
is now in public beta!
Published on: November 16, 2021
8 min read
How GitLab automates engineering management
At GitLab we know automation is engineering's best friend. Here's a deep dive into three scripts we use regularly to keep big projects on track.

As an engineer, figuring out how to automate your work becomes an important aspect of your job. From writing powerful dotfiles, to customizing bash scripts, to writing robust and rigorous tests, engineers regularly look for ways to automate their repetitive work.
At GitLab, engineering managers are no different and are constantly looking for ways to automate their work. I asked engineering managers at GitLab to share their automation scripts and their responses were overflowing.
From automating their 1:1 document creation, to integrating GitLab with Google Sheets, to writing utilities to provide executive summaries, GitLab team members take advantage of the rich API that GitLab provides to organize the mountains of information that they sort through on a regular basis.
For this blog post, I’m sharing a repo that contains just a few of the many scripts that our team members use. These scripts were originally written by engineering manager Rachel Nienaber. Rachel’s Infrastructure team is tasked with the exciting work of coordinating large scale infrastructure and code improvements. The work involves coordinating and sequencing lots of issues and epics, and ensuring the work gets done at just the right time and in the right order. Because of the breadth and scale of the work, she has created a handful of scripts that parse issues and epics in order to gain better visibility into the work that needs to be done.
In the repo, there are three scripts. I’ll provide a quick overview of the first two, and then dive into the code on the last one.
Issues not in epics
Since the Infrastructure team leans on epics to organize their issues, they also want to be able to organize work that may not be part of an epic. The issues_not_in_epics.rb
script iterates through issues not in an epic and updates the description of a single hard-coded issue
with a table summarizing those issues. The script is run on a daily basis via a scheduled pipeline. This ensures that issues do not slip through the cracks.
Epic summary
This script, epic_summary.rb, was written to solve the problem of having to look in multiple places to understand the status of each project. By grouping all status information into one place it’s easy to see what the team is working on, and what projects will be coming up next.
As input it takes a designated epic ID and updates the description of that epic by crawling sub-epics and extracting the following data from those epics:
-
The person responsible for delivering a sub-epic (at GitLab we use the term Directly Responsible Individual or DRI)
-
The latest status update for the epic as inputted by an engineer in an epic description
-
The number of sub-epics
-
Links to a board showing the issues constituting that epic
You can see an example of the output from the script on this epic.
Part of what makes this script simple is that the Infrastructure team always updates the bottom of all their epic descriptions with the following markdown.
## Status {DATE}
{commentary of the status}
By consistently using that very simple markdown, the following snippet of code can reliably extract the status for each epic:
if description!= nil && description.index("## Status")
end_location = description.length
if description.index("mermaid")
end_location = description.index("mermaid")-6
end
status = description[description.index("## Status")+10..end_location]
end
The code above certainly won’t win any algorithm challenges, but that’s kind of the point and what we aim to do with boring solutions.
You’ll notice the code above adjusts what is parsed to exclude a mermaid diagram that might appear after the ## Status markdown. That diagram gets maintained with the epic_issue_relationship.rb
script.
Epic issue relationship
This script updates either a specific epic or all epics, depending on the command line option, with a mermaid diagram that shows the relationship between issues and the order that those issues need to be completed by examining how they are related to one another. Adding a mermaid diagram to the description was introduced by Sean McGivern, a staff engineer on the Scalability team. It creates brilliant diagrams like this one from this epic.
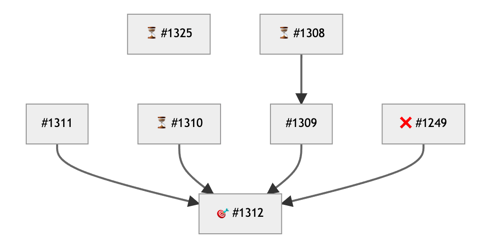
Let’s walk through the code.
The script uses the Docopt gem to parse and accept several input parameters.
options = Docopt::docopt(docstring)
token = options.fetch('--token')
group_id = options.fetch('--groupid')
epic_id = options.fetch('--epicid', nil)
dry_run = options.fetch('--dry-run', false)
Then a connection to the GitLab instance is created, taking advantage of the GitLab gem which is extended in lib/gitlab_client/epics.rb
to include a few extra methods.
Gitlab.configure do |config|
config.endpoint = 'https://gitlab.com/api/v4'
config.private_token = token
end
If an epic id is passed in, then the update_mermaid will run only for a specific epic. Otherwise, the code searches for epics that match the two labels, workflow-infra::In Progress and team::Scalability and are also opened. Only when the matching epics do not have child epics, is update_mermaid run.
if epic_id
update_mermaid(token: token, group_id: group_id, epic_id: epic_id, dry_run: dry_run)
else
Gitlab.epics(group_id, 'workflow-infra::In Progress,team::Scalability', options: { state: 'opened' }).each do |epic|
if Gitlab.epic_epics(epic['group_id'], epic['iid']).count == 0
update_mermaid(token: token, group_id: group_id, epic_id: epic['iid'], dry_run: dry_run)
end
end
end
Finally the most exciting part of the script is the method update_mermaid method.
Below the code sets up variables, and looks to see if a mermaid diagram exists in the epic description that it should populate. Note, that if a mermaid diagram does not exist in the epic already, this script will not create one. Each epic should already have a mermaid diagram placeholder inserted after the status header.
def update_mermaid(token:, group_id:, epic_id:, dry_run:)
in_epic = Set.new
from_relations = Set.new
relations = Set.new
mermaid = ['graph TD']
original_description = Gitlab.epic(group_id, epic_id).description
unless original_description =~ MERMAID_REGEX
puts "#{epic_id} does not have a Mermaid diagram"
return
end
Next the code iterates through each of the issues in the epic and assigns a graph_id for each issue that will be part of the mermaid diagram. It also adds the key_fields to the in_epic Set. The code assigns title along with an emoji so that the mermaid diagram is visually richer. After that the graph nodes are added to the mermaid diagram.
Gitlab.epic_issues(group_id, epic_id).each do |issue|
iid = issue['iid']
graph_id = id(issue)
in_epic << key_fields(issue)
title = "##{iid}"
title = "🎯 #{title}" if issue['labels'].include?('exit criterion')
if issue['state'] == 'closed'
title = "✅ #{title}"
elsif issue['assignees'].any?
title = "⏳ #{title}"
end
mermaid << " #{graph_id}[\"#{title}\"]"
mermaid << " click #{graph_id} \"#{issue['web_url']}\" \"#{issue['title'].gsub('"', "'")}\""
After adding the graph nodes above, the code iterates through the links associated with each issue. The code determines if the issue is blocked by or blocks another issue. Knowing the direction of this relationship defines which direction the arrow in the mermaid diagram should point.
The code also adds both the issue and link to the from_relations set, which will automatically deduplicate entries.
Gitlab.issue_links(issue['project_id'], issue['iid']).each do |link|
case link['link_type']
when 'is_blocked_by'
source = id(link)
destination = graph_id
when 'blocks'
source = graph_id
destination = id(link)
else
next
end
from_relations << key_fields(issue)
from_relations << key_fields(link)
unless relations.include?([source, destination])
mermaid << " #{source} --> #{destination}"
relations << [source, destination]
end
end
Finally, the code looks at the “extra” issues, which are issues that are not directly part of the epic, but are related to issues in the epic. These are the most important issues to ensure are on the diagram, since they represent issue dependencies that are outside the epic and would otherwise not show up when viewing an epic page in GitLab.
The code then updates the epic description by calling the GitLab API and setting the new description.
(from_relations - in_epic).each do |extra_issue|
mermaid << " #{id(extra_issue)}[\"❌ ##{extra_issue['iid']}\"]"
mermaid << " click #{id(extra_issue)} \"#{extra_issue['web_url']}\" \"#{extra_issue['title'].gsub('"', "'")}\""
end
mermaid_string = mermaid.join("\n")
new_description = original_description
.gsub(MERMAID_REGEX,
"\n\\1\n```mermaid\n#{mermaid_string}\n```\n")
Gitlab.edit_epic(group_id, epic_id, description: new_description)
end
The above scripts help engineering managers efficiently know about all the issues their team members are working on, the status of their team’s epics and how all the work fits together.
The scripts only rely on team members doing two things manually:
-
Updating an epic’s status on a periodic basis
-
Creating relationships between related issues.
The scripts can be run as part of a regular scheduled pipeline. With the reports generated on a scheduled basis, engineering managers can regularly get summarized information that helps make them and their teams more productive.