

At GitLab, we must verify simultaneous changes from the hundreds of people that contribute to GitLab each day. How can we help them contribute efficiently using our pipelines?
The pipelines that we use to build and verify GitLab have more than 90 jobs. Not all of those jobs are equal. Some are simple tasks that take a few seconds to finish, while others are long-running processes that must be optimized carefully.
At the time of this writing, we have more than 700 pipelines running. Each of these pipelines represent changes from team members and contributors from the wider community. All GitLab contributors must wait for the pipelines to finish to make sure the change works and integrates with the rest of the product. We want our pipelines to finish as fast as possible to maintain the productivity of our teams.
This is why we constantly monitor the duration of our pipelines. For example, in December 2020, successful merge request pipelines had a duration of 53.8 minutes:
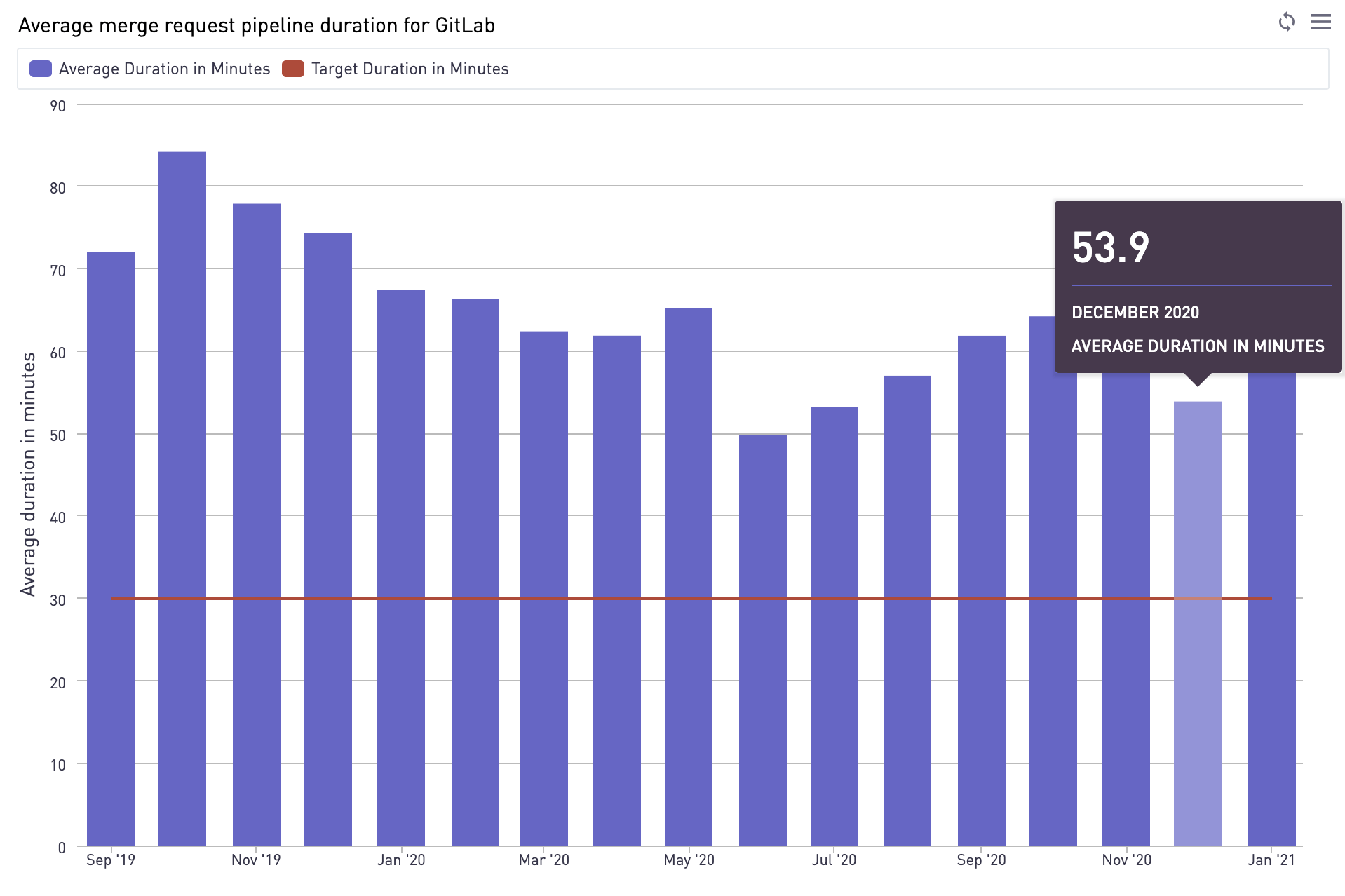 The average pipeline took 53.8 minutes to finish in December.
The average pipeline took 53.8 minutes to finish in December.
Given that we run around 500 merge request pipelines per day, we want to know: Can we optimize our process to change how long-running jobs run?
How we fixed our bottleneck jobs by making them run in parallel
The frontend-fixtures job uses rspec to generate mock data files, which are then saved as files called "fixtures". These files are loaded by our frontend tests, so the frontend-fixtures must finish before any of our frontend tests can start.
As not all of our tests need these frontend fixtures, many jobs use the
needskeyword to start before thefrontend-fixturesjob is done.
In our pipelines, this job looked like this:
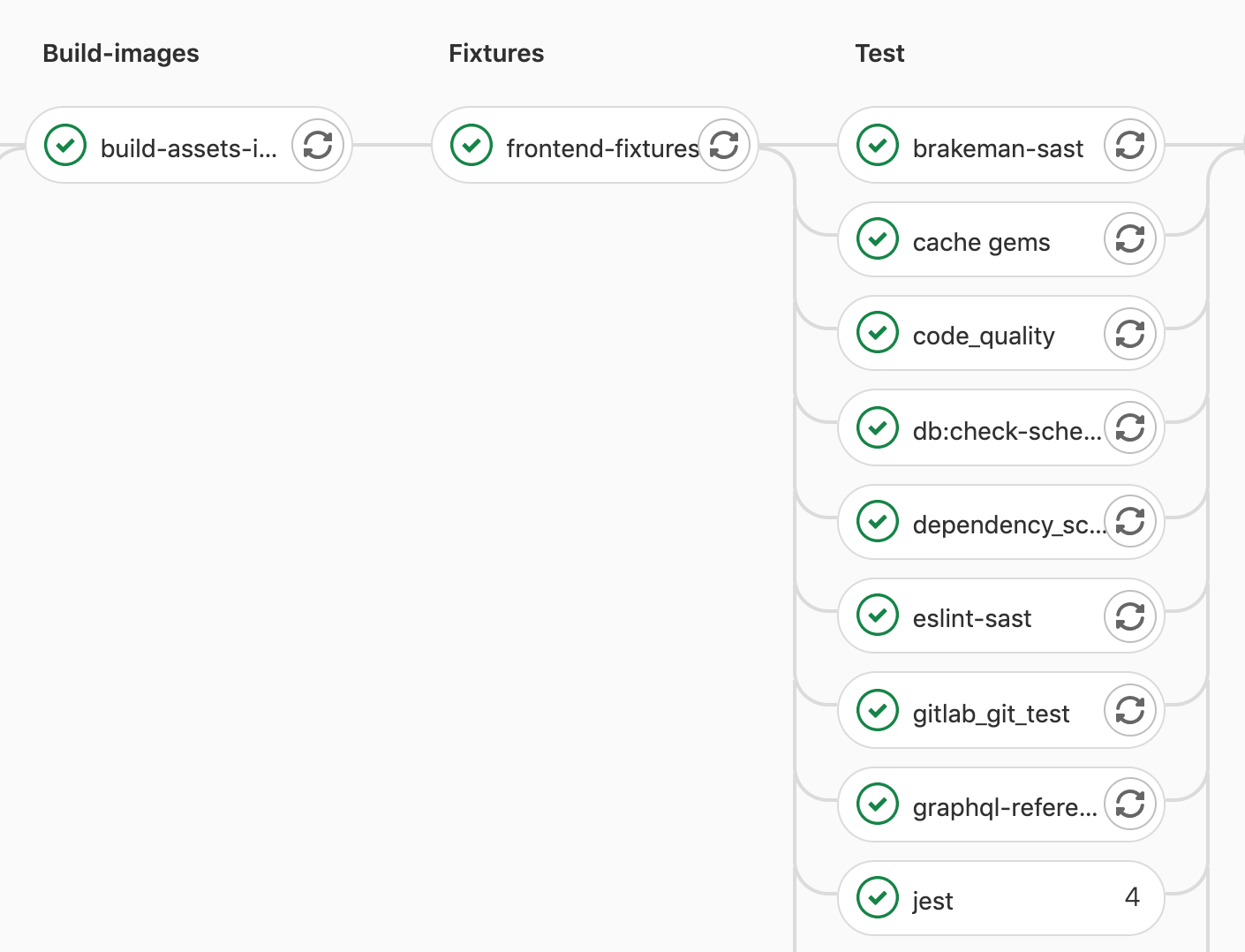 Inside the frontend fixtures job.
Inside the frontend fixtures job.
This job had a normal duration of 20 minutes, and each individual fixture could be generated independently, so we knew there was an opportunity to run this process in parallel.
The next step was to configure our pipeline to split the job into multiple batches that could be run in parallel.
How to make frontend-fixtures a parallel job
Fortunately, GitLab CI provides an easy way to run a job in parallel using the parallel keyword. In the background, this creates "clones" of the same job, so that multiple copies of it can run simultaneously.
Before:
frontend-fixtures:
extends:
- .frontend-fixtures-base
- .frontend:rules:default-frontend-jobs
After:
rspec-ee frontend_fixture:
extends:
- .frontend-fixtures-base
- .frontend:rules:default-frontend-jobs
parallel: 2
You will notice two changes. First, we changed the name of the job, so our job is picked up by Knapsack (more on that later), and then we add the keyword parallel, so the job gets duplicated and runs in parallel.
The new jobs that are generated look like this:
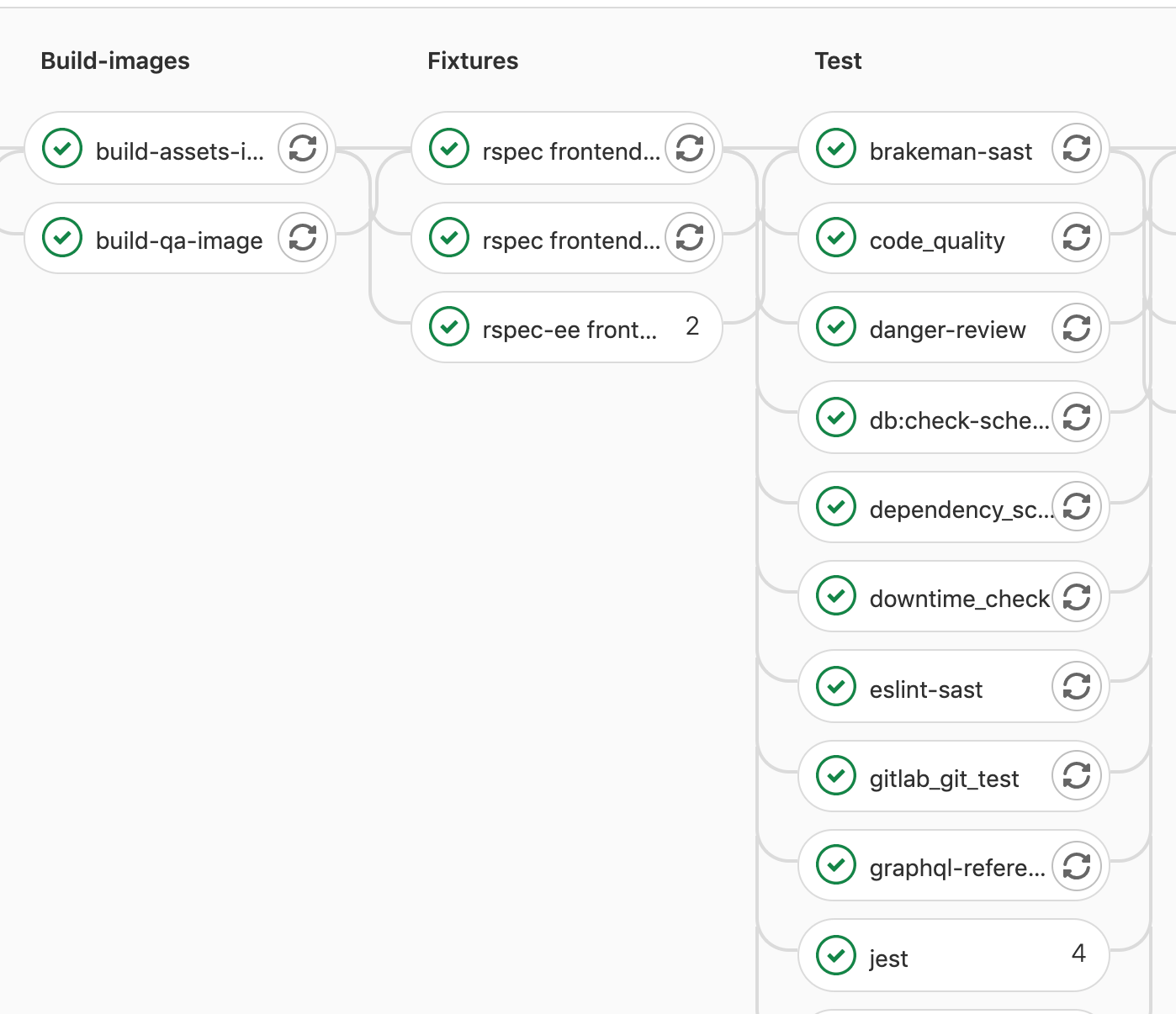 The new jobs that are picked up by Knapsack and run in parallel.
The new jobs that are picked up by Knapsack and run in parallel.
As we used a value of parallel: 2, actually two jobs are generated with the names:
rspec-ee frontend_fixture 1/2rspec-ee frontend_fixture 2/2
Our two "generated" jobs, now take three and 17 minutes respectively, giving us an overall decrease of about three minutes.
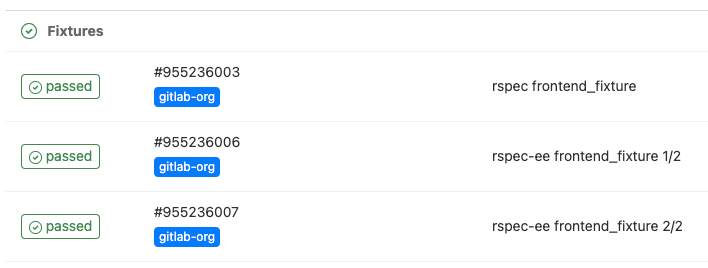 The parallel jobs that are running in the pipeline.
The parallel jobs that are running in the pipeline.
Another way we optimized the process
As we use Knapsack to distribute the test files among the parallel jobs, we were able to make more improvements by reducing the time it takes our longest-running fixtures-generator file to run.
We did this by splitting the file into smaller batches and optimizing it, so we have more tests running in parallel, which shaved off an additional ~3.5 minutes.
Tips for running parallel jobs
If you want to ramp up your productivity you can leverage parallel on your pipelines by following these tips:
- Measure the time your pipelines take to run and identify possible bottlenecks to your jobs. You can do this by checking which jobs are slower than others.
- Once your slow jobs are identified, try to figure out if they can be run independently from each other or in batches.
- Automated tests are usually good candidates, as they tend to be self-contained and run in parallel anyway.
- Add the
parallelkeyword, while measuring the outcome over the next few running pipelines.
Learn more about our solution
We discuss how running jobs in parallel improved the speed of pipelines on GitLab Unfiltered.
And here are links to some of the resources we used to run pipelines in parallel:
- The merge request that introduced
parallelto fixtures. - An important optimization follow-up to make one of the slow tests faster.
- The Knapsack gem, which we leverage to split the tests more evenly in multiple CI nodes.
And many thanks to Rémy Coutable, who helped me implement this improvement.


