Published on: February 21, 2019
6 min read
GitLab might move to a single Rails codebase
We're considering moving towards a single Rails repository by combining the two existing repositories – here's why, and what would change.


A single repository with no license changes
Before we go into the details of the proposed changes, we want to stress that:
- GitLab Community Edition code would remain open source and MIT licensed.
- GitLab Enterprise Edition code would remain source available and proprietary.
What are the challenges with having two repositories?
Currently the Ruby on Rails code of GitLab (the majority of the codebase) are maintained in two repositories. The gitlab-ce repository for the code with an open source license and the gitlab-ee repository containing code with a proprietary license which is source available.
Feature development is difficult and error prone when making any change at GitLab in two similar yet separate repositories that depend on one another.
Below are a few examples to demonstrate the problem:
Duplicated work during feature development
This frontend only Merge Request required a backport to CE repository. Backporting included creating duplicate work to avoid future conflicts as well as changes to the code to support the feature.
A simple change can break master
A simple change in a spec in CE repository failed the pipeline in the master branch. After hours of investigation, an MR reverting the change was created, as well as a second to address the problem.
Conflicts during preparation for regular releases
This concerns preparation for a regular release, e.g. 11.7.5 release. Merge requests preparing the release for both the CE repository and EE repository need to be created and once the pipelines pass, the EE repository requires a merge from the CE repository. This causes additional conflicts, pipeline failures, and similar delays requiring more manual intervention during which the CE distribution release is also delayed.
Between these three examples, days of engineering time has been spent on busy work, delaying the delivery of work that brings actual value. Only three examples are highlighted, but this type of work occurs daily. Whether writing a new feature available in Core, or any of the enterprise plans, all are equally affected.
More details on the workflows and challenges can be found in the working in CE and EE codebases blueprint document.
What have we done to improve the situation?
We've invested significant development time to try and keep the two repositories separate:
Pre-2016: Manual merges for each release
Prior to 2016, merging the CE repository into the EE repository was done when we were ready to cut a release; the number of commits was small so this could be done by one person.
2016-2017: Daily merges by a team of developers
In 2016, the number of commits between the two repositories grew so the task was divided between seven (brave) developers responsible for merging the code once a day. This worked for a while until delays started happening due to failed specs or difficult merge conflicts.
2017-2018: Automated merges every three hours
At the end of 2017, we merged an MR that allowed the creation of automated MRs between the two repositories, mentioning individuals to resolve conflicts. This task ran every three hours, allowing for a smaller number of commits to be worked on. You can read more about our automated CE to EE merge here.
Present: Further automation with Merge Train
By the end of 2018, the number of changes going into both the CE and EE repositories grew to thousands of commits in some cases, which made the automated MR insufficient. The Merge Train tool was created to automate these workflows further, by automatically rejecting merge conflicts and preferring changes from one repository over the other. The edge cases we've encountered are requiring us to invest additional time in improving the custom tool.
This last attempt turned out to be a bit of a crossroads. Do we invest more development time in improving the custom tooling, knowing that we will never get it 100 percent right, or do we need to take some more drastic measures that are going to save countless hours of development time?
What are we proposing?
One of GitLab's core values is efficiency. As previously mentioned, merging the gitlab-ce Rails repository into the gitlab-ee Rails repository is proving to be inefficient.
The Rails repository is one of many base repositories of which GitLab consists. The gitlab-ce repository is a part of a gitlab-ce distribution package which offers only the Core feature set. Similarly, the gitlab-ee repository is part of a gitlab-ee distribution package which has a larger feature set available. See the image below:
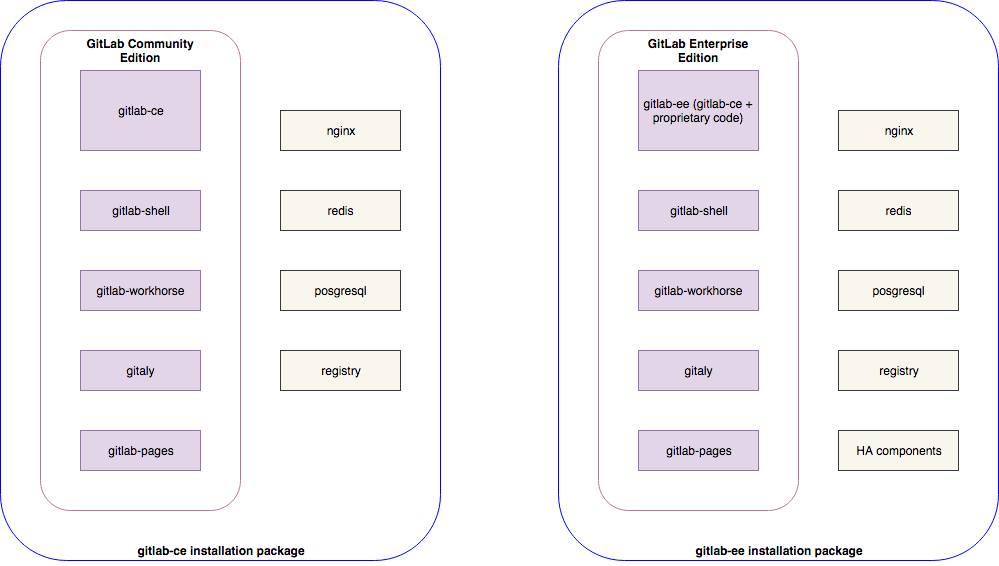
The change we are proposing would merge the gitlab-ce and gitlab-ee repositories into a single gitlab repository. This change is reflected below:
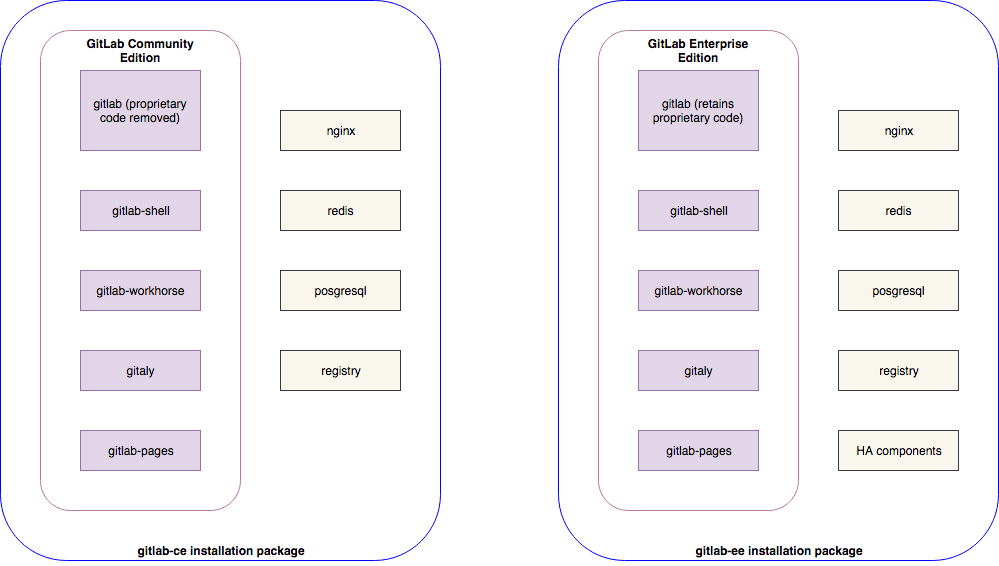
The design for merging two codebases outlines the required work and process changes in detail. The proposed change would pertain only to the Ruby on Rails repository, and I've summarized it below.
So, what changes?
- The gitlab-ce and gitlab-ee repositories are replaced with a single gitlab repository, with all open issues and merge requests moved into the single repository.
- All frontend assets (JavaScript, CSS, images, views) will be open sourced under the MIT license.
- All proprietary backend code is located in the
/eerepository. - All documentation is merged together and clearly states which features belong to which feature set. Documentation is already licensed under CC-BY-SA.
What remains unchanged?
- The gitlab-ce distribution package remains fully open source under the same license.
- All code outside of the
/eedirectory in the single gitlab repository is open source. - All code in the
/eedirectory remains proprietary with source code available. - Other projects, such as gitlab-shell, gitaly, gitlab-workhorse, gitlab-pages, remain unchanged.
What are the possible downsides?
We want to be clear about the possible downsides of this approach:
- Users with installations from source currently cloning the gitlab-ce repository would download from a new repository named gitlab. The clone will also fetch the proprietary code in
/eedirectory, but removing this directory has no effect on running application.
➡️ This is resolved by removing the/eedirectory after cloning. - gitlab-ce distribution users would get more database tables because of the new tables in
db/schema.rb. Database schema is open source and in the gitlab-ce distribution these new tables would not be populated, affect performance, or take significant space.
➡️ All database migration code is open source and does not add additional maintenance burden, so no additional work is required.
What's next?
We currently think that the efficiency gains and clearer naming outweighs these disadvantages. Our stewardship of GitLab is an important aspect of GitLab's success as a whole, so we would love to know:
- Is there a better way to accomplish to solve the problem of the busy work?
- What improvements can we make to our proposal?
- Are there any additional considerations that we should take into account?
We invite you to share your suggestions in issue 2952, which was an inspiration for the proposal as it currently stands. We look forward to hearing your thoughts!
Cover image from Unsplash
More to explore
View all blog posts


We want to hear from you
Enjoyed reading this blog post or have questions or feedback? Share your thoughts by creating a new topic in the GitLab community forum.
Share your feedback