blog post to get a better visual understanding.
fn main() {
// ...
// Print feed_reader get_feeds() output
println!("{}", feed_reader::get_feeds(&rss_feeds));
use std::collections::HashMap;
mod feed_reader;
// Alternative: Import full function path
//use feed_reader::feed_reader::get_feeds;
fn main() {
// Define RSS feed URLs in the variable rss_feeds
// Use a HashMap
// Add Hacker News and TechCrunch
// Ensure to use String as type
let rss_feeds = HashMap::from([
("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),
("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),
]);
// Call get_feeds() from feed_reader module
feed_reader::feed_reader::get_feeds(&rss_feeds);
// Alternative: Imported full path, use short path here.
//get_feeds(&rss_feeds);
}
Run cargo build in the terminal again to build the code.
cargo build
Potential build errors when Code Suggestions refer to common code and libraries for HTTP requests, and XML parsing:
- Error:
could not find blocking in reqwest. Solution: Enable theblockingfeature for the crate inConfig.toml:reqwest = { version = "0.11.20", features = ["blocking"] }. - Error:
failed to resolve: use of undeclared crate or module reqwest. Solution: Add thereqwestcrate. - Error:
failed to resolve: use of undeclared crate or module roxmltree. Solution: Add theroxmltreecrate.
vim Config.toml
reqwest = { version = "0.11.20", features = ["blocking"] }
cargo add reqwest
cargo add roxmltree
Tip: Copy the error message string, with a leading Rust <error message> into your preferred browser to check whether a missing crate is available. Usually this search leads to a result on crates.io and you can add the missing dependencies.
When the build is successful, run the code with cargo run and inspect the Hacker News RSS feed output.

What is next with parsing the XML body into human-readable format? In the next section, we will learn about existing solutions and how Rust crates come into play.
Crates
RSS feeds share a common set of protocols and specifications. It feels like reinventing the wheel to parse XML items and understand the lower object structure. Recommendation for these types of tasks: Look whether someone else had the same problem already and might have created code to solve the problem.
Reusable library code in Rust is organized in so-called Crates, and made available in packages, and the package registry on crates.io. You can add these dependencies to your project by editing the Config.toml in the [dependencies] section, or using cargo add <name>.
For the reader app, we want to use the feed-rs crate. Open a new terminal, and run the following command:
cargo add feed-rs

feed-rs: parse XML feed
Navigate into src/feed_reader.rs and modify the part where we parse the XML body. Code Suggestions understands how to call the feed-rs crate parser::parse function -- there is only one specialty here: feed-rs expects string input as raw bytes to determine the encoding itself. We can provide instructions in the comment to get the expected result though.
// Parse XML body with feed_rs parser, input in bytes
let parsed_body = feed_rs::parser::parse(body.as_bytes()).unwrap();

The benefit of using feed-rs is not immediately visible until you see the printed output with cargo run: All keys and values are mapped to their respective Rust object types, and can be used for further operations.

Runtime configuration: Program arguments
Until now, we have run the program with hard-coded RSS feed values compiled into the binary. The next step is allowing to configure the RSS feeds at runtime.
Rust provides program arguments in the standard misc library. Parsing the arguments provides a better and faster learning experience than aiming for advanced program argument parsers (for example, the clap crate), or moving the program parameters into a configuration file and format (TOML, YAML). You are reading these lines after I tried and failed with different routes for the best learning experience. This should not stop you from taking the challenge to configure RSS feeds in alternative ways.
As a boring solution, the command parameters can be passed as "name,url" string value pairs, and then are split by the , character to extract the name and URL values. The comment instructs Code Suggestions to perform these operations and extend the rss_feeds HashMap with the new values. Note that the variable might not be mutable, and, therefore, needs to be modified to let mut rss_feeds.
Navigate into src/main.rs and add the following code to the main() function after the rss_feeds variable. Start with a comment to define the program arguments, and check the suggested code snippets.
// Program args, format "name,url"
// Split value by , into name, url and add to rss_feeds

The full code example can look like the following:
fn main() {
// Define RSS feed URLs in the variable rss_feeds
// Use a HashMap
// Add Hacker News and TechCrunch
// Ensure to use String as type
let mut rss_feeds = HashMap::from([
("Hacker News".to_string(), "https://news.ycombinator.com/rss".to_string()),
("TechCrunch".to_string(), "https://techcrunch.com/feed/".to_string()),
]);
// Program args, format "name,url"
// Split value by , into name, url and add to rss_feeds
for arg in std::env::args().skip(1) {
let mut split = arg.split(",");
let name = split.next().unwrap();
let url = split.next().unwrap();
rss_feeds.insert(name.to_string(), url.to_string());
}
// Call get_feeds() from feed_reader module
feed_reader::feed_reader::get_feeds(&rss_feeds);
// Alternative: Imported full path, use short path here.
//get_feeds(&rss_feeds);
}
You can pass program arguments directly to the cargo run command, preceding the arguments with --. Enclose all arguments with double quotes, put the name followed by a comma and the RSS feed URL as argument. Separate all arguments with whitespaces.
cargo build
cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"

User input error handling
If the provided user input does not match the program expectation, we need to throw an error and help the caller to fix the program arguments. For example, passing a malformed URL format should be treated as a runtime error. Instruct Code Suggestions with a code comment to throw an error if the URL is not valid.
// Ensure that URL contains a valid format, otherwise throw an error
One possible solution is to check if the url variable starts with http:// or https://. If not, throw an error using the panic! macro. The full code example looks like the following:
// Program args, format "name,url"
// Split value by , into name, url and add to rss_feeds
for arg in std::env::args().skip(1) {
let mut split = arg.split(",");
let name = split.next().unwrap();
let url = split.next().unwrap();
// Ensure that URL contains a valid format, otherwise throw an error
if !url.starts_with("http://") && !url.starts_with("https://") {
panic!("Invalid URL format: {}", url);
}
rss_feeds.insert(name.to_string(), url.to_string());
}
Test the error handling with removing a : in one of the URL strings. Add the RUST_BACKTRACE=full environment variable to get more verbose output when the panic() call happens.
RUST_BACKTRACE=full cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https//www.cncf.io/feed/"

Persistence and data storage
The boring solution for storing the feed data is to dump the parsed body into a new file. Instruct Code Suggestions to use a pattern that includes the RSS feed name, and the current ISO date.
// Parse XML body with feed_rs parser, input in bytes
let parsed_body = feed_rs::parser::parse(body.as_bytes()).unwrap();
// Print the result
println!("{:#?}", parsed_body);
// Dump the parsed body to a file, as name-current-iso-date.xml
let now = chrono::offset::Local::now();
let filename = format!("{}-{}.xml", name, now.format("%Y-%m-%d"));
let mut file = std::fs::File::create(filename).unwrap();
file.write_all(body.as_bytes()).unwrap();
A possible suggestion will include using the chrono crate. Add it using cargo add chrono and then invoke cargo build and cargo run again.
The files are written into the same directory where cargo run was executed. If you are executing the binary direcly in the target/debug/ directory, all files will be dumped there.
Optimization
The entries in the rss_feeds variable are executed sequentially. Imagine having a list of 100+ URLs configured - this could take a long time to fetch and process. What if we could execute multiple fetch requests in parallel?
Asynchronous execution
Rust provides threads for asynchronous execution.
The simplest solution will be spawning a thread for each RSS feed URL. We will discuss optimization strategies later. Before you continue with parallel execution, measure the sequential code execution time by preceding the time command with cargo run.
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.21s user 0.08s system 10% cpu 2.898 total
Note that this exercise could require more manual code work. It is recommended to persist the sequential working state in a new Git commit and branch sequential-exec, to better compare the impact of parallel execution.
git commit -avm "Sequential execution working"
git checkout -b sequential-exec
git push -u origin sequential-exec
git checkout main
Spawning threads
Open src/feed_reader.rs and refactor the get_feeds() function. Start with a Git commit for the current state, and then delete the contents of the function scope. Add the following code comments with instructions for Code Suggestions:
// Store threads in vector: Store thread handles in a vector, so we can wait for them to finish at the end of the function call.// Loop over rss_feeds and spawn threads: Create boilerplate code for iterating over all RSS feeds, and spawn a new thread.
Add the following use statements to work with the thread and time modules.
use std::thread;
use std::time::Duration;
Continue writing the code, and close the for loop. Code Suggestions will automatically propose adding the thread handle in the threads vector variable, and offer to join the threads at the end of the function.
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Store threads in vector
let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();
// Loop over rss_feeds and spawn threads
for (name, url) in rss_feeds {
let thread_name = name.clone();
let thread_url = url.clone();
let thread = thread::spawn(move || {
});
threads.push(thread);
}
// Join threads
for thread in threads {
thread.join().unwrap();
}
}
Add the thread crate, build and run the code again.
cargo add thread
cargo build
cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
At this stage, no data is processed or printed. Before we continue re-adding the functionality, let us learn about the newly introduced keywords here.
Function scopes, threads, and closures
The suggested code brings new keywords and design patterns to learn. The thread handle is of the type thread::JoinHandle, indicating that we can use it to wait for the threads to finish (join()).
thread::spawn() spawns a new thread, where we can pass a function object. In this case, a closure expression is passed as anonymous function. Closure inputs are passed using the || syntax. You will recognize the move Closure, which moves the function scoped variables into the thread scope. This avoids manually specifying which variables need to be passed into the new function/closure scope.
There is a limitation though: rss_feeds is a reference &, passed as parameter by the get_feeds() function caller. The variable is only valid in the function scope. Use the following code snippet to provoke this error:
pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Store threads in vector
let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();
// Loop over rss_feeds and spawn threads
for (key, value) in rss_feeds {
let thread = thread::spawn(move || {
println!("{}", key);
});
}
}

Although the key variable was created in the function scope, it references the rss_feeds variable, and therefore, it cannot be moved into the thread scope. Any values accessed from the function parameter rss_feeds hash map will require a local copy with clone().

pub fn get_feeds(rss_feeds: &HashMap<String, String>) {
// Store threads in vector
let mut threads: Vec<thread::JoinHandle<()>> = Vec::new();
// Loop over rss_feeds and spawn threads
for (name, url) in rss_feeds {
let thread_name = name.clone();
let thread_url = url.clone();
let thread = thread::spawn(move || {
// Use thread_name and thread_url as values, see next chapter for instructions.
Parse feed XML into object types
The next step is to repeat the RSS feed parsing steps in the thread closure. Add the following code comments with instructions for Code Suggestions:
// Parse XML body with feed_rs parser, input in bytesto tell Code Suggestions that we want to fetch the RSS feed URL content, and parse it with thefeed_rscrate functions.// Check feed_type attribute feed_rs::model::FeedType::RSS2 or Atom and print its name: Extract the feed type by comparing thefeed_typeattribute with thefeed_rs::model::FeedType. This needs more direct instructions for Code Suggestions telling it about the exact Enum values to match against.
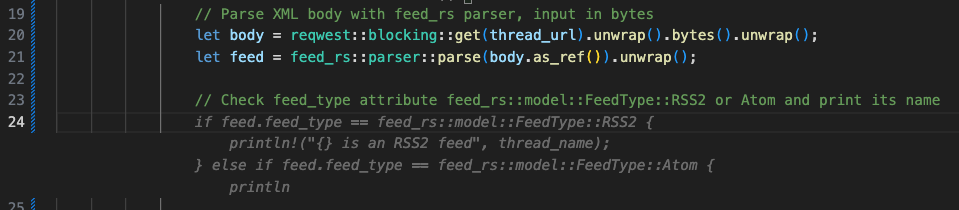
// Parse XML body with feed_rs parser, input in bytes
let body = reqwest::blocking::get(thread_url).unwrap().bytes().unwrap();
let feed = feed_rs::parser::parse(body.as_ref()).unwrap();
// Check feed_type attribute feed_rs::model::FeedType::RSS2 or Atom and print its name
if feed.feed_type == feed_rs::model::FeedType::RSS2 {
println!("{} is an RSS2 feed", thread_name);
} else if feed.feed_type == feed_rs::model::FeedType::Atom {
println!("{} is an Atom feed", thread_name);
}
Build and run the program again, and verify its output.
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
CNCF is an RSS2 feed
TechCrunch is an RSS2 feed
GitLab Blog is an Atom feed
Hacker News is an RSS2 feed
Let us verify this output by opening the feed URLs in the browser, or inspecting the previously downloaded files.
Hacker News supports RSS version 2.0, with channel(title,link,description,item(title,link,pubDate,comments)). TechCrunch and the CNCF blog follow a similar structure.
<rss version="2.0"><channel><title>Hacker News</title><link>https://news.ycombinator.com/</link><description>Links for the intellectually curious, ranked by readers.</description><item><title>Writing a debugger from scratch: Breakpoints</title><link>https://www.timdbg.com/posts/writing-a-debugger-from-scratch-part-5/</link><pubDate>Wed, 27 Sep 2023 06:31:25 +0000</pubDate><comments>https://news.ycombinator.com/item?id=37670938</comments><description><![CDATA[<a href="https://news.ycombinator.com/item?id=37670938">Comments</a>]]></description></item><item>
The GitLab blog uses the Atom feed format similar to RSS, but still requires different parsing logic.
<?xml version='1.0' encoding='utf-8' ?>
<feed xmlns='http://www.w3.org/2005/Atom'>
<!-- / Get release posts -->
<!-- / Get blog posts -->
<title>GitLab</title>
<id>https://about.gitlab.com/blog</id>
<link href='https://about.gitlab.com/blog/' />
<updated>2023-09-26T00:00:00+00:00</updated>
<author>
<name>The GitLab Team</name>
</author>
<entry>
<title>Atlassian Server ending: Goodbye disjointed toolchain, hello DevSecOps platform</title>
<link href='https://about.gitlab.com/blog/atlassian-server-ending-move-to-a-single-devsecops-platform/' rel='alternate' />
<id>https://about.gitlab.com/blog/atlassian-server-ending-move-to-a-single-devsecops-platform/</id>
<published>2023-09-26T00:00:00+00:00</published>
<updated>2023-09-26T00:00:00+00:00</updated>
<author>
<name>Dave Steer, Justin Farris</name>
</author>
Map generic feed data types
Using roxmltree::Document::parse would require us to understand the XML node tree and its specific tag names. Fortunately, feed_rs::model::Feed provides a combined model for RSS and Atom feeds, therefore let us continue using the feed_rs crate.
- Atom: Feed->Feed, Entry->Entry
- RSS: Channel->Feed, Item->Entry
In addition to the mapping above, we need to extract the required attributes, and map their data types. It is helpful to open the feed_rs::model documentation to understand the structs and their fields and implementations. Otherwise, some suggestions would result in type conversion errors and compilation failures, that are specific to the feed_rs implementation.
A Feed struct provides the title, type Option<Text> (either a value is set, or nothing). An Entry struct provides:
title:Option<Text>withTextand thecontentfield asString.updated:Option<DateTime<Utc>>withDateTimewith theformat()method.summary:Option<Text>Textand thecontentfield asString.links:Vec<Link>, vector withLinkitems. Thehrefattribute provides the raw URL string.
Use this knowledge to extract the required data from the feed entries. Reminder that all Option types need to call unwrap(), which requires more raw instructions for Code Suggestions.
// https://docs.rs/feed-rs/latest/feed_rs/model/struct.Feed.html
// https://docs.rs/feed-rs/latest/feed_rs/model/struct.Entry.html
// Loop over all entries, and print
// title.unwrap().content
// published.unwrap().format
// summary.unwrap().content
// links href as joined string
for entry in feed.entries {
println!("Title: {}", entry.title.unwrap().content);
println!("Published: {}", entry.published.unwrap().format("%Y-%m-%d %H:%M:%S"));
println!("Summary: {}", entry.summary.unwrap().content);
println!("Links: {:?}", entry.links.iter().map(|link| link.href.clone()).collect::<Vec<String>>().join(", "));
println!();
}

Error handling with Option unwrap()
Continue iterating on the multi-line instructions after building and running the program again. Spoiler: unwrap() will call the panic! macro and crash the program when it encounters empty values. This can happen if a field like summary is not set in the feed data.
GitLab Blog is an Atom feed
Title: How the Colmena project uses GitLab to support citizen journalists
Published: 2023-09-27 00:00:00
thread '<unnamed>' panicked at 'called `Option::unwrap()` on a `None` value', src/feed_reader.rs:40:59
A potential solution is to use std::Option::unwrap_or_else and set an empty string as default value. The syntax requires a closure that returns an empty Text struct instantiation.
Solving the problem required many attempts to find the correct initialization, passing just an empty string did not work with the custom types. I will show you all my endeavors, including the research paths.
// Problem: The `summary` attribute is not always initialized. unwrap() will panic! then.
// Requires use mime; and use feed_rs::model::Text;
/*
// 1st attempt: Use unwrap() to extraxt Text from Option<Text> type.
println!("Summary: {}", entry.summary.unwrap().content);
// 2nd attempt. Learned about unwrap_or_else, passing an empty string.
println!("Summary: {}", entry.summary.unwrap_or_else(|| "").content);
// 3rd attempt. summary is of the Text type, pass a new struct instantiation.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{}).content);
// 4th attempt. Struct instantiation requires 3 field values.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{"", "", ""}).content);
// 5th attempt. Struct instantation with public fields requires key: value syntax
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: "", src: "", content: ""}).content);
// 6th attempt. Reviewed expected Text types in https://docs.rs/feed-rs/latest/feed_rs/model/struct.Text.html and created Mime and String objects
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: String::new(), content: String::new()}).content);
// 7th attempt: String and Option<String> cannot be casted automagically. Compiler suggested using `Option::Some()`.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(), content: String::new()}).content);
*/
// xth attempt: Solution. Option::Some() requires a new String object.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(String::new()), content: String::new()}).content);
This approach did not feel satisfying, since the code line is complicated to read, and required manual work without help from Code Suggestions. Taking a step back, I reviewed what brought me there - if Option is none, unwrap() will throw an error. Maybe there is an easier way to handle this? I asked Code Suggestions in a new comment:
// xth attempt: Solution. Option::Some() requires a new String object.
println!("Summary: {}", entry.summary.unwrap_or_else(|| Text{content_type: mime::TEXT_PLAIN, src: Option::Some(String::new()), content: String::new()}).content);
// Alternatively, use Option.is_none()
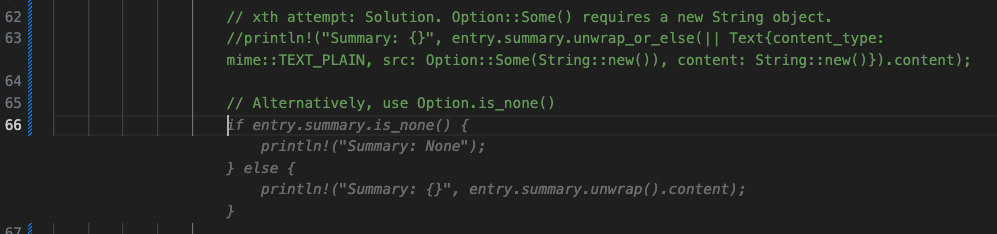
Increased readability, less CPU cycles wasted on unwrap(), and a great learning curve from solving a complex problem to using a boring solution. Win-win.
Before we forget: Re-add storing the XML data on disk to complete the reader app again.
// Dump the parsed body to a file, as name-current-iso-date.xml
let file_name = format!("{}-{}.xml", thread_name, chrono::Local::now().format("%Y-%m-%d-%H-%M-%S"));
let mut file = std::fs::File::create(file_name).unwrap();
file.write_all(body.as_ref()).unwrap();
Build and run the program to verify the output.
cargo build
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
Benchmarks
Sequential vs. Parallel execution benchmark
Compare the execution time benchmarks by creating five samples each.
- Sequential execution. Example source code MR
- Parallel exeuction. Example source code MR
# Sequential
git checkout sequential-exec
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.21s user 0.08s system 10% cpu 2.898 total
0.21s user 0.08s system 11% cpu 2.585 total
0.21s user 0.09s system 10% cpu 2.946 total
0.19s user 0.08s system 10% cpu 2.714 total
0.20s user 0.10s system 10% cpu 2.808 total
# Parallel
git checkout parallel-exec
time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"
0.19s user 0.08s system 17% cpu 1.515 total
0.18s user 0.08s system 16% cpu 1.561 total
0.18s user 0.07s system 17% cpu 1.414 total
0.19s user 0.08s system 18% cpu 1.447 total
0.17s user 0.08s system 16% cpu 1.453 total
The CPU usage increased for parallel execution of four RSS feed threads, but it nearly halved the total time compared to sequential execution. With that in mind, we can continue learning Rust and optimize the code and functionality.
Note that we are running the debug build through Cargo, and not the optimized released builds yet. There are caveats with parallel execution though: Some HTTP endpoints put rate limits in place, where parallelism could hit these thresholds easier.
The system executing multiple threads in parallel might get overloaded too – threads require context switching in the Kernel, assigning resources to each thread. While one thread gets computing resources, other threads are put to sleep. If there are too many threads spawned, this might slow down the system, rather than speeding up the operations. Solutions include design patterns such as work queues, where the caller adds a task into a queue, and a defined number of worker threads pick up the tasks for asynchronous execution.
Rust also provides data synchronisation between threads, so-called channels. To ensure concurrent data access, mutexes are available to provide safe locks.
CI/CD with Rust caching
Add the following CI/CD configuration into the .gitlab-ci.yml file. The run-latest job calls cargo run with RSS feed URL examples, and measures the execution time continuously.
stages:
- build
- test
- run
default:
image: rust:latest
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- .cargo/bin
- .cargo/registry/index
- .cargo/registry/cache
- target/debug/deps
- target/debug/build
policy: pull-push
# Cargo data needs to be in the project directory for being cached.
variables:
CARGO_HOME: ${CI_PROJECT_DIR}/.cargo
build-latest:
stage: build
script:
- cargo build --verbose
test-latest:
stage: build
script:
- cargo test --verbose
run-latest:
stage: run
script:
- time cargo run -- "GitLab Blog,https://about.gitlab.com/atom.xml" "CNCF,https://www.cncf.io/feed/"

What is next
This blog post was challenging to create, with both learning advanced Rust programming techniques myself, and finding a good learning curve with Code Suggestions. The latter greatly helps with quickly generating code, not just boilerplate snippets – it understands the local context, and better understands the purpose and scope of the algorithm, the more code you write. After reading this blog post, you know of a few challenges and turnarounds. The example solution code for the reader app is available in the learn-rust-ai-app-reader project.
Parsing RSS feeds is challenging since it involves data structures, with external HTTP requests and parallel optimizations. As an experienced Rust user, you might have wondered: Why not use the std::rss crate? -- It is optimized for advanced asynchronous execution, and does not allow to show and explain the different Rust functionalities, explained in this blog post. As an async exercise, try to rewrite the code using the rss crate.
Async learning exercises
The lessons learned in this blog post also lay the foundation for future exploration with persistent storage and presenting the data. Here are a few ideas where you can continue learning Rust and optimize the reader app:
- Data storage: Use a database like sqlite, and RSS feed update tracking.
- Notifications: Spawn child processes to trigger notifications into Telegram, etc.
- Functionality: Extend the reader types to REST APIs
- Configuration: Add support for configuration files for RSS feeds, APIs, etc.
- Efficiency: Add support for filters, and subscribed tags.
- Deployments: Use a webserver, collect Prometheus metrics, and deploy to Kubernetes.
In a future blog post, we will discuss some of these ideas, and how to implement them. Dive into existing RSS feed implementations, and learn how you can refactor the existing code into leveraging more Rust libraries (crates).
Share your feedback
When you use GitLab Duo Code Suggestions, please share your thoughts in the feedback issue.
We want to hear from you
Enjoyed reading this blog post or have questions or feedback? Share your thoughts by creating a new topic in the GitLab community forum.
Share your feedback