
is now in public beta!
Published on: June 21, 2021
5 min read
How to become more productive with Gitlab CI
Explore some CI/CD strategies that can make your team more efficient and productive.


CI/CD pipelines are the preeminent solution to mitigate potential risks while integrating code changes into the repository. CI/CD pipelines help isolate the impact of potential errors, making it easier to fix them. Top that with a tool that provides effective visibility into the running tasks and there you have a recipe for success.
Since the primary purpose of CI/CD pipelines is to speed up the development process and provide value to the end user faster, there's always room to make the process more efficient. This blog post unpacks some strategies that can help you get the most out of your pipeline definition in GitLab CI.
How Directed Acyclic Graphs (DAG) enable concurrent pipelines
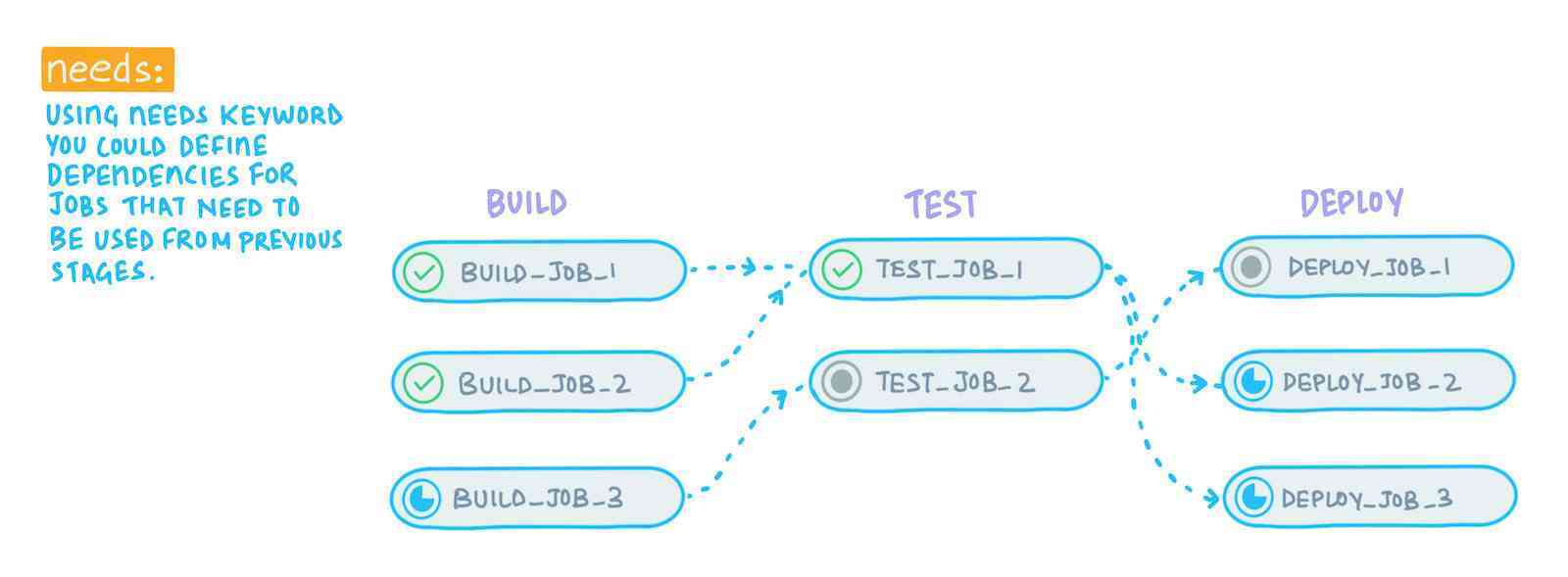 By using the "Needs" keyword you can define dependencies for jobs that need to be used from previous stages.
By using the "Needs" keyword you can define dependencies for jobs that need to be used from previous stages.
In a basic-pipeline structure, all the jobs in a particular stage run concurrently and the jobs in the subsequent stage have to wait on those to finish to get started. This continues for all the stages.
In the image above, the first job in the second stage only depends on the first two job in the first stage to get started. But with the basic pipeline order in place, it has to wait for all three jobs in the first stage to complete before it can start executing, which slows down the overall pipeline considerably. However, by using needs: keywords, you can define a direct dependency for the jobs and they would only have to wait on the job they depend on to get started. By using the DAG strategy, you could shed out a few minutes from the processes for a certain project, thereby increasing the pipeline execution speed and bringing down the CI minutes consumption.
By using needs: [] you can make the job in any stage run immediately, as it doesn't have to wait on any other job to finish.
Why parallel jobs increase productivity
Not all the jobs in a pipeline have an equal run-time. While some may take just a few seconds, some take much longer to finish. When there are many team members waiting on a running pipeline to finish to be able to make a contribution to the project, the productivity of the team takes a hit.
GitLab provides a method to make clones of a job and run them in parallel for faster execution using the parallel: keyword. While parallel jobs may not help in reducing the consumption of CI minutes, they definitely help increase work productivity.
Break down big pipelines with parallel matrix Jobs
Before the release of parallel matrix jobs, in order to run multiple instances of a job with different variable values, the jobs had to be manually defined in the .gitlab-ci-yml like this:
.run-test:
script: run-test $PLATFORM
stage: test
test-win:
extends: .run-test
variables:
- PLATFORM: windows
test-mac:
extends: .run-test
variables:
- PLATFORM: mac
test-linux:
extends: .run-test
variables:
- PLATFORM: linux
Parallel matrix jobs were released with GitLab 13.3 and allow you to create jobs at runtime based on specified variables. Let's say there is a need to run multiple instances a job with different variables values for each instance — with a combination of parallel: and matrix: you accomplish just that.
test:
stage: test
script: run-test $PLATFORM
parallel:
matrix:
- PLATFORM: [windows, mac, linux]
By using parallel: and matrix:, big pipelines can be broken down into manageable parts for efficient maintainance.
Reduce the risk of merge conflicts with parent/child pipelines
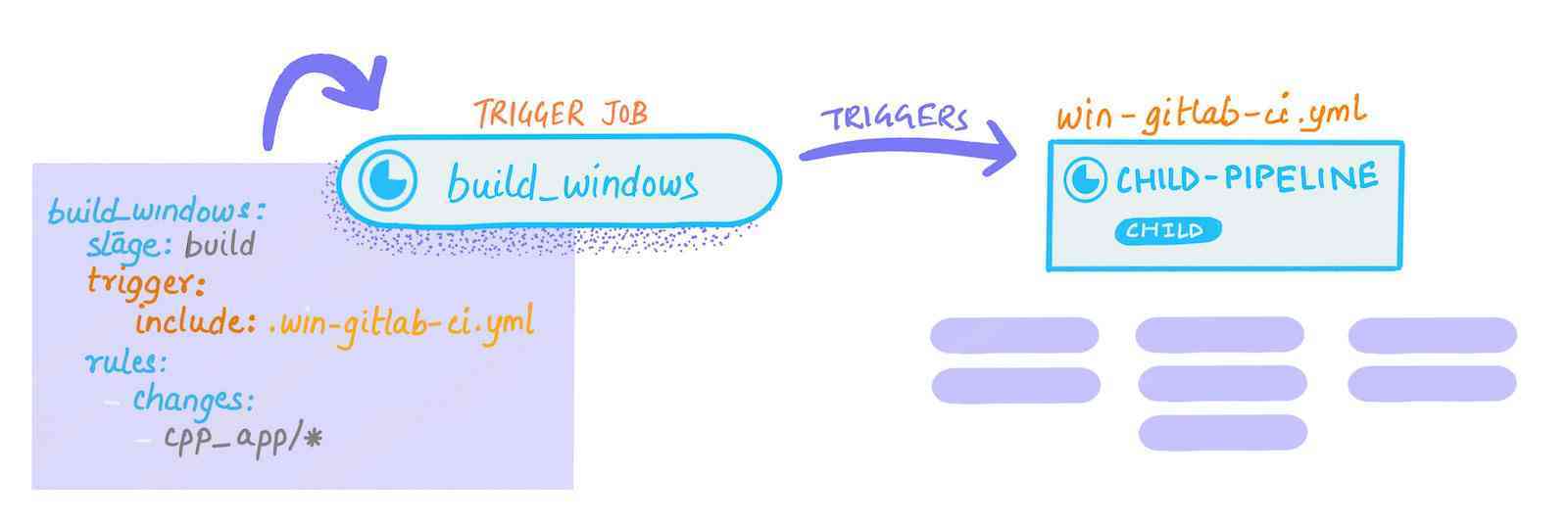 The parent pipeline generates a child pipeline via the trigger:include keywords.
The parent pipeline generates a child pipeline via the trigger:include keywords.
For better management of dependencies, many organizations prefer a mono-repo setup for their projects. But mono-repos have a flip side too. If a repository hosts a large number of projects and a single pipeline definition is used to trigger different automated processes for different components, the pipeline performance is negatively affected. By using parent-child pipelines you can design more efficient pipelines, since you can have multiple child-pipelines that run in parallel. The keyword include: is used to include external YAML files in your CI/CD configuration for this purpose. In the image above a pipeline (the parent) generates a child pipeline via the trigger:include keywords.
This approach also reduces the chances of merge conflicts from happening, as it allows to only edit a section of the pipeline if necessary.
Merge trains help the target branch stay stable
When there's a lot of merge requests flowing into a project, there is a risk of merge conflicts. Merge trains is a powerful feature by GitLab that allows users to automatically merge a series of (queued) merge requests without breaking the target branch. Using this feature, you can add an MR to the train, and it would take care of it until it is merged.
Use multiple caches in the same job
Starting 13.11, GitLab CI/CD provides the ability to configure multiple cache keys in a single job which will help you increase your pipeline performance. This functionality could help you save precious development time when the jobs are running.
How can an efficient pipeline save you money?
By using CI/CD strategies that ensure safe merging of new changes and a green master, organizations can worry less about unanticipated downtimes caused by infrastructural failures and code conflicts.
With faster pipelines, developers end up spending lesser time in maintenance and find time and space to bring in more thoughtfulness and creativity in their work, leading to improvements in code quality and the company atmosphere and morale.
If you are looking to bring down the cost of running your CI/CD pipelines for a large project, look up the Artifact and cache settings and Optimizing GitLab for large repositories sections in the documentation.