
is now in public beta!
Published on: September 29, 2021
17 min read
Why we spent the last month eliminating PostgreSQL subtransactions
How a mysterious stall in database queries uncovered a performance limitation with PostgreSQL.


Since last June, we noticed the database on GitLab.com would
mysteriously stall for minutes, which would lead to users seeing 500
errors during this time. Through a painstaking investigation over
several weeks, we finally uncovered the cause of this: initiating a
subtransaction via the SAVEPOINT SQL query while
a long transaction is in progress can wreak havoc on database
replicas. Thus launched a race, which we recently completed, to
eliminate all SAVEPOINT queries from our code. Here's what happened,
how we discovered the problem, and what we did to fix it.
The symptoms begin
On June 24th, we noticed that our CI/CD runners service reported a high error rate:
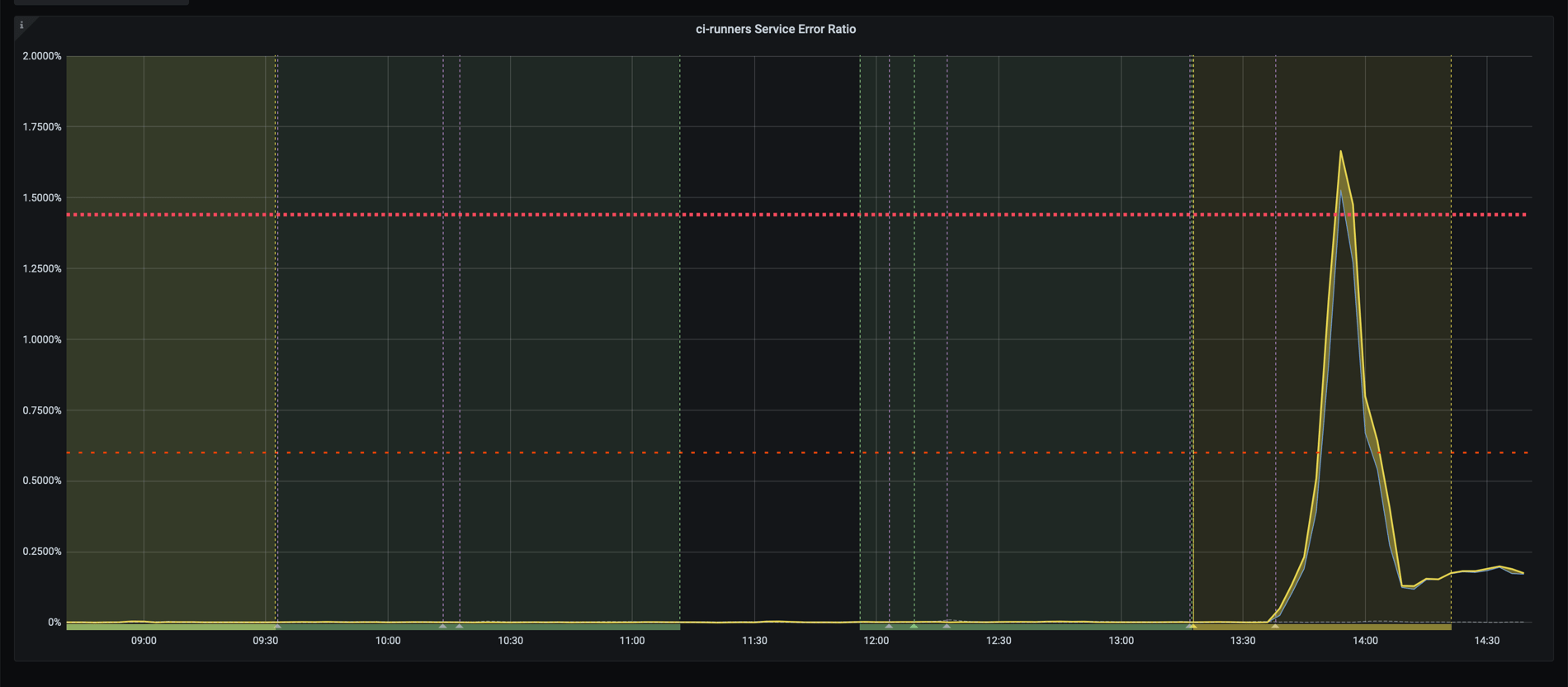
A quick investigation revealed that database queries used to retrieve CI/CD builds data were timing out and that the unprocessed builds backlog grew at a high rate:
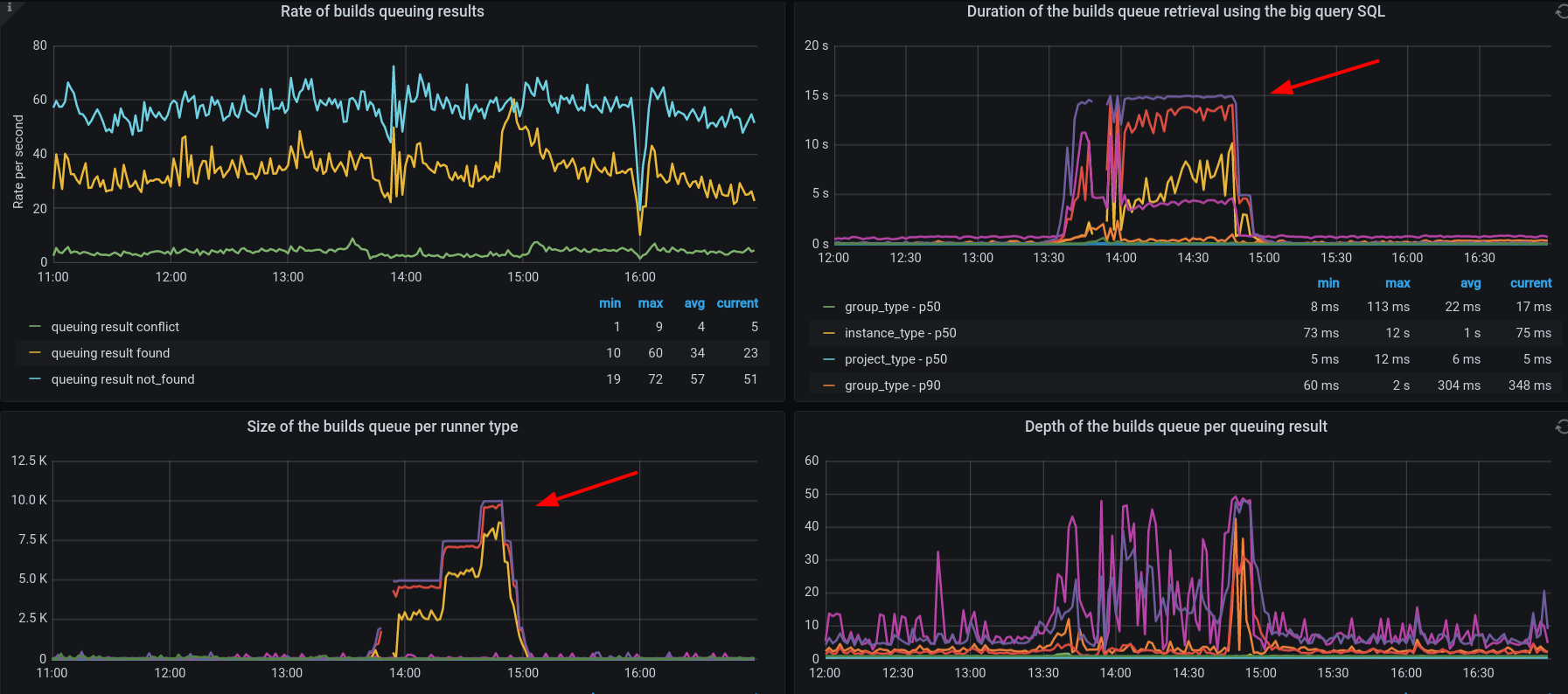
Our monitoring also showed that some of the SQL queries were waiting for
PostgreSQL lightweight locks (LWLocks):
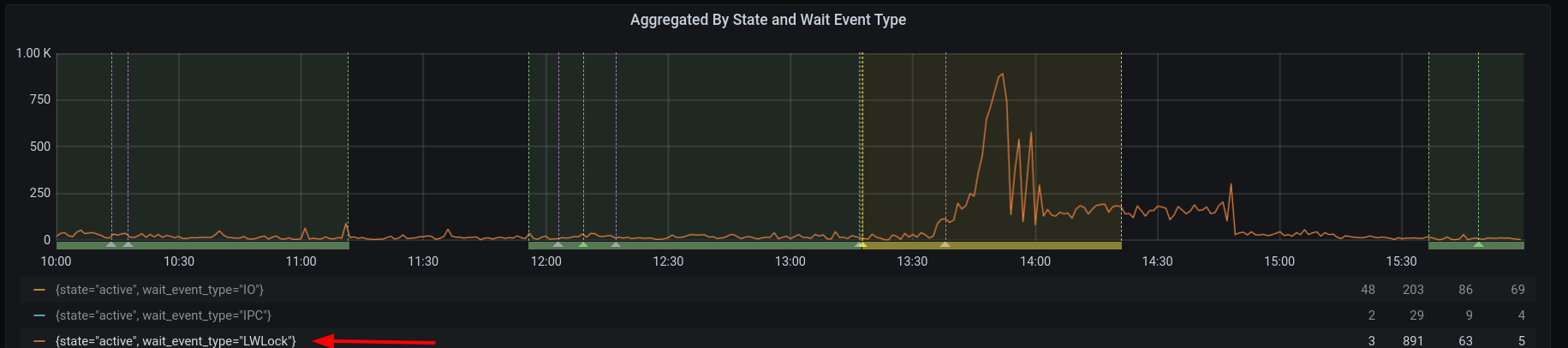
In the following weeks we had experienced a few incidents like this. We were surprised to see how sudden these performance degradations were, and how quickly things could go back to normal:
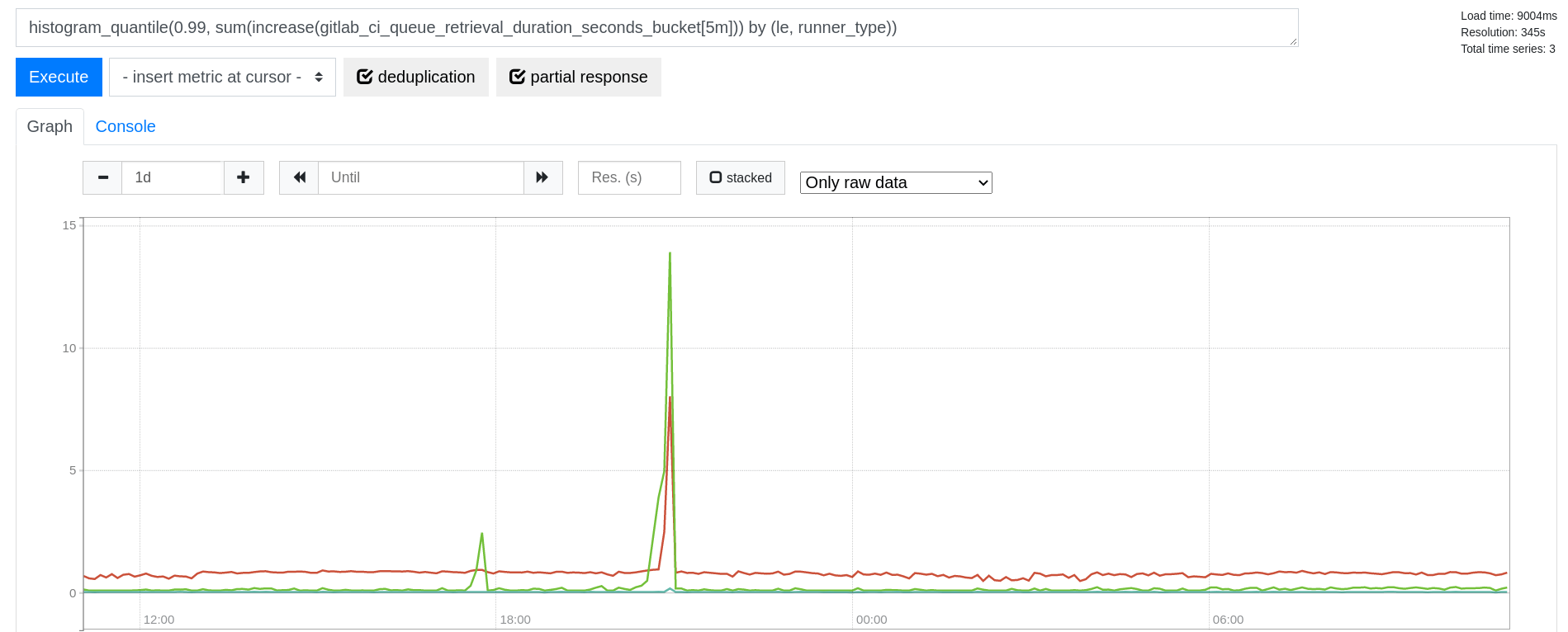
Introducing Nessie: Stalled database queries
In order to learn more, we extended our observability tooling to sample
more data from pg_stat_activity. In PostgreSQL, the pg_stat_activity
virtual table contains the list of all database connections in the system as
well as what they are waiting for, such as a SQL query from the
client. We observed a consistent pattern: the queries were waiting on
SubtransControlLock. Below shows a graph of the URLs or jobs that were
stalled:
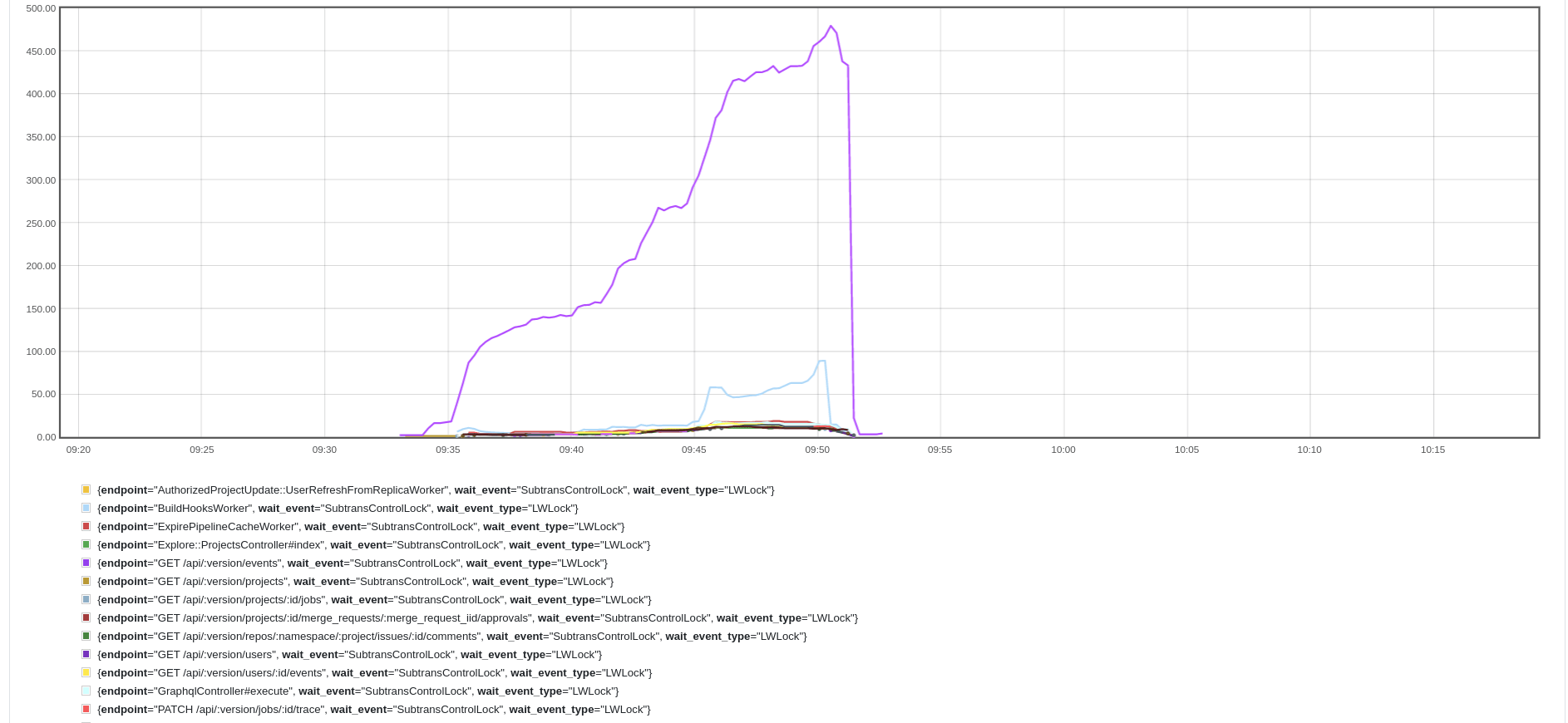
The purple line shows the sampled number of transactions locked by
SubtransControlLock for the POST /api/v4/jobs/request endpoint that
we use for internal communication between GitLab and GitLab Runners
processing CI/CD jobs.
Although this endpoint was impacted the most, the whole database cluster appeared to be affected as many other, unrelated queries timed out.
This same pattern would rear its head on random days. A week would pass by without incident, and then it would show up for 15 minutes and disappear for days. Were we chasing the Loch Ness Monster?
Let's call these stalled queries Nessie for fun and profit.
What is a SAVEPOINT?
To understand SubtransControlLock (PostgreSQL
13
renamed this to SubtransSLRU), we first must understand how
subtransactions work in PostgreSQL. In PostgreSQL, a transaction can
start via a BEGIN statement, and a subtransaction can be started with
a subsequent SAVEPOINT query. PostgreSQL assigns each of these a
transaction ID (XID for short) when a transaction or a subtransaction
needs one, usually before a client modifies data.
Why would you use a SAVEPOINT?
For example, let's say you were running an online store and a customer
placed an order. Before the order is fullfilled, the system needs to
ensure a credit card account exists for that user. In Rails, a common
pattern is to start a transaction for the order and call
find_or_create_by. For
example:
Order.transaction do
begin
CreditAccount.transaction(requires_new: true) do
CreditAccount.find_or_create_by(customer_id: customer.id)
rescue ActiveRecord::RecordNotUnique
retry
end
# Fulfill the order
# ...
end
If two orders were placed around the same time, you wouldn't want the creation of a duplicate account to fail one of the orders. Instead, you would want the system to say, "Oh, an account was just created; let me use that."
That's where subtransactions come in handy: the requires_new: true
tells Rails to start a new subtransaction if the application already is
in a transaction. The code above translates into several SQL calls that
look something like:
--- Start a transaction
BEGIN
SAVEPOINT active_record_1
--- Look up the account
SELECT * FROM credit_accounts WHERE customer_id = 1
--- Insert the account; this may fail due to a duplicate constraint
INSERT INTO credit_accounts (customer_id) VALUES (1)
--- Abort this by rolling back
ROLLBACK TO active_record_1
--- Retry here: Start a new subtransaction
SAVEPOINT active_record_2
--- Find the newly-created account
SELECT * FROM credit_accounts WHERE customer_id = 1
--- Save the data
RELEASE SAVEPOINT active_record_2
COMMIT
On line 7 above, the INSERT might fail if the customer account was
already created, and the database unique constraint would prevent a
duplicate entry. Without the first SAVEPOINT and ROLLBACK block, the
whole transaction would have failed. With that subtransaction, the
transaction can retry gracefully and look up the existing account.
What is SubtransControlLock?
As we mentioned earlier, Nessie returned at random times with queries
waiting for SubtransControlLock. SubtransControlLock indicates that
the query is waiting for PostgreSQL to load subtransaction data from
disk into shared memory.
Why is this data needed? When a client runs a SELECT, for example,
PostgreSQL needs to decide whether each version of a row, known as a
tuple, is actually visible within the current transaction. It's possible
that a tuple has been deleted or has yet to be committed by another
transaction. Since only a top-level transaction can actually commit
data, PostgreSQL needs to map a subtransaction ID (subXID) to its parent
XID.
This mapping of subXID to parent XID is stored on disk in the
pg_subtrans directory. Since reading from disk is slow, PostgreSQL
adds a simple least-recently used (SLRU) cache in front for each
backend process. The lookup is fast if the desired page is already
cached. However, as Laurenz Albe discussed in his blog
post,
PostgreSQL may need to read from disk if the number of active
subtransactions exceeds 64 in a given transaction, a condition
PostgreSQL terms suboverflow. Think of it as the feeling you might get
if you ate too many Subway sandwiches.
Suboverflowing (is that a word?) can bog down performance because as
Laurenz said, "Other transactions have to update pg_subtrans to
register subtransactions, and you can see in the perf output how they
vie for lightweight locks with the readers."
Hunting for nested subtransactions
Laurenz's blog post suggested that we might be using too many
subtransactions in one transaction. At first, we suspected we might be
doing this in some of our expensive background jobs, such as project
export or import. However, while we did see numerous SAVEPOINT calls
in these jobs, we didn't see an unusual degree of nesting in local
testing.
To isolate the cause, we started by adding Prometheus metrics to track subtransactions as a Prometheus metric by model. This led to nice graphs as the following:

While this was helpful in seeing the rate of subtransactions over time, we didn't see any obvious spikes that occurred around the time of the database stalls. Still, it was possible that suboverflow was happening.
To see if that was happening, we instrumented our application to track
subtransactions and log a message whenever we detected more than 32
SAVEPOINT calls in a given transaction. Rails
makes it possible for the application to subscribe to all of its SQL
queries via ActiveSupport notifications. Our instrumentation looked
something like this, simplified for the purposes of discussion:
ActiveSupport::Notifications.subscribe('sql.active_record') do |event|
sql = event.payload.dig(:sql).to_s
connection = event.payload[:connection]
manager = connection&.transaction_manager
context = manager.transaction_context
return if context.nil?
if sql.start_with?('BEGIN')
context.set_depth(0)
elsif cmd.start_with?('SAVEPOINT', 'EXCEPTION')
context.increment_savepoints
elsif cmd.start_with?('ROLLBACK TO SAVEPOINT')
context.increment_rollbacks
elsif cmd.start_with?('RELEASE SAVEPOINT')
context.increment_releases
elsif sql.start_with?('COMMIT', 'ROLLBACK')
context.finish_transaction
end
end
This code looks for the key SQL commands that initiate transactions and
subtransactions and increments counters when they occurred. After a
COMMIT, we log a JSON message that contained the backtrace and the
number of SAVEPOINT and RELEASES calls. For example:
{
"sql": "/*application:web,correlation_id:01FEBFH1YTMSFEEHS57FA8C6JX,endpoint_id:POST /api/:version/projects/:id/merge_requests/:merge_request_iid/approve*/ BEGIN",
"savepoints_count": 1,
"savepoint_backtraces": [
[
"app/models/application_record.rb:75:in `block in safe_find_or_create_by'",
"app/models/application_record.rb:75:in `safe_find_or_create_by'",
"app/models/merge_request.rb:1859:in `ensure_metrics'",
"ee/lib/analytics/merge_request_metrics_refresh.rb:11:in `block in execute'",
"ee/lib/analytics/merge_request_metrics_refresh.rb:10:in `each'",
"ee/lib/analytics/merge_request_metrics_refresh.rb:10:in `execute'",
"ee/app/services/ee/merge_requests/approval_service.rb:57:in `calculate_approvals_metrics'",
"ee/app/services/ee/merge_requests/approval_service.rb:45:in `block in create_event'",
"ee/app/services/ee/merge_requests/approval_service.rb:43:in `create_event'",
"app/services/merge_requests/approval_service.rb:13:in `execute'",
"ee/app/services/ee/merge_requests/approval_service.rb:14:in `execute'",
"lib/api/merge_request_approvals.rb:58:in `block (3 levels) in <class:MergeRequestApprovals>'",
]
"rollbacks_count": 0,
"releases_count": 1
}
This log message contains not only the number of subtransactions via
savepoints_count, but it also contains a handy backtrace that
identifies the exact source of the problem. The sql field also
contains Marginalia comments
that we tack onto every SQL query. These comments make it possible to
identify what HTTP request initiated the SQL query.
Taking a hard look at PostgreSQL
The new instrumentation showed that while the application regularly used
subtransactions, it never exceeded 10 nested SAVEPOINT calls.
Meanwhile, Nikolay Samokhvalov, founder of Postgres.ai, performed a battery of tests trying to replicate the problem. He replicated Laurenz's results when a single transaction exceeded 64 subtransactions, but that wasn't happening here.
When the database stalls occurred, we observed a number of patterns:
- Only the replicas were affected; the primary remained unaffected.
- There was a long-running transaction, usually relating to PostgreSQL's autovacuuming, during the time. The stalls stopped quickly after the transaction ended.
Why would this matter? Analyzing the PostgreSQL source code, Senior Support Engineer Catalin Irimie posed an intriguing question that led to a breakthrough in our understanding:
Does this mean that, having subtransactions spanning more than 32 cache pages, concurrently, would trigger the exclusive SubtransControlLock because we still end up reading them from the disk?
Reproducing the problem with replicas
To answer this, Nikolay immediately modified his test to involve replicas and long-running transactions. Within a day, he reproduced the problem:

The image above shows that transaction rates remain steady around 360,000 transactions per second (TPS). Everything was proceeding fine until the long-running transaction started on the primary. Then suddenly the transaction rates plummeted to 50,000 TPS on the replicas. Canceling the long transaction immediately caused the transaction rate to return.
What is going on here?
In his blog post, Nikolay called the problem Subtrans SLRU overflow. In a busy database, it's possible for the size of the subtransaction log to grow so large that the working set no longer fits into memory. This results in a lot of cache misses, which in turn causes a high amount of disk I/O and CPU as PostgreSQL furiously tries to load data from disk to keep up with all the lookups.
As mentioned earlier, the subtransaction cache holds a mapping of the subXID to the parent XID. When PostgreSQL needs to look up the subXID, it calculates in which memory page this ID would live, and then does a linear search to find in the memory page. If the page is not in the cache, it evicts one page and loads the desired one into memory. The diagram below shows the memory layout of the subtransaction SLRU.

By default, each SLRU page is an 8K buffer holding 4-byte parent XIDs. This means 8192/4 = 2048 transaction IDs can be stored in each page.
Note that there may be gaps in each page. PostgreSQL will cache XIDs as needed, so a single XID can occupy an entire page.
There are 32 (NUM_SUBTRANS_BUFFERS) pages, which means up to 65K
transaction IDs can be stored in memory. Nikolay demonstrated that in a
busy system, it took about 18 seconds to fill up all 65K entries. Then
performance dropped off a cliff, making the database replicas unusable.
To our surprise, our experiments also demonstrated that a single
SAVEPOINT during a long-transaction could initiate this problem if
many writes also occurred simultaneously. That
is, it wasn't enough just to reduce the frequency of SAVEPOINT; we had
to eliminate them completely.
Why does a single SAVEPOINT cause problems?
To answer this question, we need to understand what happens when a
SAVEPOINT occurs in one query while a long-running transaction is
running.
We mentioned earlier that PostgreSQL needs to decide whether a given row
is visible to support a feature called multi-version concurrency control, or MVCC for
short. It does this by storing hidden columns, xmin and xmax, in
each tuple.
xmin holds the XID of when the tuple was created, and xmax holds the
XID when it was marked as dead (0 if the row is still present). In
addition, at the beginning of a transaction, PostgreSQL records metadata
in a database snapshot. Among other items, this snapshot records the
oldest XID and the newest XID in its own xmin and xmax values.
This metadata helps PostgreSQL determine whether a tuple is visible.
For example, a committed XID that started before xmin is definitely
visible, while anything after xmax is invisible.
What does this have to do with long transactions?
Long transactions are bad in general because they can tie up
connections, but they can cause a subtly different problem on a
replica. On the replica, a single SAVEPOINT during a long transaction
causes a snapshot to suboverflow. Remember that dragged down performance
in the case where we had more than 64 subtransactions.
Fundamentally, the problem happens because a replica behaves differently from a primary when creating snapshots and checking for tuple visibility. The diagram below illustrates an example with some of the data structures used in PostgreSQL:

On the top of this diagram, we can see the XIDs increase at the
beginning of a subtransaction: the INSERT after the BEGIN gets 1,
and the subsequent INSERT in SAVEPOINT gets 2. Another client comes
along and performs a INSERT and SELECT at XID 3.
On the primary, PostgreSQL stores the transactions in progress in a
shared memory segment. The process array (procarray) stores XID 1 with
the first connection, and the database also writes that information to
the pg_xact directory. XID 2 gets stored in the pg_subtrans
directory, mapped to its parent, XID 1.
If a read happens on the primary, the snapshot generated contains xmin
as 1, and xmax as 3. txip holds a list of transactions in progress,
and subxip holds a list of subtransactions in progress.
However, neither the procarray nor the snapshot are shared directly
with the replica. The replica receives all the data it needs from the
write-ahead log (WAL).
Playing the WAL back one entry at time, the replica populates a shared data
structure called KnownAssignedIds. It contains all the transactions in
progress on the primary. Since this structure can only hold a limited number of
IDs, a busy database with a lot of active subtransactions could easily fill
this buffer. PostgreSQL made a design choice to kick out all subXIDs from this
list and store them in the pg_subtrans directory.
When a snapshot is generated on the replica, notice how txip is
blank. A PostgreSQL replica treats all XIDs as though they are
subtransactions and throws them into the subxip bucket. That works
because if a XID has a parent XID, then it's a subtransaction. Otherwise, it's a normal transaction. The code comments
explain the rationale.
However, this means the snapshot is missing subXIDs, and that could be
bad for MVCC. To deal with that, the replica also updates lastOverflowedXID:
* When we throw away subXIDs from KnownAssignedXids, we need to keep track of
* that, similarly to tracking overflow of a PGPROC's subxids array. We do
* that by remembering the lastOverflowedXID, ie the last thrown-away subXID.
* As long as that is within the range of interesting XIDs, we have to assume
* that subXIDs are missing from snapshots. (Note that subXID overflow occurs
* on primary when 65th subXID arrives, whereas on standby it occurs when 64th
* subXID arrives - that is not an error.)
What is this "range of interesting XIDs"? We can see this in the code below:
if (TransactionIdPrecedesOrEquals(xmin, procArray->lastOverflowedXid))
suboverflowed = true;
If lastOverflowedXid is smaller than our snapshot's xmin, it means
that all subtransactions have completed, so we don't need to check for
subtransactions. However, in our example:
xminis 1 because of the transaction.lastOverflowXidis 2 because of theSAVEPOINT.
This means suboverflowed is set to true here, which tells PostgreSQL
that whenever a XID needs to be checked, check to see if it has a parent
XID. Remember that this causes PostgreSQL to:
- Look up the subXID for the parent XID in the SLRU cache.
- If this doesn't exist in the cache, fetch the data from
pg_trans.
In a busy system, the requested XIDs could span an ever-growing range of
values, which could easily exhaust the 64K entries in the SLRU
cache. This range will continue to grow as long as the transaction runs;
the rate of increase depends on how many updates are happening on the
prmary. As soon as the transaction terminates, the suboverflowed state
gets set to false.
In other words, we've replicated the same conditions as we saw with 64
subtransactions, only with a single SAVEPOINT and a long transaction.
What can we do about getting rid of Nessie?
There are three options:
- Eliminate
SAVEPOINTcalls completely. - Eliminate all long-running transactions.
- Apply Andrey Borodin's patches to PostgreSQL and increase the subtransaction cache.
We chose the first option because most uses of subtransaction could be removed fairly easily. There were a number of approaches we took:
- Perform updates outside of a subtransaction. Examples: 1, 2
- Rewrite a query to use a
INSERTor anUPDATEwith anON CONFLICTclause to deal with duplicate constraint violations. Examples: 1, 2, 3 - Live with a non-atomic
find_or_create_by. We used this approach sparingly. Example: 1
In addition, we added an alert whenever the application used a a single SAVEPOINT:

This had the side benefit of flagging a minor bug.
Why not eliminate all long-running transactions?
In our database, it wasn't practical to eliminate all long-running transactions because we think many of them happened via database autovacuuming, but we're not able to reproduce this yet. We are working on partitioning the tables and sharding the database, but this is a much more time-consuming problem than removing all subtransactions.
What about the PostgreSQL patches?
Although we tested Andrey's PostgreSQL patches, we did not feel comfortable deviating from the official PostgreSQL releases. Plus, maintaining a custom patched release over upgrades would add a significant maintenance burden for our infrastructure team. Our self-managed customers would also not benefit unless they used a patched database.
Andrey's patches do two main things:
- Allow administrators to change the SLRU size to any value.
- Adds an associative cache. to make it performant to use a large cache value.
Remember that the SLRU cache does a linear search for the desired page. That works fine when there are only 32 pages to search, but if you increase the cache size to 100 MB the search becomes much more expensive. The associative cache makes the lookup fast by indexing pages with a bitmask and looking up the entry with offsets from the remaining bits. This mitigates the problem because a transaction would need to be several magnitudes longer to cause a problem.
Nikolay demonstrated that the SAVEPOINT problem disappeared as soon as
we increased the SLRU size to 100 MB with those patches. With a 100 MB
cache, PostgreSQL can cache 26.2 million IDs (104857600/4), far more
than the measely 65K.
These patches are currently awaiting review, but in our opinion they should be given high priority for PostgreSQL 15.
Conclusion
Since removing all SAVEPOINT queries, we have not seen Nessie rear her
head again. If you are running PostgreSQL with read replicas, we
strongly recommend that you also remove all subtransactions until
further notice.
PostgreSQL is a fantastic database, and its well-commented code makes it possible to understand its limitations under different configurations.
We would like to thank the GitLab community for bearing with us while we iron out this production issue.
We are also grateful for the support from Nikolay Samokhvalov and Catalin Irimie, who contributed to understanding where our Loch Ness Monster was hiding.
Cover image by Khadi Ganiev on iStock, licensed under standard license